

Comment installer et configurer la ruche avec une haute disponibilité - partie 7

- 4415
- 919
- Anaïs Charles
Ruche est un Entrepôt de données modéliser Hadoop Écosystème. Il peut fonctionner comme un outil ETL au-dessus de Hadoop. Activer la haute disponibilité (HA) sur Hive n'est pas similaire à ce que nous le faisons dans les services de maîtrise comme Namenode et le gestionnaire de ressources.
Le basculement automatique ne se produira pas dans Ruche (HiveServer2). Si seulement HiveServer2 (HS2) échoue, exécuter des travaux sur ce qui a échoué HS2 fera échouer. Nous devons soumettre à nouveau le travail afin que le travail puisse fonctionner sur d'autres HiveServer2. Donc, activer HA sur HS2 n'est rien que, augmentant le nombre de HS2 composants dans Grappe.
Dans cet article, nous verrons les étapes pour installer et activer le La haute disponibilité de Ruche.
Exigences
- Meilleures pratiques pour le déploiement du serveur Hadoop sur Centos / Rhel 7 - Partie 1
- Configuration de Hadoop avant les requis et le durcissement de la sécurité - Partie 2
- Comment installer et configurer le gestionnaire Cloudera sur Centos / Rhel 7 - partie 3
- Comment installer CDH et configurer des placements de service sur Centos / Rhel 7 - Partie 4
- Comment configurer la haute disponibilité pour Namenode - Partie 5
- Comment configurer la haute disponibilité pour le gestionnaire de ressources - partie 6
Commençons…
Installation et configuration de la ruche
1. Se connecter à Cloudera Manager à l'URL ci-dessous et naviguer vers Cloudera Manager -> Ajouter un service.
http: // 13.233.129.39: 7180 / cmf / maison
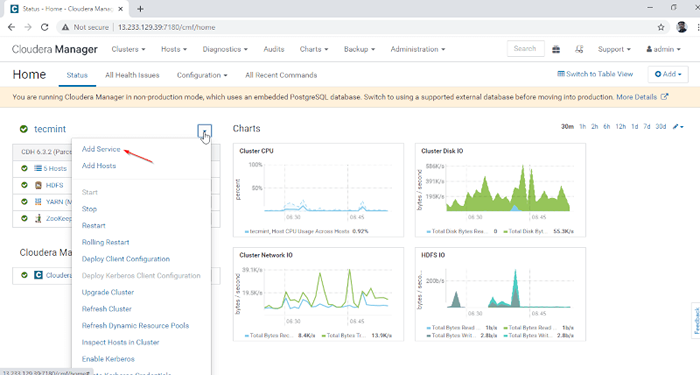 Ajouter un service dans Cloudera Manager
Ajouter un service dans Cloudera Manager 2. Sélectionnez le service 'Ruche'.
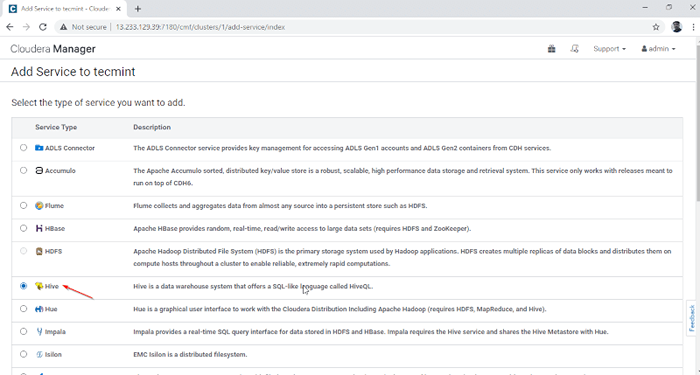 Choisissez le service Hive
Choisissez le service Hive 3. Affecter les services sur les nœuds.
- passerelle - C'est le service client où l'utilisateur peut accéder à la ruche. Habituellement, ce service sera placé dans Bord nœuds dédiés aux utilisateurs.
- Hive Metastore - C'est un référentiel central pour stocker les métadonnées de ruche.
- Serveur webhcat - Il s'agit d'une API Web pour HCATALOG et d'autres services Hadoop.
- HiveServer2 - C'est une interface de clients pour l'exécution de la requête sur Hive.
Une fois sélectionné les serveurs, cliquez surContinuer' procéder.
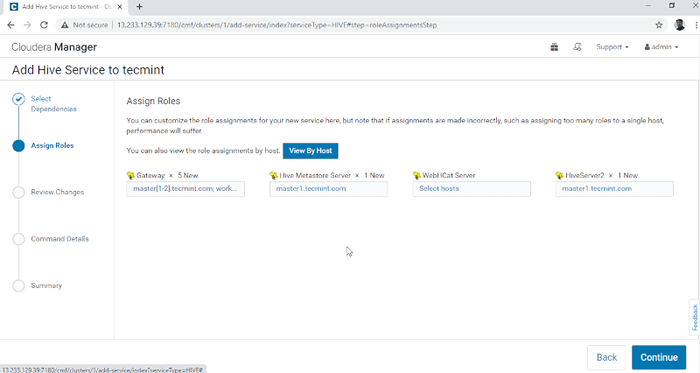 Affecter le service en tant que nœuds
Affecter le service en tant que nœuds 4. Hive Metastore a besoin d'une base de données sous-jacente pour stocker les métadonnées. Ici, nous utilisons la valeur par défaut Postgresql base de données qui est intégrée avec CDH.
