

Comment installer Elasticsearch, Logstash et Kibana (Elk Stack) sur Centos / Rhel 7

- 1852
- 165
- Jade Muller
Si vous êtes une personne qui est ou qui a été dans le passé, en charge d'inspecter et d'analyser les journaux système à Linux, vous savez quel cauchemar cette tâche peut devenir si plusieurs services sont surveillés simultanément.
Au cours des jours passés, cette tâche devait être effectuée principalement manuellement, chaque type de journal étant géré séparément. Heureusement, la combinaison de Elasticsearch, Trottoir, et Kibana du côté du serveur, avec File Côté client, rend cette tâche autrefois difficile à ressembler à une promenade dans le parc aujourd'hui.
Les trois premiers composants forment ce qu'on appelle un WAPITI Stack, dont le but principal est de collecter des journaux de plusieurs serveurs en même temps (également connu sous le nom de journalisation centralisée).
Lire suggérée: 4 Bonnes outils de surveillance et de gestion du journal open source pour Linux
Une interface Web basée sur Java intégrée vous permet d'inspecter rapidement les journaux en un coup d'œil pour une comparaison et un dépannage plus faciles. Ces journaux clients sont envoyés à un serveur central par File, qui peut être décrit comme un agent d'expédition en journaux.
Voyons comment toutes ces pièces s'adaptent. Notre environnement de test comprendra les machines suivantes:
Serveur central: Centos 7 (Adresse IP: 192.168.0.29). 2 Go de Ram. Client # 1: Centos 7 (Adresse IP: 192.168.0.100). 1 Go de Ram. Client n ° 2: Debian 8 (Adresse IP: 192.168.0.101). 1 Go de Ram.
Veuillez noter que le RAM Les valeurs fournies ici ne sont pas des conditions préalables strictes, mais les valeurs recommandées pour une mise en œuvre réussie de la WAPITI empiler sur le serveur central. Moins RAM sur les clients ne fera pas beaucoup de différence, le cas échéant,.
Installation de la pile de wapitis sur le serveur
Commençons par installer le WAPITI Stack sur le serveur, ainsi qu'une brève explication sur ce que fait chaque composant:
- Elasticsearch Stocke les journaux envoyés par les clients.
- Trottoir traite ces journaux.
- Kibana Fournit l'interface Web qui nous aidera à inspecter et à analyser les journaux.
Installez les packages suivants sur le serveur central. Tout d'abord, nous installerons Java JDK version 8 (mise à jour 102, le dernier au moment de la rédaction de cet article), qui est une dépendance de la WAPITI Composants.
Vous voudrez peut-être vérifier d'abord dans la page de téléchargements Java ici pour voir s'il y a une mise à jour plus récente disponible.
# mim mise à jour # cd / opt # wget --no-cookies --no-cocheck-certificate --header "cookie: gpw_e24 = http% 3a% 2f% 2fwww.oracle.com% 2f; OraceLicense = Accept-SecureBackup-Cookie "" http: // Télécharger.oracle.com / otn-pub / java / jdk / 8u102-b14 / jre-8u102-linux-x64.RPM "# RPM -UVH JRE-8U102-LINUX-X64.RPM
Il est temps de vérifier si l'installation s'est terminée avec succès:
# Java -Version
 Vérifiez la version Java de Commandline
Vérifiez la version Java de Commandline Pour installer les dernières versions de Elasticsearch, Trottoir, et Kibana, Nous devrons créer des référentiels pour Miam manuellement comme suit:
Activer le référentiel Elasticsearch
1. Importez la clé GPG publique Elasticsearch au RPM Package Manager:
# RPM - Import http: // packages.élastique.co / gpg-key-elasticsearch
2. Insérez les lignes suivantes dans le fichier de configuration du référentiel Elasticsearch.repo:
[elasticsearch] name = Elasticsearch Repository BasiseUrl = http: // packages.élastique.co / elasticsearch / 2.x / Centos gpgcheck = 1 gpgkey = http: // packages.élastique.co / gpg-key-elasticsearch activé = 1
