

Guide de dépannage général GNU / Linux pour les débutants

- 4825
- 724
- Maxence Arnaud
Dans ce guide, notre objectif est de se renseigner sur les outils et l'environnement fournis par un système GNU / Linux typique pour pouvoir commencer le dépannage même sur une machine inconnue.
Dans ce tutoriel, vous apprendrez:
- Comment vérifier l'espace disque
- Comment vérifier la taille de la mémoire
- Comment vérifier la charge du système
- Comment trouver et tuer les processus système
- Comment utiliser les journaux pour trouver des informations de dépannage système pertinentes
Guide de dépannage général GNU / Linux pour les débutants Exigences et conventions logicielles utilisées
| Catégorie | Exigences, conventions ou version logicielle utilisée |
|---|---|
| Système | Ubuntu 20.04, Fedora 31 |
| Logiciel | N / A |
| Autre | Accès privilégié à votre système Linux en tant que racine ou via le Sudo commande. |
| Conventions | # - Exige que les commandes Linux soient exécutées avec des privilèges racine soit directement en tant qu'utilisateur racine, soit par l'utilisation de Sudo commande$ - Exige que les commandes Linux soient exécutées en tant qu'utilisateur non privilégié régulier |
Introduction
Alors que GNU / Linux est bien connu pour sa stabilité et sa robustesse, il y a des cas où quelque chose peut mal tourner. La source du problème peut être à la fois interne et externe. Par exemple, il peut y avoir un processus défectueux fonctionnant sur le système qui mange des ressources, ou un ancien disque dur peut être défectueux, entraînant des erreurs d'E / S signalées.
Dans tous les cas, nous devons savoir où chercher et quoi faire pour obtenir des informations sur la situation, et ce guide essaie de fournir à peu près cela - une manière générale d'obtenir l'idée qui a mal tourné. La résolution de tout problème commence par connaître le problème, trouver les détails, trouver la cause profonde et la résoudre. Comme pour n'importe quelle tâche, GNU / Linux fournit d'innombrables outils pour aider à la progression, c'est également le dépannage. Les quelques conseils et méthodes suivants ne sont que quelques-uns courants qui peuvent être utilisés sur de nombreuses distributions et versions.
Symptômes
Supposons que nous ayons un bel ordinateur portable sur lequel nous travaillons. Il exécute les derniers Ubuntu, Centos ou Red Hat Linux dessus, avec des mises à jour toujours en place pour garder tout frais. L'ordinateur portable est pour une utilisation générale quotidienne: nous traitons des e-mails, discutons, naviguons sur Internet, pouvons peut-être produire des feuilles de calcul dessus, etc. Rien de spécial n'est installé, une suite de bureaux, un navigateur, un client de messagerie, etc. D'un jour à un autre, soudain, la machine devient extrêmement lente. Nous y travaillons déjà pendant environ une heure, donc ce n'est pas un problème après le démarrage. Ce qui se passe… ?
Vérification des ressources du système
GNU / Linux ne devient pas lent sans raison. Et nous dira très probablement où ça fait mal, tant qu'il est capable de répondre. Comme pour tout programme exécuté sur un ordinateur, le système d'exploitation utilise des ressources système, et avec ceux qui s'exécutent épais, les opérations devront attendre qu'il y en ait assez pour continuer. Cela entraînera en effet des réponses pour devenir de plus en plus lentement, donc s'il y a un problème, il est toujours utile de vérifier l'état des ressources système. En général, nos ressources système (locales) sont constituées de disque, de mémoire et de processeur. Voyons tous.
Espace disque
Si le système d'exploitation en cours d'exécution est hors de l'espace disque, c'est une mauvaise nouvelle. Comme les services en cours d'exécution ne peuvent pas écrire leurs fichiers de journaux, ils se bloqueront principalement en fonctionnement ou ne commenceront pas si les disques sont déjà pleins. Outre les fichiers de journaux, les sockets et les fichiers PID (identifiant de processus) doivent être écrits sur disque, et bien que ceux-ci soient de petite taille, s'il n'y a absolument plus d'espace, ceux-ci ne peuvent pas être créés.