Les détails de la base de données mentionnés ci-dessous seront saisis automatiquement, 'Test de connexion'sera ignoré car la base de données mentionnée sera créée à la volée. En temps réel, nous devons créer la base de données dans la base de données externe et tester la connexion pour continuer. Une fois terminé, veuillez cliquer sur le 'Continuer'.
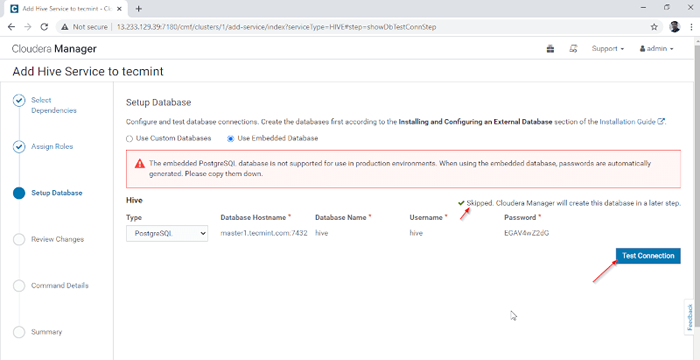 Configuration de la base de données
Configuration de la base de données 5. Configurer le Entrepôt de ruche annuaire, / utilisateur / ruche / entrepôt est le chemin de répertoire par défaut pour stocker les tables de ruche. Clique le 'Continuer'.
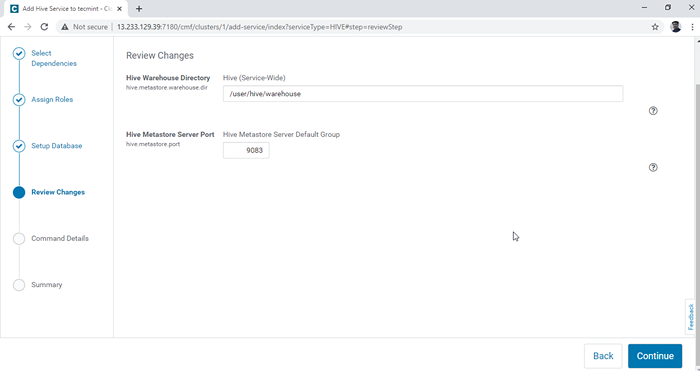 Choisissez le répertoire de l'entrepôt Hive
Choisissez le répertoire de l'entrepôt Hive 6. L'installation de la ruche est lancée.
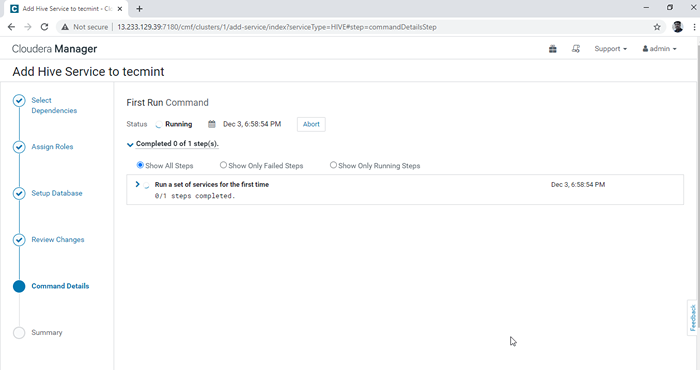 Progrès de l'installation de la ruche
Progrès de l'installation de la ruche 7. Une fois l'installation terminée, vous pouvez obtenir le 'Fini' statut. Cliquez sur 'Continuer'Pour avancer.
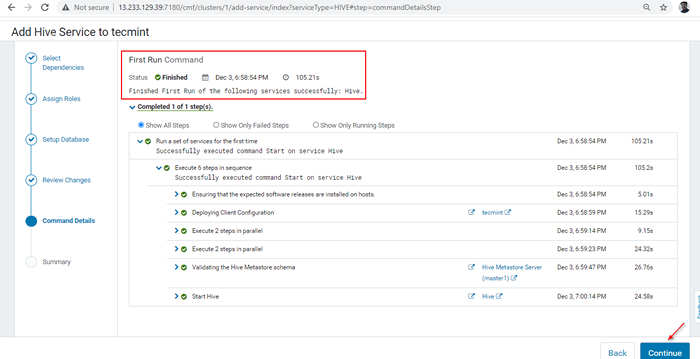 Installation de ruche terminée
Installation de ruche terminée 8. L'installation et la configuration de la ruche sont terminées avec succès. Cliquez sur 'Finir'Pour terminer la procédure d'installation.