3. Installez le package Elasticsearch.
# yum install elasticsearch
Une fois l'installation terminée, vous serez invité à démarrer et à activer Elasticsearch:
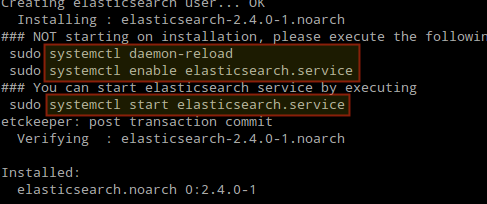 Installez Elasticsearch dans Linux
Installez Elasticsearch dans Linux 4. Démarrer et activer le service.
# systemctl daemon-reload # systemctl activer elasticsearch # systemctl start elasticsearch
5. Autoriser le trafic via le port TCP 9200 Dans votre pare-feu:
# Firewall-CMD --Add-Port = 9200 / TCP # Firewall-CMD --Add-Port = 9200 / TCP --permanent
6. Vérifier si Elasticsearch répond aux demandes simples sur Http:
# curl -x get http: // localhost: 9200
La sortie de la commande ci-dessus doit être similaire à:
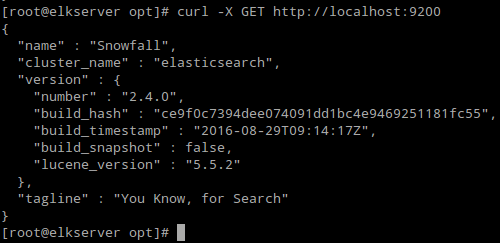 Vérifiez l'installation d'Elasticsearch
Vérifiez l'installation d'Elasticsearch Assurez-vous de terminer les étapes ci-dessus, puis de poursuivre Trottoir. Depuis les deux Trottoir et Kibana Partage le Elasticsearch gpg Clé, il n'est pas nécessaire de le réimportant avant d'installer les packages.
Lire suggérée: Gérer les journaux système (configurer, tourner et importer dans la base de données) dans CentOS 7
Activer le référentiel Logstash
7. Insérez les lignes suivantes dans le fichier de configuration du référentiel trottoir.repo:
[Logstash] name = logstash bunterl = http: // packages.Elasticsearch.org / logstash / 2.2 / CentOS gpgcheck = 1 gpgkey = http: // packages.Elasticsearch.org / gpg-key-elasticsearch activé = 1
8. Installer le Trottoir emballer:
# Yum Installer Logstash
9. Ajouter un SSL certificat basé sur l'adresse IP du serveur de wapitis sur la ligne suivante en dessous du [v3_ca] sectionner / etc / pki / tls / openssl.CNF:
[V3_CA] SubteralTName = IP: 192.168.0.29
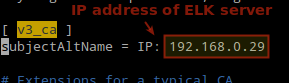 Ajouter l'adresse IP du serveur Elasticsearch
Ajouter l'adresse IP du serveur Elasticsearch dix. Générer un certificat auto-signé comme 365 jours:
# cd / etc / pki / tls # openssl req -config / etc / pki / tls / openssl.CNF -X509 -Days 3650 -Batch -Nodes -Newkey RSA: 2048 -Keyout Private / Logstash-Forwardener.Key -out Certs / Logstash-Forwardor.CRT
11. Configurer Trottoir Fichiers d'entrée, de sortie et de filtre:
Saisir: Créer / etc / Logstash / Conf.d / entrée.confli et insérez les lignes suivantes. Ceci est nécessaire pour que Logstash soit «apprendre"Comment traiter les battements provenant des clients. Assurez-vous que le chemin vers le certificat et la clé correspondent aux bons chemins comme indiqué à l'étape précédente:
Input Beats port => 5044 ssl => true ssl_certificate => "/ etc / pki / tls / certs / logstash-forwardor.crt "ssl_key =>" / etc / pki / tls / private / logstash-forwardor.clé"
Sortir (/ etc / Logstash / Conf.d / sortie.confli) déposer:
Output elasticsearch hosts => ["localhost: 9200"] sniffing => true manage_template => false index => "% [@ métadata] [beat] -% + yyyy.MM.dd "document_type =>"% [@ métadonnées] [type] "
Filtre (/ etc / Logstash / Conf.d / filtre.confli) déposer. Nous enregistrerons des messages syslog pour la simplicité:
Filter if [type] == "Syslog" Grok Match => "Message" => "% syslogline" date match => ["TimeStamp", "Mmm D HH: MM: SS" , "MMM DD HH: MM: SS"]
