

Comment installer et configurer Apache Hadoop sur Centos & Fedora

- 4923
- 863
- Mohamed Brunet
Depuis un certain temps, Hadoop est devenu l'une des solutions de big data open-source les plus populaires. Il traite les données par lots et est célèbre pour ses capacités informatiques évolutives, rentables et distribuées. C'est l'un des cadres open source les plus populaires dans l'analyse des données et l'espace de stockage. En tant qu'utilisateur, vous pouvez l'utiliser pour gérer vos données, analyser ces données et les stocker à nouveau - le tout de manière automatisée. Avec Hadoop installé sur votre système Fedora, vous pouvez accéder facilement aux services analytiques importants.
Cet article couvre comment installer Apache Hadoop sur Centos et Fedora Systems. Dans cet article, nous vous montrerons comment installer Apache Hadoop sur Fedora pour une utilisation locale ainsi qu'un serveur de production.
1. Préalables
Java est la principale exigence pour exécuter Hadoop sur n'importe quel système, alors assurez-vous que Java soit installé sur votre système en utilisant la commande suivante. Si vous n'avez pas installé Java sur votre système, utilisez l'un des liens suivants pour l'installer d'abord.
- Comment installer Java 8 sur Centos / Rhel 7/6/5
2. Créer un utilisateur Hadoop
Nous vous recommandons de créer un compte normal (ni de racine) pour le travail Hadoop. Pour créer un compte en utilisant la commande suivante.
Adduser Hadoop Passwd Hadoop
Après avoir créé le compte, il devait également configurer SSH basé sur des clés sur son propre compte. Pour ce faire, utilisez des commandes suivantes.
su - hadoop ssh-keygen -t rsa -p "-f ~ /.ssh / id_rsa chat ~ /.ssh / id_rsa.pub >> ~ /.ssh / autorisé_keys chmod 0600 ~ /.SSH / AUTORISED_KEYS
Vérinons la connexion basée sur la clé. La commande ci-dessous ne doit pas demander le mot de passe, mais la première fois, il incitera à ajouter RSA à la liste des hôtes connus.
SSH LocalHost Exit
3. Télécharger Hadoop 3.1 archive
Dans cette étape, téléchargez Hadoop 3.1 fichier d'archive source à l'aide de la commande ci-dessous. Vous pouvez également sélectionner un autre miroir de téléchargement pour l'augmentation de la vitesse de téléchargement.
cd ~ wget http: // www-eu.apache.org / dist / hadoop / commun / hadoop-3.1.0 / Hadoop-3.1.0.le goudron.gz tar xzf hadoop-3.1.0.le goudron.gz mv hadoop-3.1.0 Hadoop
4. Configuration du mode hadoop pseudo-distribué
4.1. Configuration des variables d'environnement Hadoop
Tout d'abord, nous devons définir des utilisations variables de l'environnement par Hadoop. Modifier ~ /.bashrc fichier et ajouter les valeurs suivantes à la fin du fichier.
export hadoop_home = / home / hadoop / hadoop export hadoop_install = $ hadoop_home export hadoop_mapred_home = $ hadoop_home export hadoop_common_home = $ hadoop_home export_hoop_hdfs_home = $ hadoop_common " Hadoop_home / sbin: $ hadoop_home / bin
Appliquez maintenant les modifications de l'environnement de course actuel
source ~ /.bashrc
Modifiez maintenant $ Hadoop_home / etc / hadoop / hadoop-env.shot fichier et régler Java_home variable d'environnement. Modifiez le chemin Java selon l'installation de votre système. Ce chemin peut varier selon la version et la source d'installation du système d'exploitation. Alors assurez-vous que vous utilisez un chemin correct.
