

Comment installer Apache Hadoop sur Ubuntu 22.04

- 2151
- 589
- Emilie Colin
Comprendre les données non structurées et analyser des quantités massives de données est un jeu de balle différent aujourd'hui. Et donc, les entreprises ont eu recours à Apache Hadoop et à d'autres technologies connexes pour gérer leurs données non structurées plus efficacement. Pas seulement les entreprises mais aussi les individus utilisent Apache Hadoop à diverses fins, comme l'analyse de grands ensembles de données ou la création d'un site Web qui peut traiter les requêtes utilisateur. Cependant, l'installation d'Apache Hadoop sur Ubuntu peut sembler une tâche difficile pour les utilisateurs nouveaux dans le monde des serveurs Linux. Heureusement, vous n'avez pas besoin d'être un administrateur système expérimenté pour installer Apache Hadoop sur Ubuntu.
Le guide d'installation étape par étape suivant vous permettra de traverser l'ensemble du processus, du téléchargement du logiciel à la configuration du serveur avec facilité. Dans cet article, nous expliquerons comment installer Apache Hadoop sur Ubuntu 22.04 Système LTS. Cela peut également être utilisé pour d'autres versions Ubuntu.
Étape 1: Installez le kit de développement Java
Java est un composant nécessaire d'Apache Hadoop, vous devez donc télécharger et installer un kit de développement Java sur tous les nœuds de votre réseau où Hadoop sera installé. Vous pouvez télécharger le JRE ou JDK. Si vous cherchez seulement à exécuter Hadoop, alors JRE est suffisant, mais si vous voulez créer des applications qui s'exécutent sur Hadoop, vous devrez installer le JDK. La dernière version de Java que Hadoop prend en charge est Java 8 et 11. Vous pouvez le vérifier sur le site Web d'Apache et télécharger la version pertinente de Java en fonction de votre système d'exploitation.
- Les référentiels Ubuntu par défaut contiennent Java 8 et Java 11 tous deux. Utilisez la commande suivante pour l'installer.
Sudo Apt Update && sudo apt install openjdk-11-jdk - Une fois que vous l'avez installé avec succès, vérifiez la version Java actuelle:
Java-Version Vérifiez la version Java
Vérifiez la version Java - Vous pouvez trouver l'emplacement du répertoire Java_Home en exécutant la commande suivante. Qui sera nécessaire la dernière dans cet article.
dirname $ (dirname $ (readLink -f $ (qui java))) Vérifiez l'emplacement de Java_Home
Vérifiez l'emplacement de Java_Home
Étape 2: Créer un utilisateur pour Hadoop
Tous les composants Hadoop s'exécuteront en tant qu'utilisateur que vous créez pour Apache Hadoop, et l'utilisateur sera également utilisé pour vous connecter à l'interface Web de Hadoop. Vous pouvez créer un nouveau compte utilisateur avec la commande «sudo» ou vous pouvez créer un compte utilisateur avec des autorisations «root». Le compte d'utilisateur avec les autorisations racine est plus sécurisé mais peut ne pas être aussi pratique pour les utilisateurs qui ne connaissent pas la ligne de commande.
- Exécutez la commande suivante pour créer un nouvel utilisateur avec le nom "Hadoop":
sudo addUser Hadoop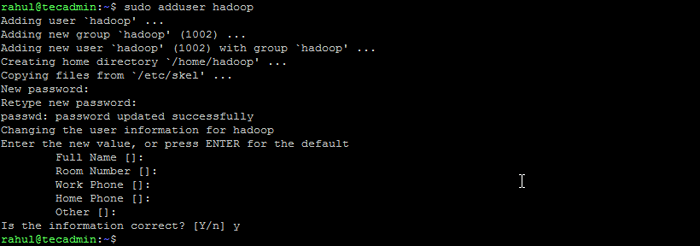 Créer un utilisateur Hadoop
Créer un utilisateur Hadoop - Passez à l'utilisateur Hadoop nouvellement créé:
su - Hadoop - Configurez maintenant l'accès SSH sans mot de passe pour l'utilisateur Hadoop nouvellement créé. Générez d'abord une cave SSH:
ssh-keygen -t rsa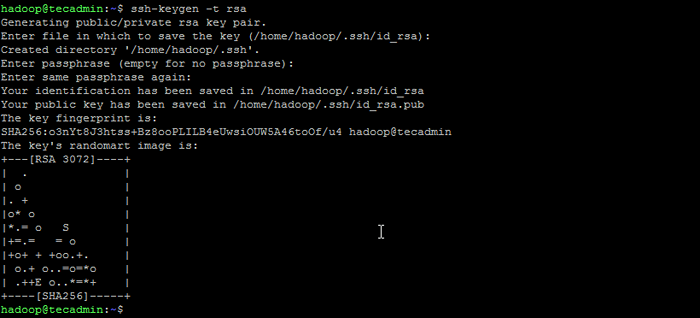 Générer la paire de clés SSH
Générer la paire de clés SSH - Copiez la clé publique générée dans le fichier de clé autorisé et définissez les autorisations appropriées:
chat ~ /.ssh / id_rsa.pub >> ~ /.SSH / AUTORISED_KEYSChmod 640 ~ /.SSH / AUTORISED_KEYS - Essayez maintenant de ssh au localhost.