Pour vérifier l'espace disque disponible, nous pouvons utiliser df dans le terminal, et ajouter -H argument, pour voir les résultats arrondi aux mégaoctets et aux gigaoctets. Pour nous, les entrées d'intérêt seraient des volumes qui ont des% de 100%. Cela signifierait que le volume en question est plein. L'exemple de sortie suivant montre que nous allons bien concernant l'espace disque:
$ df -h Taille du système de fichiers utilisé disponible Utiliser% monté sur devtmpfs 1.8g 0 1.8G 0% / DEV TMPFS 1.8g 0 1.8g 0% / dev / shm tmpfs 1.8g 1.3m 1.8g 1% / run / dev / mapper / lv-root 49g 11g 36g 24% / tmpfs 1.8g 0 1.8G 0% / TMP / DEV / SDA2 976M 261M 649M 29% / BOOT / DEV / MAPTER / LV-HOME 173G 18G 147G 11% / HOME TMPFS 361M 4.0k 361m 1% / run / utilisateur / 1000Nous avons donc de l'espace sur les disques (s). Notez que dans notre cas de l'ordinateur portable lent, l'épuisement de l'espace disque ne sera probablement pas la cause profonde. Lorsque les disques sont pleins, les programmes s'écraseront ou ne commenceront pas du tout. Dans un cas extrême, même la connexion échouera après le démarrage.
Mémoire
La mémoire est également une ressource vitale, et si nous ne le sommes pas, le système d'exploitation peut avoir besoin d'en écrire des pièces actuellement inutilisées sur le disque temporaire (également appelé «échanger») pour donner la mémoire libérée au processus suivant, puis lire Il est de retour lorsque le processus qui possède le contenu échangé en a à nouveau besoin. Toute cette méthode appelée échange, et ralentira en effet le système, car l'écriture et la lecture vers et depuis les disques sont beaucoup plus lentes que de travailler dans le RAM.
Pour vérifier l'utilisation de la mémoire, nous avons la pratique gratuit commande que nous pouvons ajouter avec des arguments pour voir les résultats dans les mégaoctets (-m) ou les gigaoctets (-g):
$ GRATUIT -M TOTAL USET USET FREE PARTAGE FRAITDans l'exemple ci-dessus, nous avons 8 Go de mémoire, 1,5 Go de celui-ci libre et environ 3 Go en caches. Le gratuit la commande fournit également l'état du échanger: Dans ce cas, il est parfaitement vide, ce qui signifie que le système d'exploitation n'avait pas besoin d'écrire de contenu mémoire sur disque depuis le démarrage, pas même sur les charges de pointe. Cela signifie généralement que nous avons plus de mémoire que nous utilisons réellement. Donc, en ce qui concerne la mémoire, nous sommes plus que bons, nous en avons beaucoup.
Charge du système
Comme les processeurs effectuent les calculs réels, le temps de calcul du processeur peut entraîner à nouveau le ralentissement du système. Les calculs nécessaires doivent attendre que tout processeur ait le temps libre pour les calculer. La façon la plus simple de voir la charge sur nos processeurs est le durée de la baisse commande:
$ Up-temps 12:18:24 Up 4:19, 8 utilisateurs, moyenne de chargement: 4,33, 2,28, 1,37Les trois nombres après la moyenne de charge signifie la moyenne au cours des 1, 5 et 15 dernières minutes. Dans cet exemple, la machine a 4 cœurs CPU, nous essayons donc d'utiliser plus que notre capacité réelle. Notez également que les valeurs historiques montrent que la charge augmente considérablement au cours des dernières minutes. Peut-être que nous avons trouvé le coupable?