exporter java_home = / usr / lib / jvm / java-8-oracle
4.2. Configuration des fichiers de configuration Hadoop
Hadoop a de nombreux fichiers de configuration, qui doivent se configurer selon les exigences de votre infrastructure Hadoop. Commençons par la configuration avec la configuration de Basic Hadoop Node Cluster. Tout d'abord, accédez à l'emplacement ci-dessous
cd $ hadoop_home / etc / hadoop
Modifier le site core.xml
FS.défaut.nom hdfs: // localhost: 9000
Modifier le site HDFS.xml
DFS.réplication 1 DFS.nom.DIR FILE: /// home / hadoop / hadoopdata / hdfs / namenode dfs.données.DIR FILE: /// home / hadoop / hadoopdata / hdfs / datanode
Modifier le site Mapred.xml
mapreduce.cadre.Nommez le fil
Modifier le site du fil.xml
fil.nodemanager.Aux-Services MapReduce_Shuffle
4.3. Format namenode
Maintenant, formatez le namenode à l'aide de la commande suivante, assurez-vous que le répertoire de stockage est
hdfs namenode -format
Exemple de sortie:
AVERTISSEMENT: / Home / Hadoop / Hadoop / Logs n'existe pas. Création. 2018-05-02 17: 52: 09 678 Info namenode.Namenode: startup_msg: / ********************************************* *************** startup_msg: Démarrage de NameNode startup_msg: host = tecadmin / 127.0.1.1 startup_msg: args = [-format] startup_msg: version = 3.1.0… 2018-05-02 17: 52: 13,717 Info Commun.Stockage: Directoire de stockage / Home / Hadoop / HadoopData / HDFS / NameNode a été formaté avec succès. 2018-05-02 17: 52: 13 806 Info namenode.FsimageFormatProtobuf: Enregistrement du fichier image / home / hadoop / hadoopdata / hdfs / namenode / current / fsimage.CKPT_0000000000000000000 Utilisation de non-compression 2018-05-02 17: 52: 14,161 Info namenode.FsimageFormatProtobuf: fichier image / home / hadoop / hadoopdata / hdfs / namenode / current / fsimage.CKPT_0000000000000000000 de taille 391 octets enregistrés en 0 seconde . 2018-05-02 17: 52: 14 224 info namenode.NnstorageRetentionManager: aller conserver 1 images avec txid> = 0 2018-05-02 17: 52: 14,282 info namenode.Namenode: shutdown_msg: / ********************************************* *************** shutdown_msg: Arrêt Namenode à Tecadmin / 127.0.1.1 ************************************************* *********** /
5. Démarrer le cluster Hadoop
Commençons votre cluster Hadoop en utilisant les scripts fourni par Hadoop. Accédez simplement à votre répertoire $ hadoop_home / sbin et exécutez des scripts un par un.