ssh localhostIl vous sera demandé d'authentifier les hôtes en ajoutant des clés RSA aux hôtes connus. Tapez oui et appuyez sur Entrée pour authentifier le localhost:
 Connectez SSH à LocalHost
Connectez SSH à LocalHost
Étape 3: Installez Hadoop sur Ubuntu
Une fois que vous avez installé Java, vous pouvez télécharger Apache Hadoop et tous ses composants connexes, y compris Hive, Pig, Sqoop, etc. Vous pouvez trouver la dernière version de la page de téléchargement de Hadoop officielle. Assurez-vous de télécharger les archives binaires (pas la source).
- Utilisez la commande suivante pour télécharger Hadoop 3.3.4:
wget https: // dlcdn.apache.org / hadoop / commun / hadoop-3.3.4 / Hadoop-3.3.4.le goudron.gz - Une fois que vous avez téléchargé le fichier, vous pouvez le décompresser à un dossier sur votre disque dur.
tar xzf hadoop-3.3.4.le goudron.gz - Renommer le dossier extrait pour supprimer les informations de version. Il s'agit d'une étape facultative, mais si vous ne voulez pas renommer, ajustez les chemins de configuration restants.
mv hadoop-3.3.4 Hadoop - Ensuite, vous devrez configurer les variables d'environnement Hadoop et Java sur votre système. Ouvrez le ~ /.Fichier Bashrc dans votre éditeur de texte préféré:
nano ~ /.bashrcAjoutez les lignes ci-dessous au fichier. Vous pouvez trouver l'emplacement Java_Home en fonctionnant
export java_home = / usr / lib / jvm / java-11-openjdk-amd64 export hadoop_home = / home / hadoop / hadoop export hadoop_install = $ hadoop_home export hadoop_mapred_home = $ hadoop_home hadoop_comon_home = $ hadhome export_homyhyre_home_port_homax_home export_homa_home export_homa_home_port_home export_home_home export_home_port_home Export_homa_home Export_homa_home Export_homa_home Export_homa_home Export_homa_home Export_homa_home Export_homa_home Export_homa_ Hadoop_home export hadoop_common_lib_native_dir = $ hadoop_home / lib / natif export path = $ path: $ hadoop_home / sbin: $ hadoop_home / bin export hadoop_opts = "- djava.bibliothèque.path = $ hadoop_home / lib / natif "dirname $ (dirname $ (readLink -f $ (qui java)))commande sur le terminal.12345678910 export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64export HADOOP_HOME=/home/hadoop/hadoopexport HADOOP_INSTALL=$HADOOP_HOMEexport HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOMEexport HADOOP_HDFS_HOME=$HADOOP_HOMEexport HADOOP_YARN_HOME=$HADOOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/ lib / nativeExport path = $ path: $ hadoop_home / sbin: $ hadoop_home / binexport hadoop_opts = "- djava.bibliothèque.path = $ hadoop_home / lib / natif " Enregistrez le fichier et fermez-le.
- Chargez la configuration ci-dessus dans l'environnement actuel.
source ~ /.bashrc - Vous devez également configurer Java_home dans Hadoop-env.shot déposer. Modifiez le fichier de variables d'environnement Hadoop dans l'éditeur de texte:
nano $ hadoop_home / etc / hadoop / hadoop-env.shotRecherchez le «exportation java_home» et configurez-le avec la valeur trouvée à l'étape 1. Voir la capture d'écran ci-dessous:
 Définir Java_Home
Définir Java_HomeEnregistrez le fichier et fermez-le.