Top processus de consommation
Voyons l'ensemble de l'image du processeur et de la consommation de mémoire, avec les principaux processus utilisant ces ressources. Nous pouvons exécuter le haut Commande pour voir le chargement du système en temps réel (proche):
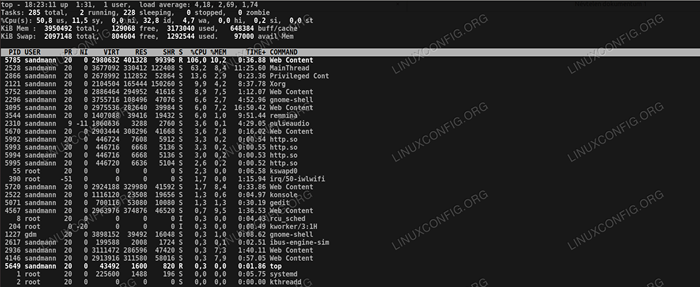 Vérifier les meilleurs processus de consommation.
Vérifier les meilleurs processus de consommation. La première ligne de haut est identique à la sortie de durée de la baisse, Ensuite, nous pouvons voir le nombre si les tâches fonctionnent, dorment, etc. Remarquez le nombre de processus zombies (détestables); Ce cas est 0, mais s'il y aurait des processus à l'état zombie, ils devraient être étudiés. La ligne suivante montre la charge sur les CPU en pourcentage et les pourcentages accumulés de exactement quoi Les processeurs sont occupés avec. Ici, nous pouvons voir que les processeurs sont occupés à servir les programmes d'espace utilisateur.
Viennent ensuite deux lignes qui peuvent être familières à partir du gratuit sortie, utilisation de la mémoire si le système. Ci-dessous, les meilleurs processus, triés par utilisation du processeur. Maintenant, nous pouvons voir ce qui mange nos processeurs, c'est Firefox dans notre cas.
Vérification des processus
Comment puis-je savoir que, puisque le processus consommateur le plus élevé est affiché comme un «contenu Web» dans mon haut sortir? En utilisant ps Pour interroger la table de processus, en utilisant le PID indiqué à côté du processus supérieur, qui est dans ce cas 5785:
$ ps -ef | Grep 5785 | grep -v "grep" sandmann 5785 2528 19 18:18 tty2 00:00:54 /usr/lib/firefox/firefox -contentproc -childID 13 -isForBrowser -prefsLen 9825 -prefMapSize 226230 -parentBuildID 20200720193547 -appdir /usr/lib/ Firefox / Browser 2528 True Tab
Avec cette étape, nous avons trouvé la cause profonde de notre situation. Firefox mange notre temps de processeur au point que notre système commence à répondre à nos actions plus lentement. Ce n'est pas nécessairement la faute du navigateur,
Parce que Firefox est conçu pour afficher les pages du World Wide Web: pour créer un problème de CPU à des fins de démonstration, tout ce que j'ai fait, c'est ouvrir quelques dizaines d'instances d'une page de test de stress dans des onglets distincts du navigateur au point de pénurie du processeur surfaces. Je n'ai donc pas besoin de blâmer mon navigateur, mais moi-même pour ouvrir des pages avides de ressources et les laisser fonctionner en parallèle. En fermant certains, mon processeur
L'utilisation revient à la normale.
Détruire les processus
Le problème et la solution sont découverts ci-dessus, mais que se passe-t-il si je ne peux pas accéder au navigateur pour fermer certains onglets? Disons que ma session graphique est verrouillée et que je ne peux pas me connecter, ou un général
Le processus qui est devenu sauvage n'a même pas d'interface où nous pouvons changer son comportement? Dans un tel cas, nous pouvons émettre l'arrêt du processus par le système d'exploitation. Nous connaissons déjà le pid du
processus voyou avec lequel nous avons obtenu ps, Et nous pouvons utiliser le tuer commande pour l'arrêter:
$ tuer 5785
Les processus bien réconfortants sortiront, certains peuvent ne pas. Si c'est le cas, ajoutant le -9 Le drapeau obligera la résiliation du processus:
$ kill -9 5785
Notez cependant que cela peut entraîner une perte de données, car le processus n'a pas le temps de fermer les fichiers ouverts ou de terminer la rédaction de ses résultats pour disk. Mais en cas d'une tâche reproductible, la stabilité du système peut avoir la priorité sur la perte de certains de nos résultats.