12. Vérifiez le Trottoir fichiers de configuration.
# Service Logstash ConfigTest
 Vérifiez la configuration de Logstash
Vérifiez la configuration de Logstash 13. Démarrer et activer Logstash:
# SystemCTL Daemon-Recload # SystemCTl Start Logstash # SystemCTL Activer Logstash
14. Configurez le pare-feu pour permettre à Logstash d'obtenir les journaux des clients (port TCP 5044):
# Firewall-CMD --Add-Port = 5044 / TCP # Firewall-CMD --Add-Port = 5044 / TCP - Permanent
Activer le référentiel Kibana
14. Insérez les lignes suivantes dans le fichier de configuration du référentiel kibana.repo:
[kibana] name = kibana repository baliseUrl = http: // packages.élastique.co / kibana / 4.4 / CentOS gpgcheck = 1 gpgkey = http: // packages.élastique.co / gpg-key-elasticsearch activé = 1
15. Installer le Kibana emballer:
# yum install kibana
16. Commencez et activez Kibana.
# SystemCTL Daemon-RELOAD # SystemCTL Start Kibana # SystemCTL Activer Kibana
17. Assurez-vous que vous pouvez accéder à l'accès à l'interface Web de Kibana depuis un autre ordinateur (autorisez le trafic sur le port TCP 5601):
# Firewall-CMD --Add-Port = 5601 / TCP # Firewall-CMD --Add-Port = 5601 / TCP - Permanent
18. Lancement Kibana (http: // 192.168.0.29: 5601) Pour vérifier que vous pouvez accéder à l'interface Web:
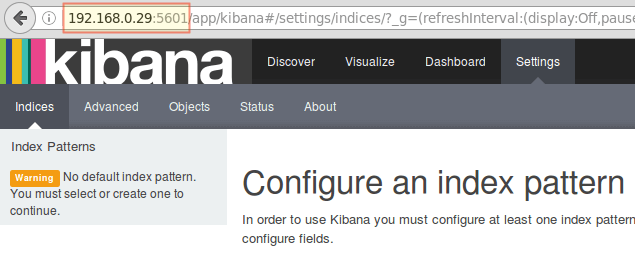 Accédez à l'interface Web de Kibana
Accédez à l'interface Web de Kibana Nous reviendrons ici après avoir installé et configuré File sur les clients.
Lire suggérée: Surveiller les journaux du serveur en temps réel avec «journal.outil io ”dans Linux
Installez Filebeat sur les serveurs clients
Nous vous montrerons comment faire cela pour Client # 1 (répéter pour Client n ° 2 Ensuite, modification des chemins, le cas échéant, à votre distribution).
