

Comment créer une veille chaude avec PostgreSQL
- 4895
- 404
- Emilie Colin
Objectif
Notre objectif est de créer une copie d'une base de données PostgreSQL qui se synchronise constamment avec l'original et accepte les requêtes en lecture seule.
Système d'exploitation et versions logicielles
- Système d'exploitation: Red Hat Enterprise Linux 7.5
- Logiciel: PostgreSQL Server 9.2
Exigences
Accès privilégié aux systèmes maître et esclaves
Conventions
- # - Exige que les commandes Linux soient exécutées avec des privilèges racine soit directement en tant qu'utilisateur racine, soit par l'utilisation de
Sudocommande - $ - Étant donné les commandes Linux à exécuter en tant qu'utilisateur non privilégié régulier
Introduction
PostgreSQL est un SGBDR open source (système de gestion des bases de données relationnel), et avec toutes les bases de données, le besoin peut survenir pour évoluer et fournir HA (haute disponibilité). Un seul système fournissant un service est toujours un seul point de défaillance possible - et même avec des systèmes virtuels, il peut y avoir un moment où vous ne pouvez pas ajouter plus de ressources à une seule machine pour faire face à la charge toujours croissante. Il peut également être nécessaire d'une autre copie du contenu de la base de données qui peut être interrogée pour l'analyse de longue date, qui ne convient pas à être exécutée dans la base de données de production à forte intensité de transaction. Cette copie pourrait être une simple restauration de la sauvegarde la plus récente sur une autre machine, mais les données seraient obsolètes dès qu'elle sera restaurée.
En créant une copie de la base de données qui reproduit constamment son contenu avec l'original (appelé maître ou primaire), mais ce faisant, acceptez et renvoyez les résultats en lecture seule, nous pouvons créer un pose chaude qui ont étroitement le même contenu.
En cas de défaillance sur Master, la base de données de secours (ou d'esclaves) peut reprendre le rôle de la primaire, arrêter la synchronisation et accepter les demandes de lecture et d'écriture, afin que les opérations puissent se dérouler et le maître défaillant peut être renvoyé à vie (peut-être en veille en changeant la voie de la synchronisation). Lorsque le primaire et la veille sont en cours d'exécution, les requêtes qui ne tentent pas de modifier le contenu de la base de données peuvent être déchargées en veille, de sorte que le système global sera en mesure de gérer une charge plus importante. Remarque cependant, il y aura un certain retard - le standby sera derrière le maître, à la quantité du temps nécessaire pour synchroniser les modifications. Ce retard peut se méfier en fonction de la configuration.
Il existe de nombreuses façons de créer une synchronisation maître-esclave (ou même maître-maître) avec PostgreSQL, mais dans ce tutoriel, nous allons configurer la réplication de streaming, en utilisant le dernier serveur PostgreSQL disponible dans les référentiels Red Hat. Le même processus s'applique généralement aux autres distributions et versions RDMB.
Installation du logiciel requis
Installons postgresql avec Miam aux deux systèmes:
Yum install postgresql-server
Après une installation réussie, nous devons initialiser les deux clusters de base de données:
# PostgreSQL-SETUP InitDB Base de données d'initialisation… . D'ACCORD Pour fournir un démarrage automatique pour les bases de données sur le démarrage, nous pouvons activer le service en systemd:
SystemCTL Activer PostgreSQL
Nous utiliserons dix.dix.dix.100 comme le primaire, et dix.dix.dix.101 Comme l'adresse IP de la machine de secours.
Configurer le maître
C'est généralement une bonne idée de sauvegarder tous les fichiers de configuration avant d'apporter des modifications. Ils ne prennent pas d'espace qui mérite d'être mentionné, et si quelque chose ne va pas, la sauvegarde d'un fichier de configuration de travail peut être une bouée de sauvetage.