Étape 4: Configuration de Hadoop
Ensuite, il s'agit de configurer les fichiers de configuration Hadoop disponibles sous ETC.
- Tout d'abord, vous devrez créer le namenode et code de données Répertoires à l'intérieur du répertoire de la maison utilisateur de Hadoop. Exécutez la commande suivante pour créer les deux répertoires:
mkdir -p ~ / hadoopdata / hdfs / nameNode, datanode - Ensuite, modifiez le site de base.xml fichier et mettre à jour avec le nom d'hôte de votre système:
nano $ hadoop_home / etc / hadoop / core-site.xmlModifiez le nom suivant selon le nom d'hôte de votre système:
FS.defaultfs hdfs: // localhost: 9000123456 FS.defaultfs hdfs: // localhost: 9000 Enregistrez et fermez le fichier.
- Ensuite, modifiez le site HDFS.xml déposer:
nano $ hadoop_home / etc / hadoop / hdfs-site.xmlModifiez les chemins de répertoire Namenode et Datanode comme indiqué ci-dessous:
DFS.réplication 1 DFS.nom.DIR FILE: /// home / hadoop / hadoopdata / hdfs / namenode dfs.données.DIR FILE: /// home / hadoop / hadoopdata / hdfs / datanode12345678910111213141516 DFS.réplication 1 DFS.nom.DIR FILE: /// home / hadoop / hadoopdata / hdfs / namenode dfs.données.DIR FILE: /// home / hadoop / hadoopdata / hdfs / datanode Enregistrez et fermez le fichier.
- Ensuite, modifiez le site mapred.xml déposer:
nano $ hadoop_home / etc / hadoop / mapred site.xmlApporter les modifications suivantes:
mapreduce.cadre.Nommez le fil123456 mapreduce.cadre.Nommez le fil Enregistrez et fermez le fichier.
- Ensuite, modifiez le Site de fil.xml déposer:
nano $ hadoop_home / etc / hadoop / yarn-site.xmlApporter les modifications suivantes:
fil.nodemanager.Aux-Services MapReduce_Shuffle123456 fil.nodemanager.Aux-Services MapReduce_Shuffle Enregistrez le fichier et fermez-le.
Étape 5: Démarrez le cluster Hadoop
Avant de commencer le cluster Hadoop. Vous devrez formater le namenode en tant qu'utilisateur Hadoop.
- Exécutez la commande suivante pour formater le hadoop namenode:
hdfs namenode -formatUne fois que le répertoire Namenode est formaté avec succès avec le système de fichiers HDFS, vous verrez le message "Le répertoire de stockage / Home / Hadoop / HadoopData / HDFS / Namenode a été formaté avec succès".
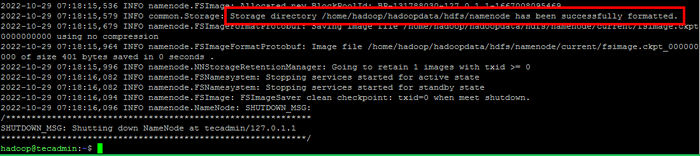 Format namenode
Format namenode - Puis démarrez le cluster Hadoop avec la commande suivante.
démarrer.shot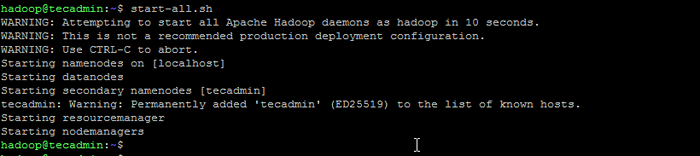 Démarrer les services Hadoop
Démarrer les services Hadoop - Une fois que tous les services ont commencé, vous pouvez accéder au Hadoop à: http: // localhost: 9870

- Et la page d'application Hadoop est disponible sur http: // localhost: 8088

Conclusion
L'installation d'Apache Hadoop sur Ubuntu peut être une tâche délicate pour les débutants, surtout s'ils ne suivent que les instructions de la documentation. Heureusement, cet article fournit un guide étape par étape qui vous aidera à installer Apache Hadoop sur Ubuntu avec facilité. Tout ce que vous avez à faire est de suivre les instructions répertoriées dans cet article, et vous pouvez être sûr que votre installation de Hadoop sera opérationnelle en un rien de temps.