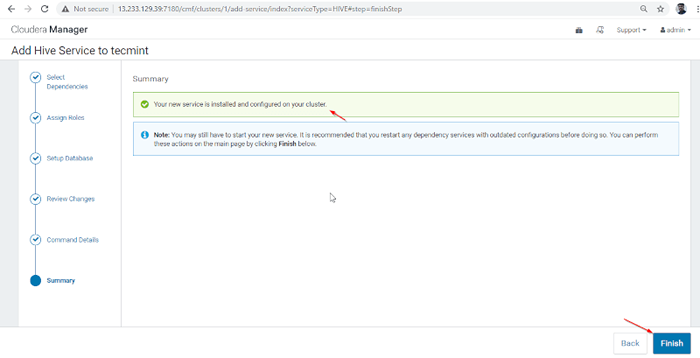 Installation de la ruche terminer
Installation de la ruche terminer 9. Tu peux voir le Ruche service ajouté dans Grappe à travers Tableau de bord Cloudera Manager.
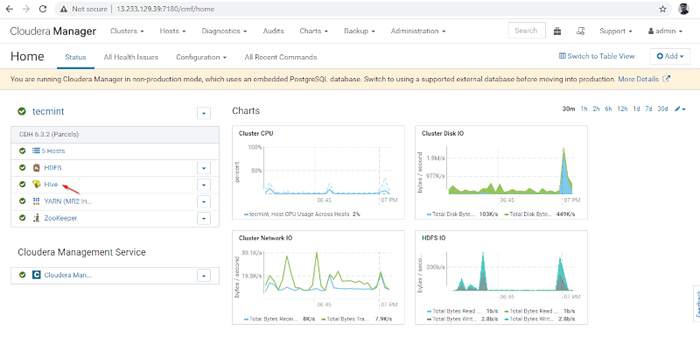 Service Hive ajouté
Service Hive ajouté dix. Vous pouvez voir le HiveServer2 dans Instances de Ruche. Nous avons ajouté HiveServer2 dans maître1.
Cloudera Manager -> Ruche -> Instances -> HiveServer2.
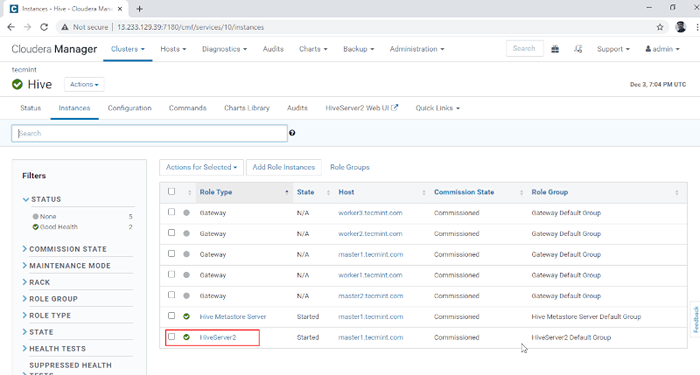 Voir les instances de HiveServer2
Voir les instances de HiveServer2 Permettant une haute disponibilité sur Hive
11. Ensuite, ajoutez le rôle de ruche en allant à Cloudera Manager -> Ruche -> Actions -> Ajouter un rôle Instances.
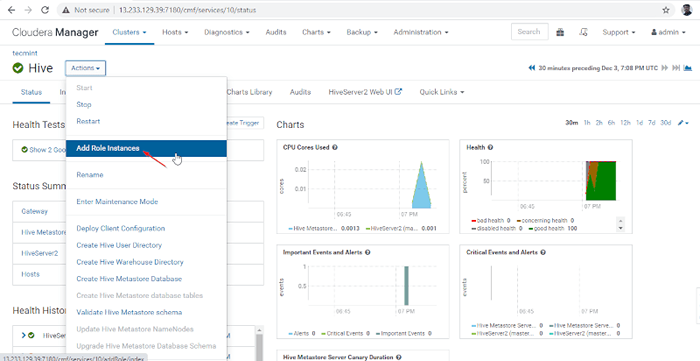 Ajouter une instance de rôle Hive
Ajouter une instance de rôle Hive 12. Sélectionnez les serveurs où vous souhaitez placer plus HiveServer2. Vous pouvez en ajouter plus de deux, il n'y a pas de limite. Ici, nous en ajoutons un supplémentaire HiveServer2 dans maître2.