Nous devons modifier le pg_hba.confli avec un éditeur de fichiers texte comme vi ou nano. Nous devons ajouter une règle qui permettra à l'utilisateur de la base de données de la veille pour accéder au primaire. Il s'agit du paramètre côté serveur, l'utilisateur n'existe pas encore dans la base de données. Vous pouvez trouver des exemples à la fin du fichier commenté qui sont liés au réplication base de données:
# Autoriser les connexions de réplication de LocalHost, par un utilisateur avec le privilège de réplication #. #local réplication postgres pair #Host Replication Postgres 127.0.0.1/32 Identifier #host Replication Postgres :: 1/128 identi
Ajoutons une autre ligne à la fin du fichier et marquons-la avec un commentaire afin qu'il puisse être facilement vu ce qui est modifié par rapport aux valeurs par défaut:
## MyConf: réplication de la réplication de l'hôte 10.dix.dix.101/32 MD5
Sur les saveurs du chapeau rouge, le fichier est situé par défaut sous le / var / lib / pgsql / data / annuaire.
Nous devons également apporter des modifications au fichier de configuration principal du serveur de base de données, postgresql.confli, qui est situé dans le même répertoire que nous avons trouvé le pg_hba.confli.
Trouvez les paramètres trouvés dans le tableau ci-dessous et modifiez-les comme suit:
| Section | Paramètres par défaut | Paramètre modifié |
|---|---|---|
| Connexions et authentification | #Listen_Address = 'localhost' | écouter_address = '*' |
| Écrivez le journal à l'avance | #wal_level = minimal | wal_level = 'hot_standby' |
| Écrivez le journal à l'avance | #Archive_Mode = OFF | archive_mode = on |
| Écrivez le journal à l'avance | #archive_command = ” | archive_command = 'true' |
| Réplication | #max_wal_senders = 0 | max_wal_senders = 3 |
| Réplication | #hot_standby = off | hot_standby = on |
Notez que les paramètres ci-dessus sont commentés par défaut; Vous avez besoin de non-comment et changer leurs valeurs.
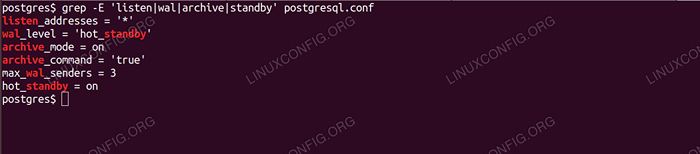
Tu peux grep les valeurs modifiées pour la vérification. Vous devriez obtenir quelque chose comme ce qui suit:
Vérification des changements avec Grep Maintenant que les paramètres sont corrects, démarrons le serveur principal:
# SystemCTL Start PostgreSQL
Et utilise PSQL Pour créer l'utilisateur de la base de données qui gérera la réplication:
# su - Postgres -Bash-4.2 $ psql psql (9.2.23) Tapez "Aide" pour obtenir de l'aide. Postgres = # Créer un mot de passe de connexion utilisateur Mot de passe chiffré 'SecretPassword' limite de connexion -1; Créer un rôle
Prenez note du mot de passe que vous donnez au repuser, Nous en aurons besoin en veille.
Configurer l'esclave
Nous avons quitté la veille avec le initdb marcher. Nous travaillerons comme le postgres L'utilisateur, qui est superutilisateur dans le contexte de la base de données. Nous aurons besoin d'une copie initiale de la base de données principale, et nous obtiendrons cela avec pg_basebackup commande. Nous effuyons d'abord le répertoire de données en veille (créez une copie au préalable si vous le souhaitez, mais ce n'est qu'une base de données vide):
$ rm -rf / var / lib / pgsql / data / *
Maintenant, nous sommes prêts à faire une copie cohérente du primaire en veille:
$ pg_basebackup -h 10.dix.dix.100 -U Repuser -d / var / lib / pgsql / data / mot de passe: avis: pg_stop_backup complet, tous les segments wal requis ont été archivés Nous devons spécifier l'adresse IP du maître après -H et l'utilisateur que nous avons créé pour la réplication, dans ce cas repuser. Comme le primaire est vide en plus de cet utilisateur que nous avons créé, le pg_basebackup devrait se terminer en quelques secondes (selon la bande passante du réseau). Si quelque chose ne va pas, vérifiez la règle HBA sur le primaire, l'exactitude de l'adresse IP donnée au pg_basebackup commande, et ce port 5432 sur primaire est accessible en standby (par exemple, avec telnet).
