

Comment installer Apache Kafka sur Centos 8

- 1470
- 48
- Lucas Bernard
Apache Kafka est une plate-forme de streaming distribuée. Il est utile pour créer des pipelines de données de streaming en temps réel pour obtenir des données entre les systèmes ou les applications. Une autre caractéristique utile est les applications de streaming en temps réel qui peuvent transformer des flux de données ou réagir sur un flux de données.
Ce tutoriel vous aidera à installer Apache Kafka Centos 8 ou Rhel 8 Linux Systems.
Conditions préalables
- Le système nouvellement installé est recommandé de suivre la configuration initiale du serveur.
- Accès à la coque au système CentOS 8 avec le compte privilèges sudo.
Étape 1 - Installer Java
Vous devez faire installer Java sur votre système pour exécuter Apache Kafka. Vous pouvez installer OpenJDK sur votre machine en exécutant la commande suivante. Installez également d'autres outils requis.
sudo dnf installer java-11-openjdk wget vim Étape 2 - Télécharger Apache Kafka
Téléchargez les fichiers binaires Apache Kafka à partir de son site Web officiel de téléchargement. Vous pouvez également sélectionner n'importe quel miroir à proximité à télécharger.
wget https: // dlcdn.apache.org / kafka / 3.2.0 / kafka_2.13-3.2.0.tgz Puis extraire le fichier d'archive
Tar XZF Kafka_2.13-3.2.0.tgzsudo mv kafka_2.13-3.2.0 / usr / local / kafka
Étape 3 - Configuration des fichiers d'unité Kafka Systemd
Centos 8 utilise Systemd pour gérer son état de services. Nous devons donc créer des fichiers d'unité Systemd pour le service Zookeeper et Kafka. Ce qui nous aide à gérer les services Kafka pour démarrer / arrêter.
Tout d'abord, créez un fichier unitaire Systemd pour ZooKeeper avec la commande ci-dessous:
vim / etc / systemd / system / zookeeper.service
Ajouter ci-dessous contnet:
[Unité] Description = Apache ZooKeeper Server Documentation = http: // ZooKeeper.apache.org requiert = réseau.Target Remote-FS.cible après = réseau.Target Remote-FS.Target [service] type = simple execstart = / usr / bin / bash / usr / local / kafka / bin / zookeeper-server-start.sh / usr / local / kafka / config / zookeeper.Propriétés execstop = / usr / bin / bash / usr / local / kafka / bin / zookeeper-server-stop.sh redémarrer = en borne [installation] WantedBy = Multi-utilisateur.cible
Enregistrez le fichier et fermez-le.
Ensuite, pour créer un fichier unitaire Kafka Systemd en utilisant la commande suivante:
vim / etc / systemd / system / kafka.service
Ajouter le contenu ci-dessous. Assurez-vous de définir le bon Java_home chemin selon le java installé sur votre système.
[Unité] Description = Apache Kafka Server Documentation = http: // kafka.apache.org / documentation.html requiert = zookeeper.service [service] type = Simple Environment = "java_home = / usr / lib / jvm / jre-11-openjdk" execstart = / usr / bin / bash / usr / local / kafka / bin / kafka-start-start.sh / usr / local / kafka / config / serveur.Propriétés execstop = / usr / bin / bash / usr / local / kafka / bin / kafka-server-stop.sh [installer] recherché = multi-utilisateurs.cible
Enregistrez le fichier et fermez-le.
Recharger le démon systemd pour appliquer les modifications.
Systemctl Daemon-Reload
Étape 4 - Démarrez le serveur Kafka
Kafka a besoin de zookeeper alors d'abord, démarrez un serveur de gardien de zoo sur votre système. Vous pouvez utiliser le script disponible avec Kafka pour démarrer une instance de Zookeeper à un nœud.
sudo systemctl start zookeeper
Démarrez maintenant le serveur Kafka et affichez l'état d'exécution:
sudo systemctl start kafka sudo systemctl status kafka
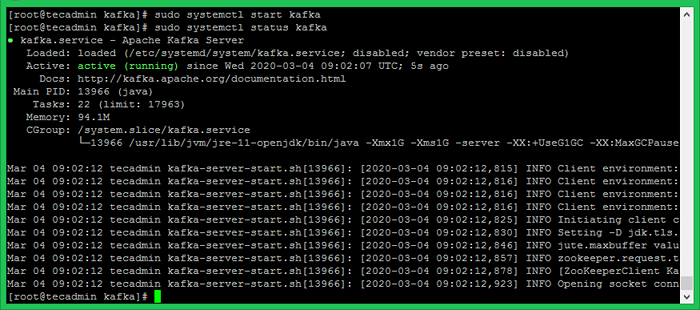
Terminé. Vous avez réussi à installer Kafka sur votre centos 8. La prochaine partie de ce tutoriel vous aidera à créer des sujets dans le cluster Kafka et à travailler avec le producteur Kafka et le service de consommation.