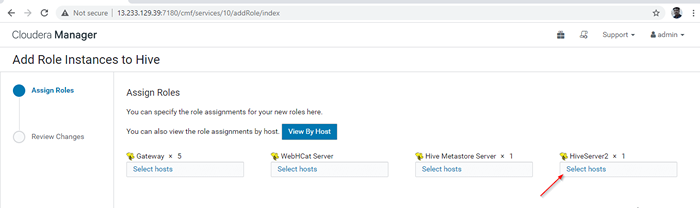 Choisissez le serveur pour Hive
Choisissez le serveur pour Hive 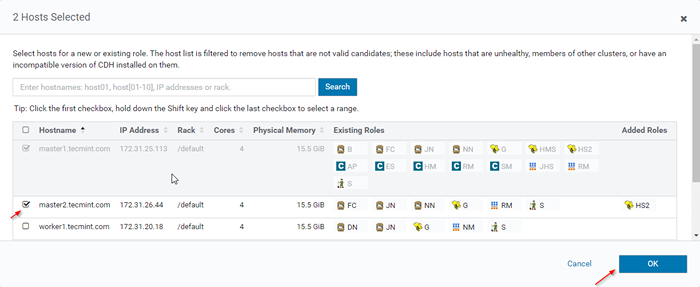 Choisissez le serveur hôte
Choisissez le serveur hôte 13. Une fois sélectionné le serveur, cliquez surContinuer'.
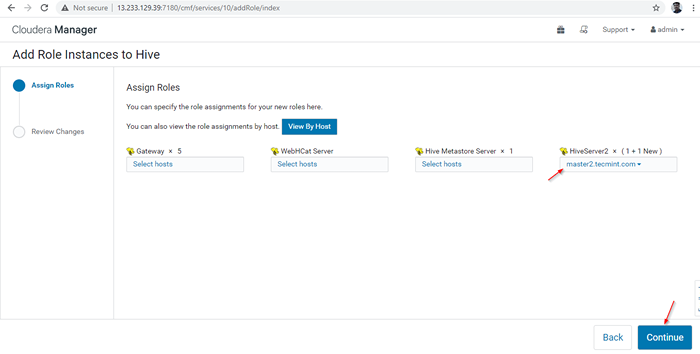 Serveur ajouté
Serveur ajouté 14. UN HIVERSERVER2 sera ajouté dans le Instances de ruche, Vous devez commencer en allant à Cloudera Manager -> Ruche -> Instances -> (Sélectionnez HiveServer2 ajouté nouvellement) -> Action pour sélectionné -> Commencer.
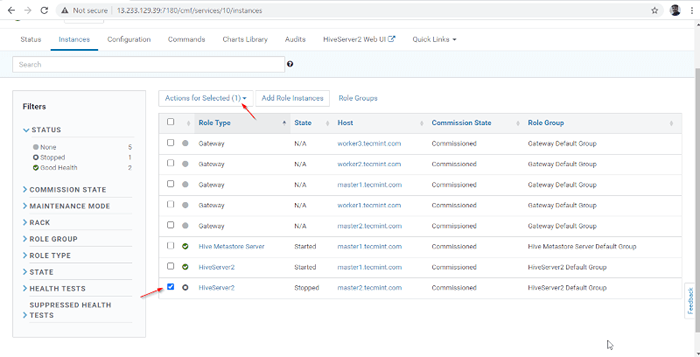 Choisissez le serveur Hive
Choisissez le serveur Hive 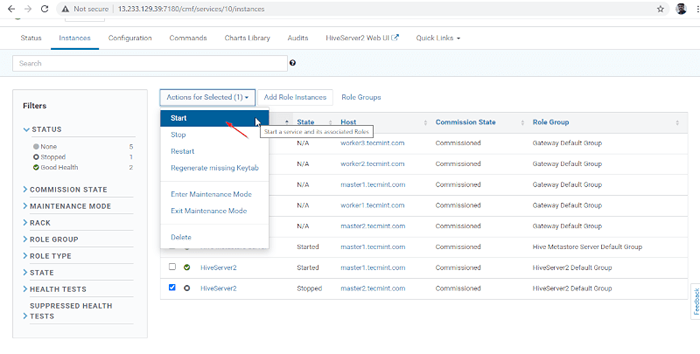 Démarrer le serveur Hive
Démarrer le serveur Hive 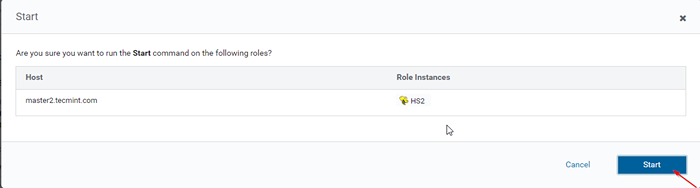 Démarrer le serveur Hive
Démarrer le serveur Hive 15. Une fois HiveServer2 commencé le maître2, vous obtiendrez le statut 'Fini'. Cliquez sur Fermer.
