

Comment installer et configurer Apache Hadoop sur un seul nœud dans CentOS 7

- 3168
- 31
- Zoe Dupuis
Apache Hadoop est une construction de framework open source pour les données de stockage et de traitement des mégadonnées distribuées entre les clusters d'ordinateur. Le projet est basé sur les composants suivants:
- Hadoop commun - Il contient les bibliothèques Java et les services publics nécessaires aux autres modules Hadoop.
- HDFS - Système de fichiers distribué Hadoop - Un système de fichiers évolutif basé sur Java distribué sur plusieurs nœuds.
- Mapreduce - Cadre de fil pour le traitement parallèle des mégadonnées.
- Fil Hadoop: Un cadre pour la gestion des ressources en cluster.
Installez Hadoop dans Centos 7 Cet article vous guidera sur la façon d'installer Apache Hadoop sur un seul cluster de nœuds dans Centos 7 (fonctionne également pour Rhel 7 et Fedora 23+ versions). Ce type de configuration est également référencé comme Mode hadoop pseudo-distribué.
Étape 1: Installez Java sur Centos 7
1. Avant de poursuivre l'installation de Java, première connexion avec l'utilisateur racine ou un utilisateur avec des privilèges racine configurez votre nom d'hôte de machine avec la commande suivante.
# HostNamectl set-hostname maître
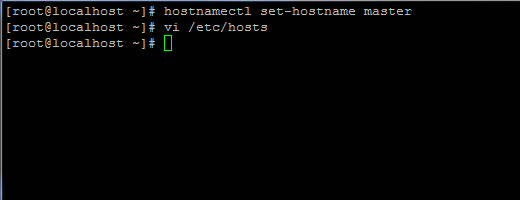 Définir le nom d'hôte dans Centos 7
Définir le nom d'hôte dans Centos 7 Ajoutez également un nouvel enregistrement dans le fichier hôtes avec votre propre machine FQDN pour pointer vers l'adresse IP de votre système.
# vi / etc / hôtes
Ajouter la ligne ci-dessous:
192.168.1.41 Maître.hadoop.lan
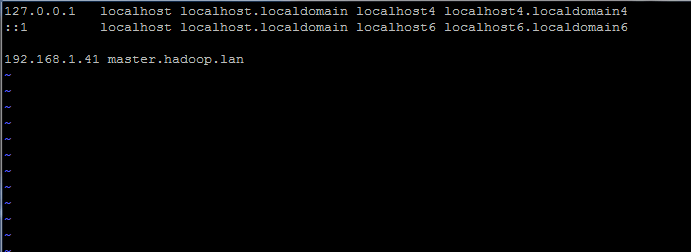 Définir le nom d'hôte dans / etc / hôte du fichier
Définir le nom d'hôte dans / etc / hôte du fichier Remplacez les enregistrements de nom d'hôte et de FQDN ci-dessus par vos propres paramètres.
2. Ensuite, allez sur la page de téléchargement d'Oracle Java et prenez la dernière version de Kit de développement Java SE 8 sur votre système avec l'aide de boucle commande:
# curl -lo -h "cookie: oracleLicense = accept-securebackup-cookie" "http: // download.oracle.com / otn-pub / java / jdk / 8u92-b14 / jdk-8u92-linux-x64.RPM ”
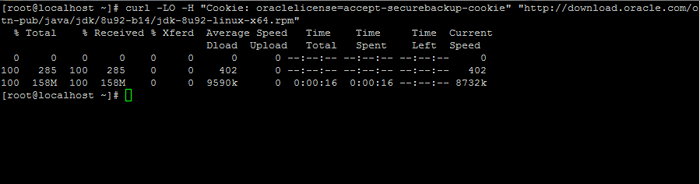 Télécharger le kit de développement Java SE 8
Télécharger le kit de développement Java SE 8 3. Une fois les finitions de téléchargement binaire Java, installez le package en émettant la commande ci-dessous:
# RPM -UVH JDK-8U92-LINUX-X64.RPM
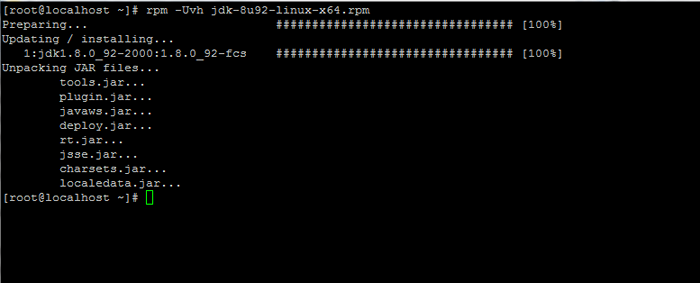 Installer Java dans Centos 7
Installer Java dans Centos 7 Étape 2: Installez le cadre Hadoop dans Centos 7
4. Ensuite, créez un nouveau compte utilisateur sur votre système sans pouvoirs racine que nous l'utiliserons pour le chemin d'installation de Hadoop et l'environnement de travail. Le nouveau répertoire de la maison de compte résidera dans / opt / hadoop annuaire.
# useradd -d / opt / hadoop hadoop # passwd hadoop
5. À l'étape suivante, visitez la page Apache Hadoop afin d'obtenir le lien de la dernière version stable et de télécharger l'archive sur votre système.
# curl -o http: // apache.javapipe.com / hadoop / commun / hadoop-2.7.2 / Hadoop-2.7.2.le goudron.gz
 Télécharger le package Hadoop
Télécharger le package Hadoop 6. Extraire les archives La copie du contenu du répertoire sur le chemin d'accueil du compte Hadoop. Assurez-vous également de modifier les autorisations des fichiers copiés en conséquence.