Étape 5 - Création de sujets dans Apache Kafka
Apache Kafka fournit plusieurs scripts shell pour y travailler. Tout d'abord, créez un sujet nommé «testtopique”Avec une seule partition avec une seule réplique:
CD / USR / Local / Kafka Bin / Kafka-Topics.sh --create --bootstrap-server localhost: 9092 - Réplication-Factor 1 - Partitions 1 - Topic créé TestTopic TestTopic.
Le facteur de réplication décrit combien de copies de données seront créées. Au fur et à mesure que nous fonctionnons avec une seule instance, gardez cette valeur 1.
Définissez les options de partitions comme le nombre de courtiers que vous souhaitez que vos données soient divisées entre. Comme nous courons avec un seul courtier, gardez cette valeur 1.
Vous pouvez créer plusieurs sujets en exécutant la même commande que ci-dessus. Après cela, vous pouvez voir les sujets créés sur Kafka par la commande en cours d'exécution ci-dessous:
bac / kafka-topics.SH --List --zookeeper localhost: 9092 Testtopic kafkaoncentos8 tutorialkafkainstallcentos8
Alternativement, au lieu de créer manuellement des sujets, vous pouvez également configurer vos courtiers pour créer automatiquement des sujets lorsqu'un sujet inexistant est publié pour.
Étape 6 - Producteur et consommateur d'Apache Kafka
Le «producteur» est le processus responsable de la mise en place de données dans notre Kafka. Le Kafka est livré avec un client en ligne de commande qui prendra les commentaires d'un fichier ou de l'entrée standard et l'envoie comme messages au cluster Kafka. Le Kafka par défaut envoie chaque ligne en tant que message séparé.
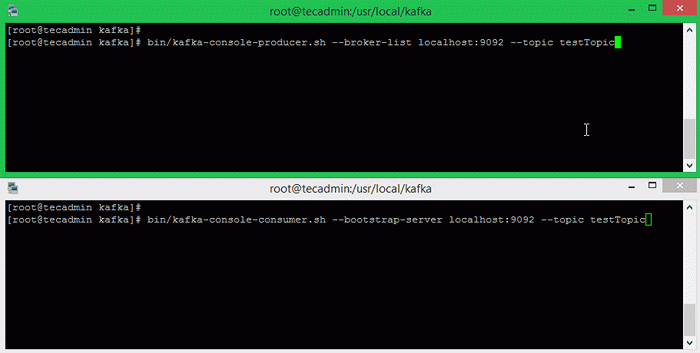
Exécutons le producteur, puis tapons quelques messages dans la console pour envoyer au serveur.
bac / kafka-console producteur.SH - Broker-list localhost: 9092 - Testtopic topic> Bienvenue à Kafka> Ceci est mon premier sujet>
Ouvre maintenant un nouveau terminal pour exécuter le processus de consommation Apache Kafka. Kafka fournit également et le consommateur de ligne de commande pour lire les données du cluster Kafka et afficher des messages à la sortie standard.
bac / kafka-consoleur.SH --bootstrap-server localhost: 9092 - Testtopic topic --in-beginning bienvenue à kafka c'est mon premier sujet
L'option -from-beginning est utilisée pour lire les messages depuis le début du sujet sélectionné. Vous pouvez ignorer cette option pour lire les derniers messages uniquement.
Par exemple, exécutez le producteur et le consommateur de Kafka dans les terminaux séparés. Tapez simplement du texte sur ce terminal producteur. il sera immédiatement visible sur le terminal de consommation. Voir la capture d'écran ci-dessous du producteur et des consommateurs de Kafka en travaillant:
Conclusion
Vous avez réussi et configuré le service Kafka sur la machine CentOS 8 Linux.
- « Comment installer Owncloud sur Debian 10 (Buster)
- Comment ouvrir le port 80 et 443 dans Firewalld »