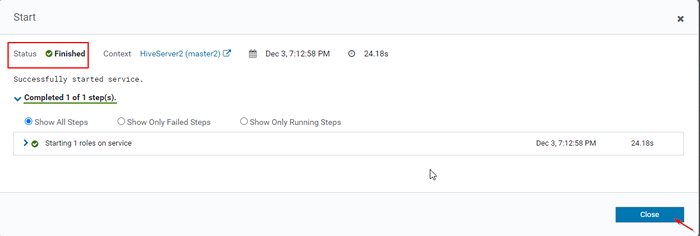 Statut: Terminé
Statut: Terminé 16. Vous pouvez voir, à la fois le HiveServer2 sont en train de courir.
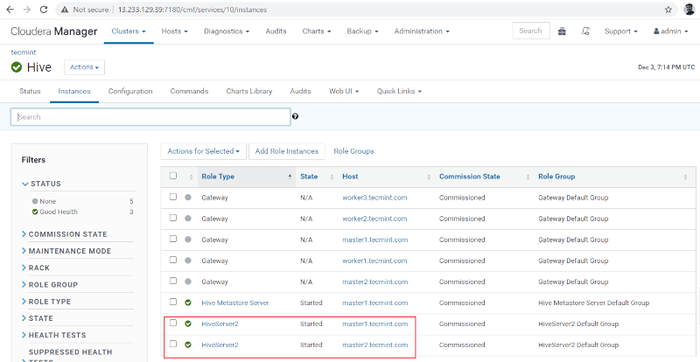 Vérifiez l'état des serveurs Hive
Vérifiez l'état des serveurs Hive Vérifier la disponibilité de la ruche
Nous pouvons connecter le HiveServer2 à travers le Beneline qui est un client mince et une ligne de commande. Il utilise le pilote JDBC pour établir la connexion.
17. Connectez-vous vers le serveur où Passerelle est en cours d'exécution.
[[Protégé par e-mail] ~] $ beeline
 Connectez-vous à HiveServer2
Connectez-vous à HiveServer2 18. Entrer le JDBC chaîne de connexion pour connecter le HiveServer2. À cet égard, le chaîne Nous mentionnons le HIVERSERVER2 (maître2) avec son numéro de port par défaut 10000. Cette chaîne de connexion ne se connectera qu'au HiveServer2 qui fonctionne maître2.
Been> !Connectez "JDBC: Hive2: // Master1.Tecmint.com: 10000 "
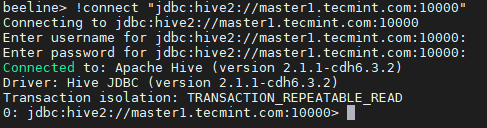 Chaîne de connexion JDBC
Chaîne de connexion JDBC 19. Exécutez un exemple de requête.
0: JDBC: Hive2: // Master1.Tecmint.com: 10000> Afficher les bases de données;
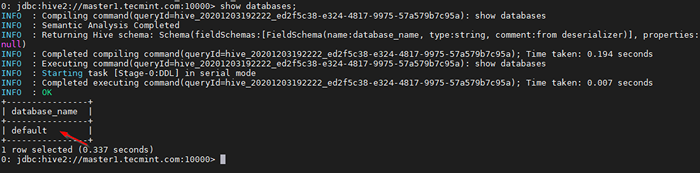 Exécutez des échantillons de requête
Exécutez des échantillons de requête Il s'agit de la base de données par défaut qui vient intégrée.
20. Utilisez la commande ci-dessous pour mettre fin à la session Hive.
0: JDBC: Hive2: // Master1.Tecmint.com: 10000> !arrêter
 Quitter la session de ruche
Quitter la session de ruche 21. Vous pouvez utiliser la même manière pour vous connecter HiveServer2 courir sur maître2.
Been> !Connect "JDBC: Hive2: // Master2.Tecmint.com: 10000 "
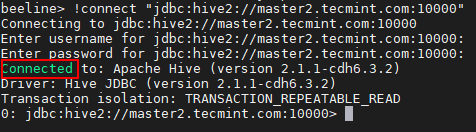 Connectez-vous au serveur Hive
Connectez-vous au serveur Hive 23. Nous pouvons connecter le HiveServer2 dans Discovery de gardien de zoo mode. Dans cette méthode, nous n'avons pas besoin de mentionner le HiveServer2 Dans la chaîne de connexion à la place, nous utilisons Gardien de zoo pour découvrir le disponible HiveServer2.
Ici, nous pouvons utiliser un équilibreur de charge tiers pour équilibrer la charge parmi les disponibles HIVERSERVER2. La configuration ci-dessous est nécessaire pour activer Mode de découverte de Zookeeper en allant à Cloudera Manager -> Ruche -> Configuration.
 Activer le mode de découverte de Zookeeper
Activer le mode de découverte de Zookeeper 24. Ensuite, recherchez la propriété "HiveServer2 Extrait de configuration avancée»Et cliquez sur le + symbole pour ajouter la propriété ci-dessous.