Lorsque la sauvegarde se termine, vous remarquerez que le répertoire de données est rempli sur l'esclave, y compris les fichiers de configuration (rappelez-vous, nous avons tout supprimé de ce répertoire):
# ls / var / lib / pgsql / data / backup_label.Old PG_CLOG PG_LOG PG_SERIAL PG_SUBTRANS PG_VERSION POST MASTER.Opts Base PG_HBA.Conf PG_Multixact PG_SNAPSHOTS PG_TBLSPC PG_XLOG POST MASTER.PID Global PG_IDENT.conf pg_notify pg_stat_tmp pg_twophase postgresql.Récupération de Conf.confli Nous devons maintenant faire quelques ajustements à la configuration de la veille. L'adresse IP rendue pour le repuseuse de se connecter à partir de nécessiter d'être l'adresse du serveur maître dans pg_hba.confli:
# tail -n2 / var / lib / pgsql / data / pg_hba.Conf ## MyConf: réplication de la réplication de la réplication de l'hôte 10.dix.dix.100/32 MD5 Les changements dans le postgresql.confli sont les mêmes que sur le maître, car nous avons également copié ce fichier avec la sauvegarde. De cette façon, les deux systèmes peuvent jouer le rôle de maître ou de veille concernant ces fichiers de configuration.
Dans le même répertoire, nous devons créer un fichier texte appelé récupération.confli, et ajouter les paramètres suivants:
# Cat / var / lib / pgsql / data / recouvre.conf dequby_mode = 'on' primaire_conninfo = 'host = 10.dix.dix.100 port = 5432 User = Repuser Password = SecretPassword 'Trigger_file =' / var / lib / pgsql / déclencheur_file ' Notez que pour le primaire_conninfo paramètre Nous avons utilisé l'adresse IP du primaire Et le mot de passe que nous avons donné repuser Dans la base de données maîtresse. Le fichier déclencheur pourrait pratiquement être lisible par le postgres Utilisateur du système d'exploitation, avec tout nom de fichier valide - lors de l'événement de crash primaire, le fichier peut être créé (avec touche par exemple) qui déclenchera le basculement en veille, ce qui signifie que la base de données commence à accepter également les opérations d'écriture.
Si ce fichier récupération.confli est présent, le serveur entrera en mode de récupération au démarrage. Nous avons tout en place, afin que nous puissions démarrer la veille et voir si tout fonctionne comme il se doit:
# SystemCTL Start PostgreSQL
Cela devrait prendre un peu plus de temps que d'habitude pour récupérer l'invite. La raison en est que la base de données effectue la récupération à un état cohérent en arrière-plan. Vous pouvez voir les progrès dans le fichier de journal principal de la base de données (votre nom de fichier différera en fonction du jour de la semaine):
$ tailf / var / lib / pgsql / data / pg_log / postgresql-thu.Journal du journal: entrée en mode de veille Journal: la réplication du streaming a été connectée avec succès au journal principal: Remo commence à 0/3000020 Journal: État de récupération cohérent atteint à 0/30000e0 Journal: le système de base de données est prêt à accepter uniquement les connexions en lecture Vérification de la configuration
Maintenant que les deux bases de données sont opérationnelles, testons la configuration en créant certains objets sur primaire. Si tout se passe bien, ces objets devraient éventuellement apparaître en veille.