1. Copiez le certificat SSL du serveur aux clients:
# SCP / ETC / PKI / TLS / CERTS / LOGSTASH-FORWARDER.CRT [e-mail protégé]: / etc / pki / tls / certs /
2. Importer le Elasticsearch Clé GPG public au gestionnaire de packages RPM:
# RPM - Import http: // packages.élastique.co / gpg-key-elasticsearch
3. Créer un référentiel pour File (/ etc / yum.se soustraire.d / filebeat.repo) dans Centos Distributions basées:
[filebeat] name = filebeat for elk Clients bunterl = https: // packages.élastique.CO / Beats / Yum / El / $ Basearch activé = 1 gpgkey = https: // packages.élastique.co / gpg-key-elasticsearch gpgcheck = 1
4. Configurer la source pour installer Filebeat sur Debian et ses dérivés:
# aptitude installer apt-transport-https # echo "Deb https: // packages.élastique.CO / BEATS / APT STABLE Principal "> / etc / apt / sources.liste.d / filebeat.Liste # mise à jour d'aptitude
5. Installer le File emballer:
# yum install filebeat [on Centos et distribution basée] # aptitude installer filebeat [sur Debian et ses dérivés]
6. Démarrer et activer Filebeat:
# systemctl start filebeat # systemctl activer filebeat
Configurer Filebeat
Un mot de prudence ici. File La configuration est stockée dans un Yaml fichier, qui nécessite une indentation stricte. Soyez prudent avec cela lorsque vous modifiez / etc / filebeat / filebeat.YML comme suit:
- Sous chemins, Indiquez quels fichiers journaux doivent être «expédiés» sur le serveur de wapiti.
- Sous prospecteurs:
input_type: journal document_type: syslog
- Sous sortir:
- Décommente la ligne qui commence par trottoir.
- Indiquez l'adresse IP de votre serveur de wapiti et de votre port où la logstash écoute dans hôtes.
- Assurez-vous que le chemin d'accès vers le certificat pointe vers le fichier réel dans lequel vous avez créé Étape I (Trottoir Section) ci-dessus.
Les étapes ci-dessus sont illustrées dans l'image suivante:
 Configurer Filebeat dans les serveurs clients
Configurer Filebeat dans les serveurs clients Enregistrer les modifications, puis redémarrer File sur les clients:
# systemctl redémarrer filebeat
Une fois que nous aurons terminé les étapes ci-dessus sur les clients, n'hésitez pas à continuer.
Tester Filebeat
Afin de vérifier que les journaux des clients peuvent être envoyés et reçus avec succès, exécutez la commande suivante sur le WAPITI serveur:
# curl -xget 'http: // localhost: 9200 / filebeat - * / _ Search?joli'
La sortie doit être similaire à (remarquez comment les messages de / var / log / messages et / var / log / sécurisé sont reçus de Client1 et client2):
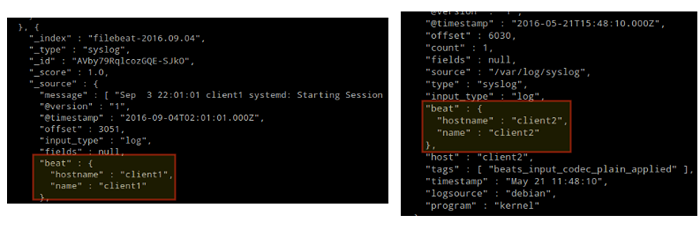 Tester Filebeat
Tester Filebeat Sinon, vérifiez le File Fichier de configuration pour les erreurs.
# journalctl -XE
Après avoir tenté de redémarrer Filebeat, vous indiquera la ligne (s) incriminée (s).
Tester Kibana
Après avoir vérifié que les journaux sont expédiés par les clients et reçus avec succès sur le serveur. La première chose que nous devrons faire Kibana Configure un modèle d'index et le définit par défaut.
Vous pouvez décrire un index comme une base de données complète dans un contexte de base de données relationnelle. Nous irons avec filebeat- * (ou vous pouvez utiliser un critère de recherche plus précis comme expliqué dans la documentation officielle).