# Tar xfz Hadoop-2.7.2.le goudron.gz # cp -rf hadoop-2.7.2 / * / opt / hadoop / # chown -r hadoop: hadoop / opt / hadoop /
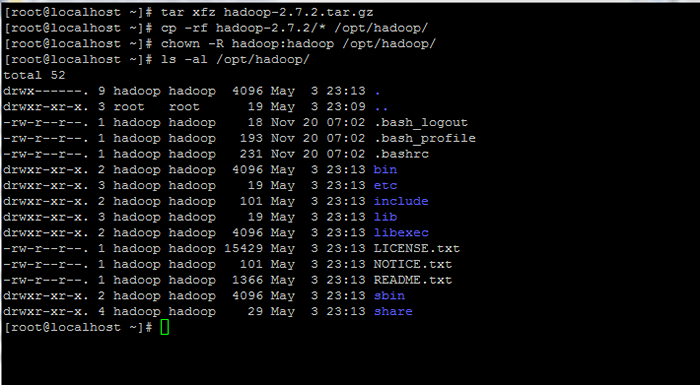 Extraire et définir les autorisations sur Hadoop
Extraire et définir les autorisations sur Hadoop 7. Ensuite, connectez-vous avec hadoop utilisateur et configurer Hadoop et Variables de l'environnement Java sur votre système en modifiant le .bash_profile déposer.
# Su - Hadoop $ VI .bash_profile
Ajoutez les lignes suivantes à la fin du fichier:
## Variables Env Java export java_home = / usr / java / par défaut exporter path = $ path: $ java_home / bin export classpath =.: $ Java_home / jre / lib: $ java_home / lib: $ java_home / lib / outils.pot ## Variables Env Hadoop export hadoop_home = / opt / hadoop export hadoop_common_home = $ hadoop_home export hadoop_hdfs_home = $ hadoop_home export hadoop_mapred_home = $ hadoop_home export hadoop_yarn_home = $ hadoop_home export hadoop_opts = "- djava.bibliothèque.path = $ hadoop_home / lib / natif "export hadoop_common_lib_native_dir = $ hadoop_home / lib / native export path = $ path: $ hadoop_home / sbin: $ hadoop_home / bin
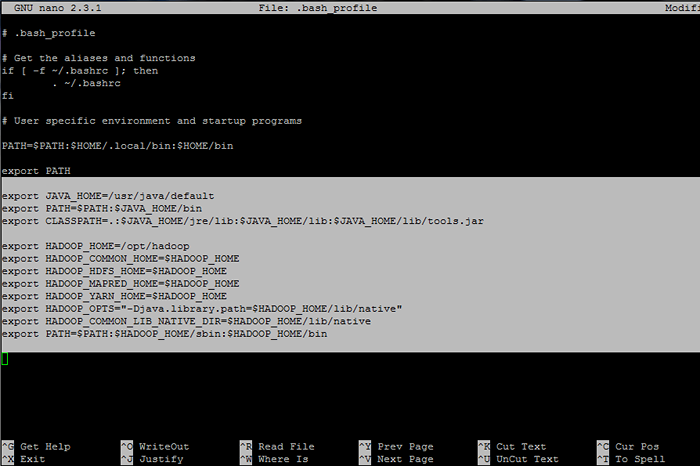 Configurer les variables d'environnement Hadoop et Java
Configurer les variables d'environnement Hadoop et Java 8. Maintenant, initialisez les variables d'environnement et vérifiez leur statut en émettant les commandes ci-dessous:
$ source .bash_profile $ echo $ hadoop_home $ echo $ java_home
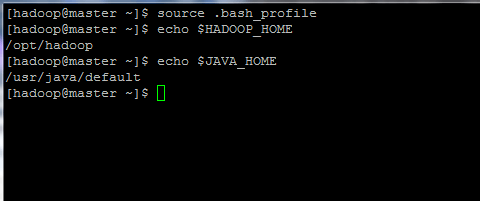 Initialiser les variables d'environnement Linux
Initialiser les variables d'environnement Linux 9. Enfin, configurer l'authentification basée sur la clé SSH pour hadoop compte en exécutant les commandes ci-dessous (remplacez le nom d'hôte ou Fqdn contre la ssh-copy-id commande en conséquence).
De plus, laissez le phrase secrète Classé vide afin de se connecter automatiquement via SSH.
$ ssh-keygen -t rsa $ ssh-copy-id maître.hadoop.lan
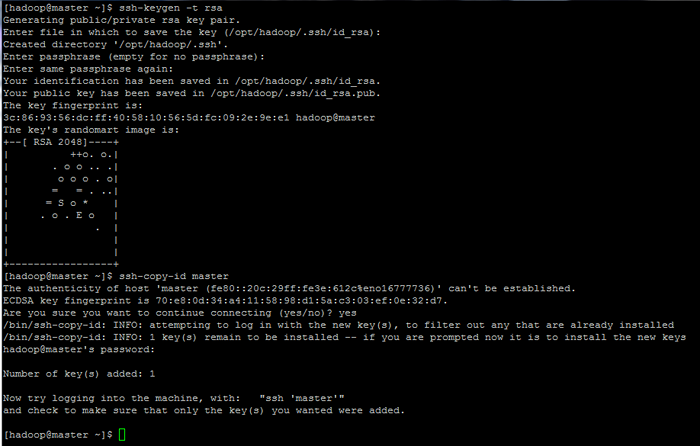 Configurer les pages d'authentification basées sur la clé SSH: 1 2 3
Configurer les pages d'authentification basées sur la clé SSH: 1 2 3
- « Trouvez les 10 meilleures adresses IP d'accès à votre serveur Web Apache
- 10 Questions d'entrevue utiles sur les services et démons Linux »