Trouver des informations connexes
Interagir avec les processus avec une sorte d'interface n'est pas toujours le cas, et de nombreuses applications n'ont que des commandes de base qui contrôlent leur comportement - à savoir, démarrer, arrêter, recharger, etc., car leur travail interne est fourni par leur configuration. L'exemple ci-dessus était davantage un bureau, voyons un exemple côté serveur, où nous avons un problème avec un serveur Web.
Supposons que nous ayons un serveur Web qui sert du contenu au monde. C'est populaire, donc ce n'est pas une bonne nouvelle lorsque nous recevons un appel que notre service n'est pas disponible. Nous pouvons vérifier la page Web dans un navigateur uniquement pour obtenir un message d'erreur disant «Impossible de se connecter». Voyons la machine qui exécute le serveur Web!
Vérification des fichiers de journaux
Notre machine hébergeant le serveur Web est une boîte Fedora. Ceci est important en raison des chemins de système de fichiers que nous devons suivre. Fedora, et toutes les autres variantes de chapeau rouge stockent les fichiers de journaux du serveur Web Apache sur le chemin / var / log / httpd. Ici, nous pouvons vérifier le error_log en utilisant voir, Mais ne trouvez aucune information connexe sur ce que pourrait être le problème. La vérification des journaux d'accès ne montre également aucun problème à première vue, mais réfléchir à deux fois nous donnera un indice: sur un serveur Web avec un trafic suffisamment bon, les dernières entrées du journal d'accès devraient être très récentes, mais la dernière entrée est déjà une heure. Nous savons par expérience que le site Web obtient des visiteurs à chaque minute.
Systemd
Notre installation Fedora utilise systemd comme système init. Interrogeons pour quelques informations sur le serveur Web:
# Statut SystemCTL Httpd ● Httpd.Service - Le serveur HTTP Apache chargé: chargé (/ usr / lib / systemd / system / httpd.service; désactivé; Vendor Preset: Désactivé) Drop-in: / USR / LIB / Systemd / System / Httpd.service.D └fiquesphp-fpm.Conf actif: Échec (résultat: signal) depuis Sun 2020-08-02 19:03:21 CEST; 3min 5s Ago Docs: Homme: Httpd.Service (8) Processus: 29457 execStart = / usr / sbin / httpd $ options -dforeground (code = tué, signal = kill) Pid principal: 29457 (code = tué, signal = kill) Statut: "Total demandes: 0; inactif / Travailleurs occupés 100/0; demandes / sec: 0; octets servis / sec: 0 b / sec "CPU: 74ms août 02 19:03:21 MyWebserver1.Foobar Systemd [1]: httpd.Service: le processus de mise à mort 29665 (N / A) avec Signal Sigkill. 02 août 19:03:21 mywebserver1.Foobar Systemd [1]: httpd.Service: Killing Process 29666 (N / A) avec Signal Sigkill. 02 août 19:03:21 mywebserver1.Foobar Systemd [1]: httpd.Service: Killing Process 29667 (N / A) avec Signal Sigkill. 02 août 19:03:21 mywebserver1.Foobar Systemd [1]: httpd.Service: le processus de mise à mort 29668 (N / A) avec Signal Sigkill. 02 août 19:03:21 mywebserver1.Foobar Systemd [1]: httpd.Service: Killing Process 29669 (N / A) avec Signal Sigkill. 02 août 19:03:21 mywebserver1.Foobar Systemd [1]: httpd.Service: Killing Process 29670 (N / A) avec Signal Sigkill. 02 août 19:03:21 mywebserver1.Foobar Systemd [1]: httpd.Service: Killing Process 29671 (N / A) avec Signal Sigkill. 02 août 19:03:21 mywebserver1.Foobar Systemd [1]: httpd.Service: Killing Process 29672 (N / A) avec Signal Sigkill. 02 août 19:03:21 mywebserver1.Foobar Systemd [1]: httpd.Service: Killing Process 29673 (N / A) avec Signal Sigkill. 02 août 19:03:21 mywebserver1.Foobar Systemd [1]: httpd.Service: Échec avec le résultat «signal».L'exemple ci-dessus est à nouveau simple, le httpd processus principal en baisse car il a reçu un signal de mise à mort. Il peut y avoir un autre système qui a le privilège de le faire, afin que nous puissions vérifier qui est
connecté (ou était à l'époque de la fermeture énergique du serveur Web) et lui demandez le problème (un arrêt de service sophistiqué aurait été moins brutal, donc il doit y avoir une raison derrière cela