Nom: ruche.serveur2.soutien.dynamique.service.Valeur de découverte: Vrai Description:
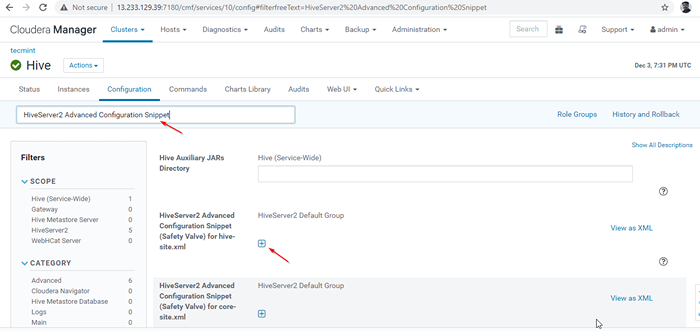 HiveServer2 Extrait de configuration avancée
HiveServer2 Extrait de configuration avancée 25. Une fois entré la propriété, cliquez surSauvegarder les modifications'.
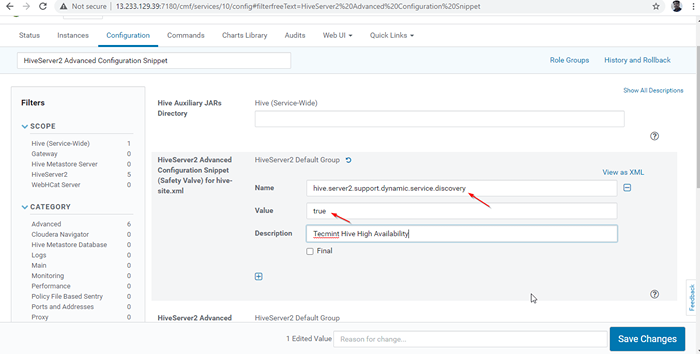 Ajouter une propriété
Ajouter une propriété 26. Au fur et à mesure que nous avons apporté des modifications à la configuration, devons redémarrer les services affectés en cliquant sur le symbole de couleur orange pour redémarrer les services.
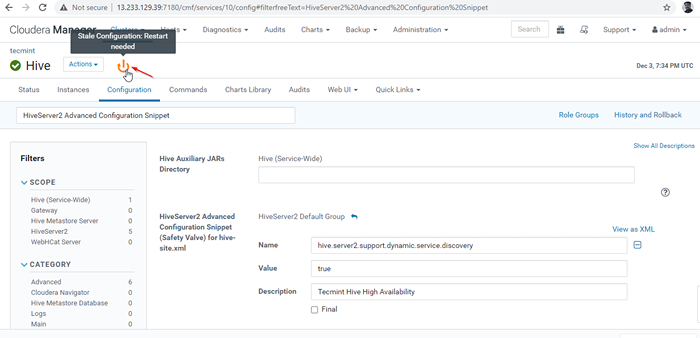 Redémarrer les services
Redémarrer les services 27. Cliquez sur 'Redémarrer' prestations de service.
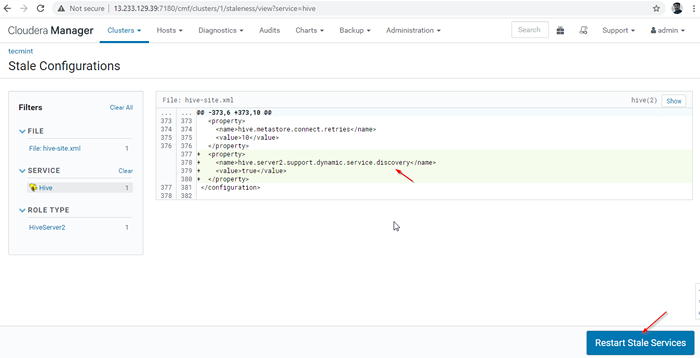 Redémarrer les services
Redémarrer les services 28. Il existe deux options disponibles. Si le cluster est en production en direct, nous devons préférer le redémarrage de roulement pour minimiser la panne. Au fur et à mesure que nous installons, nous pouvons choisir la deuxième option 'Redéploiter la configuration du client', et cliquez'Redémarrer maintenant'.
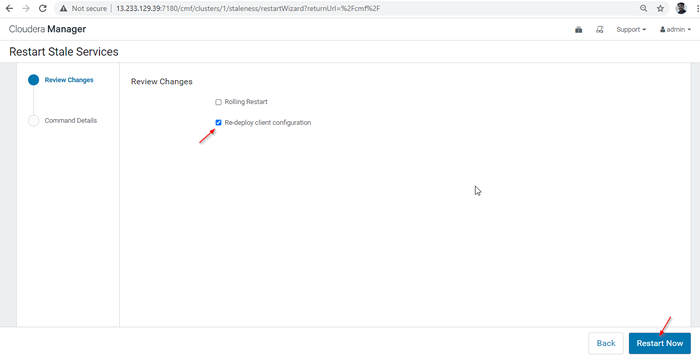 Redéploiter la configuration du client
Redéploiter la configuration du client 29. Une fois le redémarrage terminé avec succès, vous obtiendrez le statut 'Fini'. Cliquez sur 'Finir'Pour terminer le processus.