Entrer filebeat- * dans le Nom d'index ou champ de motif puis cliquez Créer:
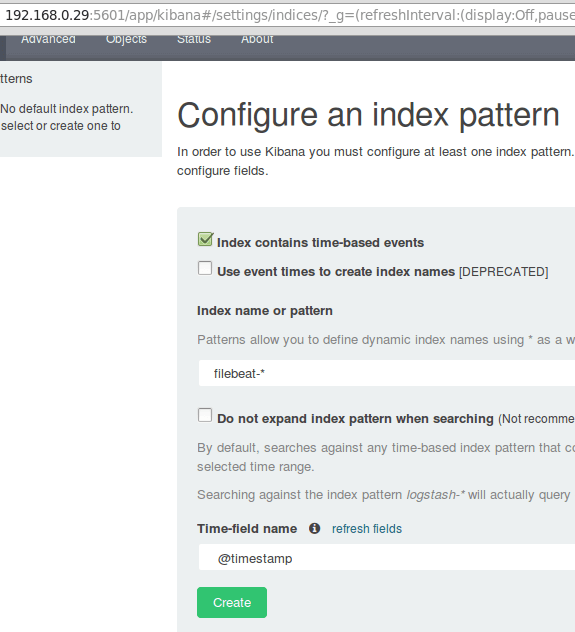 Tester Kibana
Tester Kibana Veuillez noter que vous serez autorisé à saisir un critère de recherche plus fin. Ensuite, cliquez sur l'étoile à l'intérieur du rectangle vert pour le configurer comme modèle d'index par défaut:
 Configurer le modèle d'index Kibana par défaut
Configurer le modèle d'index Kibana par défaut Enfin, dans le Découvrir menu Vous trouverez plusieurs champs à ajouter au rapport de visualisation du journal. Planer juste sur eux et cliquer Ajouter:
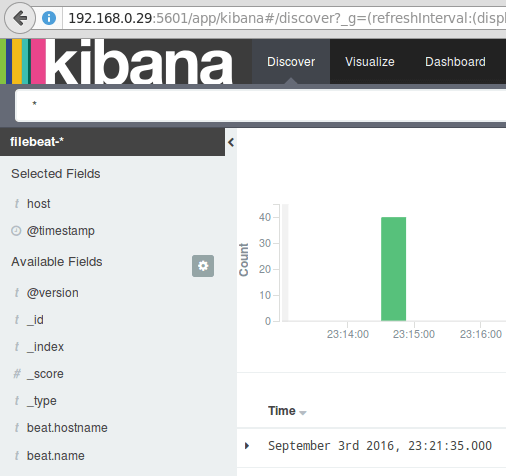 Ajouter un rapport de visualisation du journal
Ajouter un rapport de visualisation du journal Les résultats seront indiqués dans la zone centrale de l'écran comme indiqué ci-dessus. N'hésitez pas à jouer (ajouter et supprimer les champs du rapport du journal) pour se familiariser avec Kibana.
Par défaut, Kibana affichera les enregistrements qui ont été traités pendant le dernier 15 Minutes (voir le coin supérieur droit) mais vous pouvez modifier ce comportement en sélectionnant un autre calendrier:
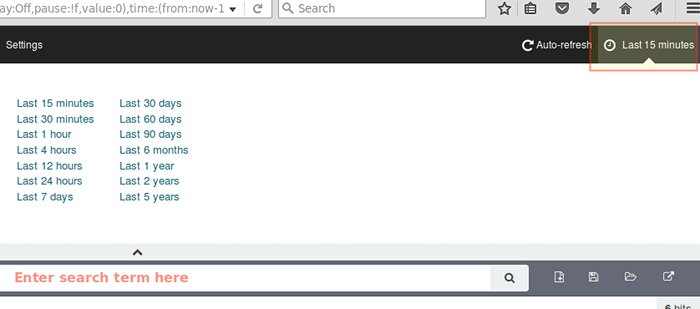 Rapports du journal Kibana
Rapports du journal Kibana Résumé
Dans cet article, nous avons expliqué comment configurer une pile de wapitis pour collecter les journaux système envoyés par deux clients, un CentOS 7 et une machines Debian 8.
Vous pouvez maintenant vous référer à la documentation officielle Elasticsearch et trouver plus de détails sur la façon d'utiliser cette configuration pour inspecter et analyser vos journaux plus efficacement.
Si vous avez des questions, n'hésitez pas à demander. Nous avons hâte d'avoir de tes nouvelles.
- « La vérité de Python et Perl - Caractéristiques, avantages et inconvénients discutés
- Comment créer et exécuter de nouvelles unités de service dans Systemd en utilisant Shell Script »