Nous pouvons créer des objets simples sur primaire (que mon look familier) avec PSQL. Nous pouvons créer le script SQL simple ci-dessous appelé goûter.SQL:
-- Créer une séquence qui servira de PK de la table des employés Créer des employés de séquence_seq Démarrer avec 1 incrément de 1 no maxvalue minvalue 1 cache 1; - Créer la table des employés Créer des employés de table (EMP_ID Numeric Primary Key DefaultVal ('Employés_Seq' :: RegClass), First_name Text Not Null, Last_name Not Null, Birth_year Numeric Not Null, Birth_Month Numeric Not Null, Birth_DayofMonth Numeric Not Null) ; - Insérez certaines données dans la table Insérer dans les employés (First_name, Last_name, Birth_year, Birth_Month, Birth_dayofmonth) («Emily», «James», 1983,03,20); Insérer dans les employés (First_name, Last_name, Birth_year, Birth_Month, Birth_dayofmonth) ('John', 'Smith', 1990,08,12); C'est une bonne pratique de maintenir les modifications de la structure de la base de données dans les scripts (éventuellement poussés dans un référentiel de code), pour référence ultérieure. Est payant lorsque vous avez besoin de savoir ce que vous avez modifié et quand. Nous pouvons maintenant charger le script dans la base de données:
$ psql < sample.sql CREATE SEQUENCE NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "employees_pkey" for table "employees" CREATE TABLE INSERT 0 1 INSERT 0 1 Et nous pouvons interroger pour le tableau que nous avons créé, avec les deux enregistrements insérés:
Postgres = # select * parmi les employés; EMP_ID | First_name | Last_name | Birth_year | Birth_month | naissance_dayofmonth -------- + ------------ + ----------- + ------------ + - ----------- + ------------------ 1 | Emily | James | 1983 | 3 | 20 2 | John | Smith | 1990 | 8 | 12 (2 rangées) Interrogeons la veille des données que nous prévoyons d'être identiques à la primaire. En veille, nous pouvons exécuter la requête ci-dessus:
Postgres = # select * parmi les employés; EMP_ID | First_name | Last_name | Birth_year | Birth_month | naissance_dayofmonth -------- + ------------ + ----------- + ------------ + - ----------- + ------------------ 1 | Emily | James | 1983 | 3 | 20 2 | John | Smith | 1990 | 8 | 12 (2 rangées) Et avec cela, nous avons terminé, nous avons une configuration de secours chaude en cours d'exécution avec un serveur primaire et un serveur de secours, synchronisant du maître à l'esclave, tandis que les requêtes en lecture seule sont autorisées à Slave.
Conclusion
Il existe de nombreuses façons de créer une réplication avec PostgreSQL, et il existe de nombreux tuniculables concernant la réplication de streaming que nous avons également configurée pour rendre la configuration plus robuste, défaillante ou même avoir plus de membres. Ce tutoriel n'est pas applicable à un système de production - il est censé afficher certaines directives générales sur ce qui est impliqué dans une telle configuration.
Gardez à l'esprit que l'outil pg_basebackup est uniquement disponible auprès de PostgreSQL version 9.1+. Vous pouvez également envisager d'ajouter un archivage de WAL valide à la configuration, mais par souci de simplicité, nous avons sauté cela dans ce tutoriel pour garder les choses à faire minimal tout en atteignant une paire de systèmes de synchronisation de travail. Et enfin encore une chose à noter: la veille est pas sauvegarde. Avoir une sauvegarde valide à tout moment.
Tutoriels Linux connexes:
- Choses à installer sur Ubuntu 20.04
- Ubuntu 20.04 Installation de PostgreSQL
- Ubuntu 22.04 Installation de PostgreSQL
- Une introduction à l'automatisation Linux, des outils et des techniques
- Choses à faire après l'installation d'Ubuntu 20.04 Focal Fossa Linux
- Fichiers de configuration Linux: 30 premiers
- Téléchargement Linux
- Linux peut-il obtenir des virus? Exploration de la vulnérabilité de Linux…
- Mint 20: Mieux que Ubuntu et Microsoft Windows?
- Choses à installer sur Ubuntu 22.04