cd $ hadoop_home / sbin /
MAINTENANT start-dfs.shot scénario.
./ start-dfs.shot
Exemple de sortie:
Début namenodes sur [LocalHost] Démarrage des datanodes Début de namenodes secondaires [Tecadmin] 2018-05-02 18: 00: 32 565 Warn Util.NativeCodeLoader: Impossible de charger la bibliothèque native-hadoop pour votre plate-forme… en utilisant des classes intégrées-java, le cas échéant, le cas échéant
MAINTENANT démarrage.shot scénario.
./ start-yarn.shot
Exemple de sortie:
Démarrer ResourceManager Démarrer les nodemanagers
6. Accès aux services Hadoop dans le navigateur
Hadoop Namenode a commencé sur le port 9870 par défaut. Accédez à votre serveur sur le port 9870 dans votre navigateur Web préféré.
http: // svr1.técadmin.net: 9870 /
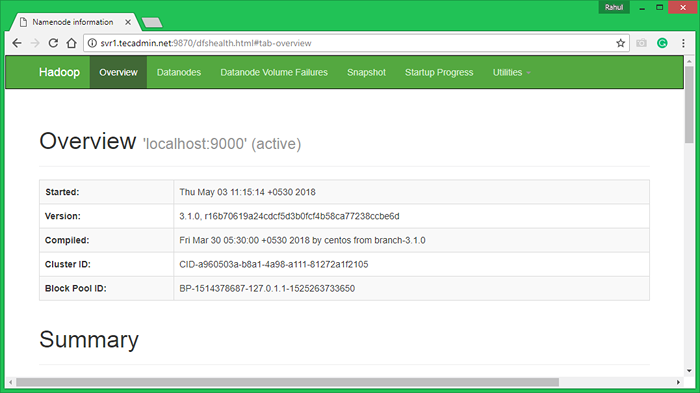
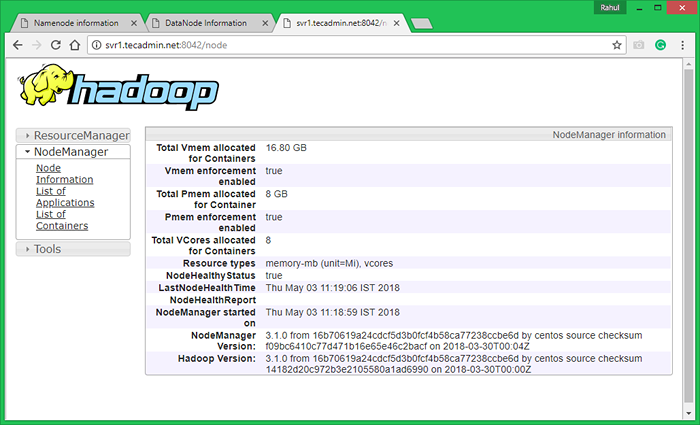
Maintenant, accédez au port 8042 pour obtenir les informations sur le cluster et toutes les applications
http: // svr1.técadmin.net: 8042 /
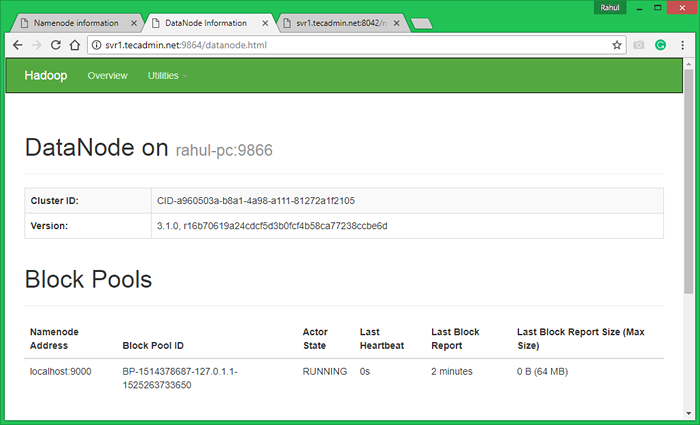
Port d'accès 9864 pour obtenir des détails sur votre nœud Hadoop.
http: // svr1.técadmin.net: 9864 /
7. Tester la configuration du nœud unique Hadoop
7.1. Faire les répertoires HDFS requis en utilisant les commandes suivantes.
bin / hdfs dfs -mkdir / utilisateur bin / hdfs dfs -mkdir / user / hadoop
7.2. Copiez tous les fichiers du système de fichiers local / var / log / httpd au système de fichiers distribué hadoop à l'aide de la commande ci-dessous
bin / hdfs dfs -put / var / log / apache2 journaux
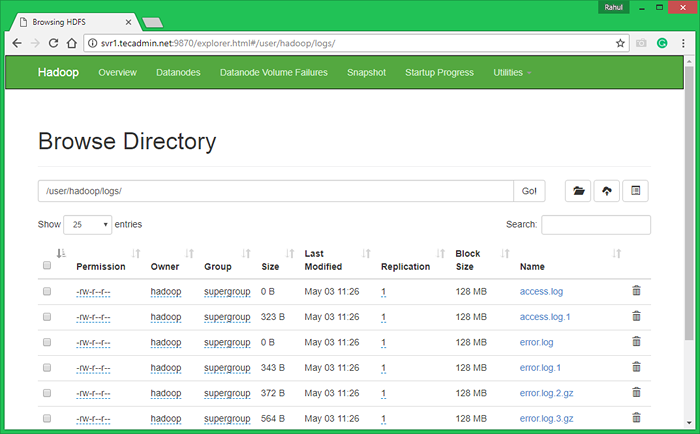
7.3. Parcourir le système de fichiers distribué Hadoop en ouvrant sous URL dans le navigateur. Vous verrez un dossier Apache2 dans la liste. Cliquez sur le nom du dossier à ouvrir et vous y trouverez tous les fichiers de journal.
http: // svr1.técadmin.Net: 9870 / Explorer.html # / user / hadoop / logs /
7.4 - Copiez maintenant le répertoire des journaux pour le système de fichiers distribué Hadoop au système de fichiers local.
bin / hdfs dfs -get logs / tmp / logs ls -l / tmp / logs /
Vous pouvez également vérifier ce tutoriel pour exécuter un exemple de travail WordCount MapReduce en utilisant la ligne de commande.
- « 10 choses à faire après l'installation d'Ubuntu & Linux Mint
- Comment supprimer l'élément de tableau JavaScript par valeur »