événement). Si nous sommes les seuls administrateurs du serveur, nous pouvons vérifier d'où vient ce signal - nous pouvons avoir un problème de violation, ou le système d'exploitation a envoyé le signal de mise à mort. Dans les deux cas, nous pouvons utiliser le
Les fichiers de journaux du serveur, car ssh Les connexions sont enregistrées aux journaux de sécurité (/ var / log / sécurisé dans le cas de Fedora), et il y a également des entrées d'audit dans le journal principal (qui est/ var / log / messages dans ce cas). Il y a une entrée qui nous dit ce qui s'est passé dans ce dernier:
2 août 19:03:21 mywebserver1.FOOBAR Audit [1]: service_stop pid = 1 uid = 0 auid = 4294967295 sess = 4294967295 msg = "unit = httpd comm =" systemd "exe =" / usr / lib / systemd / systemd "hostname =? addr =? terminal =? res = échoué "
Conclusion
À des fins de démonstration, j'ai tué le processus principal de mon propre serveur de laboratoire dans cet exemple. Dans un problème lié au serveur, la meilleure aide que nous puissions obtenir rapidement est de vérifier les fichiers de journaux et d'interroger le système pour les processus en cours d'exécution (ou leur absence), et la vérification de leur état signalé, pour se rapprocher du problème. Pour ce faire efficacement, nous devons connaître les services que nous exécutons: où écrivent-ils leurs fichiers de journaux, comment
Nous pouvons obtenir des informations sur leur état, et savoir ce qui est enregistré aux temps de fonctionnement normaux aide également à identifier un problème - peut-être même avant que le service lui-même ne rencontre des problèmes.
Il existe de nombreux outils qui nous aident à automatiser la plupart de ces choses, comme un sous-système de surveillance et des solutions d'agrégation de journaux, mais tout cela commence par nous, les administrateurs qui savent comment les services que nous dirigeons
travail, où et ce qu'il faut vérifier pour savoir s'ils sont en bonne santé. Les outils simples démontrés ci-dessus sont accessibles dans toute distribution, et avec leur aide, nous pouvons aider à résoudre les problèmes avec les systèmes que nous ne sommes pas
Même familier avec. C'est un niveau avancé de dépannage, mais les outils et leur utilisation montrés ici sont quelques-unes des briques que l'on peut utiliser pour commencer à développer ses compétences de dépannage sur GNU / Linux.
Tutoriels Linux connexes:
- Choses à installer sur Ubuntu 20.04
- Choses à faire après l'installation d'Ubuntu 20.04 Focal Fossa Linux
- Une introduction à l'automatisation Linux, des outils et des techniques
- Téléchargement Linux
- Choses à faire après l'installation d'Ubuntu 22.04 Jammy Jellyfish…
- Liste des meilleurs outils Kali Linux pour les tests de pénétration et…
- Installez Arch Linux dans VMware Workstation
- Meilleure distribution Linux pour les développeurs
- Fichiers de configuration Linux: 30 premiers
- Commandes Linux: les 20 meilleures commandes les plus importantes que vous devez…
- « Ubuntu de base 20.04 Configuration de la connexion client / serveur OpenVPN
- Installation de Sugarcrm CE sur Debian 7 Wheezy Linux »