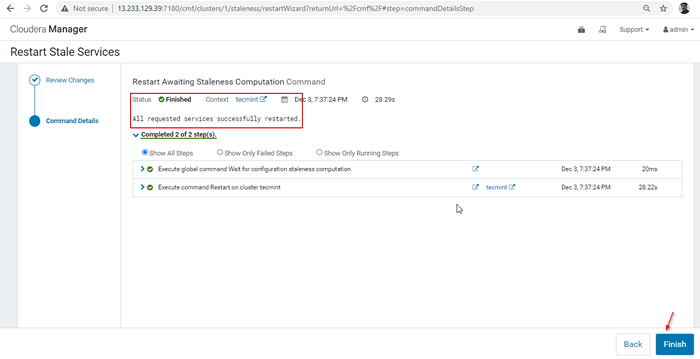 Terminer le processus
Terminer le processus 30. Maintenant, nous allons connecter le HiveServer2 en utilisant Discovery de gardien de zoo mode. Dans le JDBC connexion, la chaîne dont nous avons besoin pour utiliser le Gardien de zoo serveurs avec son numéro de port 2081. Collectez les serveurs Zookeeper en allant à Cloudera Manager -> Gardien de zoo -> Instances -> (Notez les noms des serveurs).
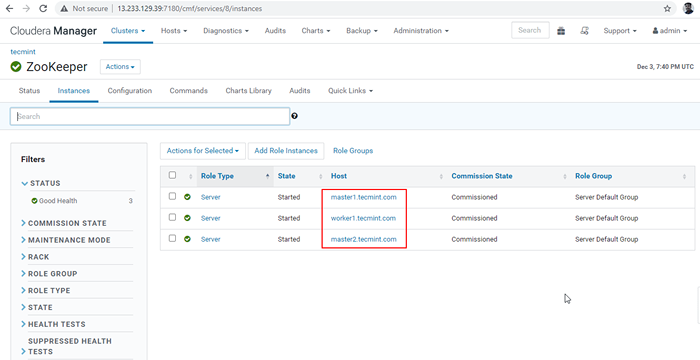 Serveurs de gardien de zoo
Serveurs de gardien de zoo Ce sont les trois serveurs ayant Zookeeper, 2181 est le numéro de port.
maître1.Tecmint.com: 2181 Master2.Tecmint.com: 2181 Worker1.Tecmint.com: 2181
31. Maintenant entrer dans ligne droite.
[[Protégé par e-mail] ~] $ beeline
 Connectez-vous pour être
Connectez-vous pour être 32. Entrer le JDBC chaîne de connexion comme mention ci-dessous. Nous devons mentionner le Mode de découverte de service et Espace de noms de Zookeeper. 'HiveServer2'est l'espace de noms par défaut de HiveServer2.
Been>!Connectez "JDBC: Hive2: // Master1.Tecmint.com: 2181, maître2.Tecmint.com: 2181, Worker1.Tecmint.com: 2181 /; ServicediscoveryMode = zookeeper; zookeeneramespace = HiveServer2 "
 ENTRE
ENTRE 33. Maintenant, la session est connectée à HiveServer2 courir sur maître1. Exécutez un exemple de requête pour valider. Utilisez la commande ci-dessous pour créer une base de données.
0: JDBC: Hive2: // Master1.Tecmint.com: 2181, Mast> Créer une base de données tecmint;
 Créer une base de données
Créer une base de données 34. Utilisez la commande ci-dessous pour répertorier la base de données.
0: JDBC: Hive2: // Master1.Tecmint.com: 2181, Mast> Afficher les bases de données;
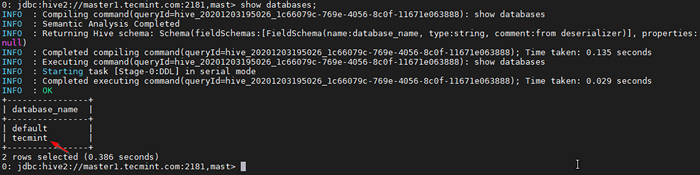 Base de données sur la liste
Base de données sur la liste 35. Nous allons maintenant valider la haute disponibilité dans Mode de découverte de Zookeeper. Aller à Cloudera Manager et arrêter le HiveServer2 sur maître1 que nous avons testé ci-dessus.
Cloudera Manager -> Ruche -> Instances -> (sélectionner HiveServer2 sur maître1) -> Action pour sélectionné -> Arrêt.
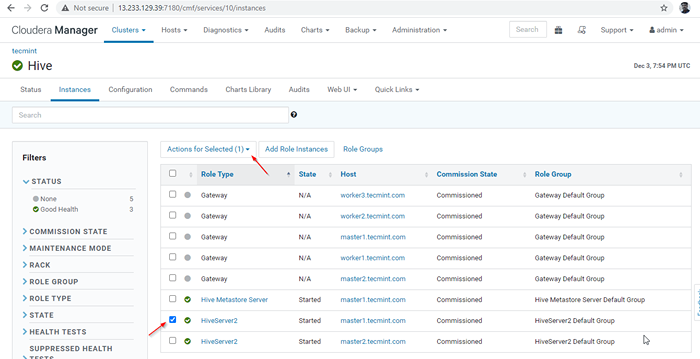 Choisissez le serveur Hive
Choisissez le serveur Hive 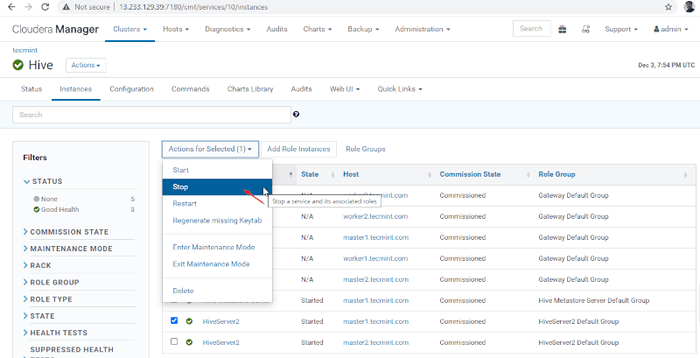 Arrêter le serveur de ruche
Arrêter le serveur de ruche 36. Clique le 'Arrêt'. Une fois arrêté, vous obtiendrez le statut 'Fini'. Vérifiez le HiveServer2 sur maître1 en naviguant dans Ruche -> Instances.
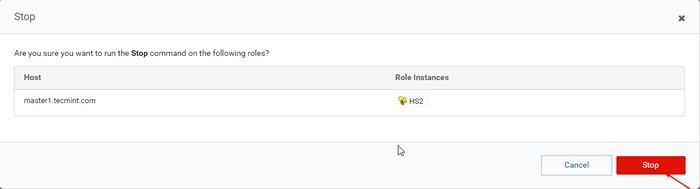 Arrêter le serveur de ruche
Arrêter le serveur de ruche 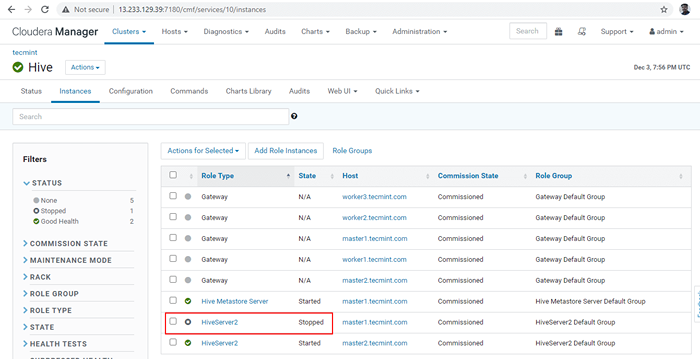 Vérifiez le serveur Hive
Vérifiez le serveur Hive 37. Entrer dans le ligne droite et connecter le HiveServer2 en utilisant le même JDBC chaîne de connexion avec Mode de découverte de Zookeeper Comme nous l'avons fait dans les étapes ci-dessus.
[[e-mail protégé] ~] $ beeline beeline>!Connectez "JDBC: Hive2: // Master1.Tecmint.com: 2181, maître2.Tecmint.com: 2181, Worker1.Tecmint.com: 2181 /; ServicediscoveryMode = zookeeper; zookeeneramespace = HiveServer2 "
 Connectez le HiveServer2
Connectez le HiveServer2 Maintenant, vous serez connecté à HiveServer2 courir sur maître2.
38. Valider avec un échantillon de requête.
0: JDBC: Hive2: // Master1.Tecmint.com: 2181, Mast> Afficher les bases de données;
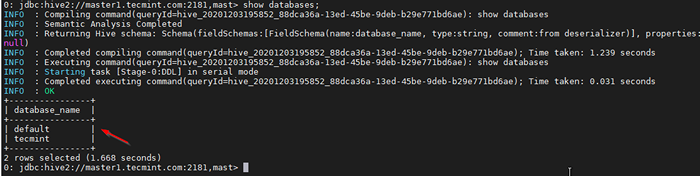 Valider la requête d'échantillon
Valider la requête d'échantillon Conclusion
Dans cet article, nous avons parcouru les étapes détaillées pour avoir le Entrepôt de données Hive modèle dans notre Grappe avec La haute disponibilité. Dans un environnement de production en temps réel, plus de trois HiveServer2 sera placé avec Mode de découverte de Zookeeper activé.
Ici, tout le HiveServer2 s'inscrivent avec Gardien de zoo sous un commun Espace de noms. Zookeeper dynamiquement découvre le disponible HiveServer2 et établit la session de ruche.
- « Comment installer VMware Workstation 16 Pro sur les systèmes Linux
- Comment installer un cluster Kubernetes sur Centos 8 »