

Comment installer Elasticsearch (Multi Node) Cluster sur Centos / Rhel, Ubuntu & Debian

- 977
- 22
- Emilie Colin
Elasticsearch est flexible et puissant open source, distribué de recherche en temps réel et moteur analytique. En utilisant un ensemble simple d'API, il offre la possibilité d'une recherche en texte intégral. La recherche élastique est disponible librement sous la licence Apache 2, qui offre la plupart des flexibilité.
Cet article vous aidera à configurer Elasticsearch Multi Node Cluster sur Centos, Rhel, Ubuntu et Debian Systems. Dans Elasticsearch, le cluster multi-nœuds ne fait que configurer plusieurs clusters de nœuds uniques avec le même nom de cluster dans le même réseau.
Scénario de réseau
Nous avons trois serveur avec les IP et les noms d'hôtes suivants. Tous les serveurs s'exécutent dans le même LAN et ont un accès complet aux autres serveur à l'aide de IP et du nom d'hôte.
192.168.dix.101 Node_1 192.168.dix.102 Node_2 192.168.dix.103 Node_3
Vérifiez Java (tous les nœuds)
Java est la principale exigence pour installer Elasticsearch. Alors assurez-vous que Java soit installé sur tous les nœuds.
# Java -Version Java Version "1.8.0_31 "Java (TM) SE Runtime Environment (Build 1.8.0_31-b13) Java Hotspot (TM) VM du serveur 64 bits (build 25.31-B07, mode mixte)
Si vous n'avez pas installé Java sur aucun système de nœuds, utilisez l'un des liens suivants pour l'installer d'abord.
Installer Java 8 sur Centos / Rhel 7/6/5
Installez Java 8 sur Ubuntu
Télécharger Elasticsearch (tous les nœuds)
Maintenant, téléchargez maintenant la dernière archive Elasticsearch sur tous les systèmes de nœuds à partir de sa page de téléchargement officielle. Au moment de la dernière mise à jour de cet article Elasticsearch 1.4.2 version est la dernière version disponible en téléchargement. Utilisez la commande suivante pour télécharger Elasticsearch 1.4.2.
$ wget https: // télécharger.Elasticsearch.org / elasticsearch / elasticsearch / elasticsearch-1.4.2.le goudron.gz
Extraire maintenant Elasticsearch sur tous les systèmes de nœuds.
$ tar xzf elasticsearch-1.4.2.le goudron.gz
Configurer elasticsearch
Nous devons maintenant configurer Elasticsearch sur tous les systèmes de nœuds. Elasticsearch utilise «Elasticsearch» comme nom de cluster par défaut. Nous vous recommandons de le changer selon votre conversation de dénomination.
$ mv elasticsearch-1.4.2 / usr / share / elasticsearch $ cd / usr / share / elasticsearch
Pour changer de cluster nommé Modifier config / elasticsearch.YML fichier dans chaque nœud et mettre à jour les valeurs suivantes. Les noms de nœud sont générés dynamiquement, mais pour garder un nom fixe convivial, changez-le également.
Sur node_1
Modifier la configuration du cluster Elasticsearch sur Node_1 (192.168.dix.101) Système.
$ vim config / elasticsearch.YML
grappe.Nom: Node de TecadMincCluster.Nom: "Node_1"
Sur node_2
Modifier la configuration du cluster Elasticsearch sur Node_2 (192.168.dix.102) Système.
$ vim config / elasticsearch.YML
grappe.Nom: Node de TecadMincCluster.Nom: "Node_2"
Sur node_3
Modifier la configuration du cluster Elasticsearch sur Node_3 (192.168.dix.103) Système.
$ vim config / elasticsearch.YML
grappe.Nom: Node de TecadMincCluster.Nom: "Node_3"
Installez le plugin Elasticsearch-Head (tous les nœuds)
Elasticsearch-Head est un frontal Web pour naviguer et interagir avec un cluster de recherche élastique. Utilisez la commande suivante pour installer ce plugin sur tous les systèmes de nœuds.
$ bin / plugin - Installation mobz / elasticsearch-head
Démarrage du cluster Elasticsearch (tous les nœuds)
Comme la configuration du cluster Elasticsearch a été terminée. Laissez démarrer le cluster Elasticsearch en utilisant la commande suivante sur tous les nœuds.
$ ./ bin / elasticsearch &
Par défaut ElasticSerch, écoutez sur le port 9200 et 9300. Alors connectez-vous à Node_1 Sur le port 9200 comme URL suivant, vous verrez les trois nœuds de votre cluster.
http: // node_1: 9200 / _plugin / head /
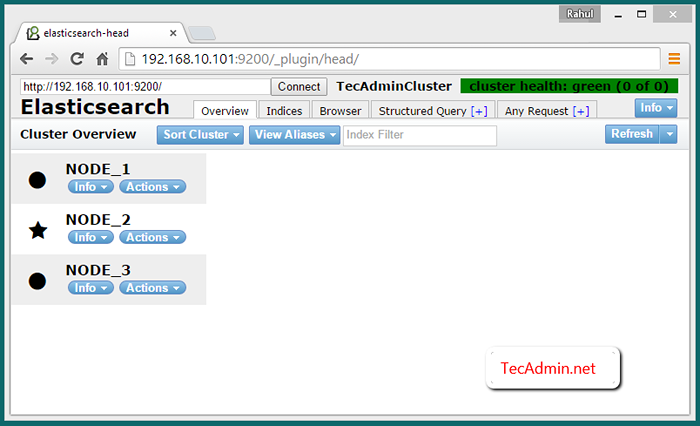
Vérifiez le cluster multi-nœuds
Pour vérifier que le cluster fonctionne correctement. Insérez certaines données dans un nœud et si les mêmes données sont disponibles dans d'autres nœuds, cela signifie que le cluster fonctionne correctement.
Insérer des données sur Node_1
Pour vérifier le cluster, créez un seau dans Node_1 et ajouter des données.
$ curl -xput http: // node_1: 9200 / mybucket $ curl -xput 'http: // node_1: 9200 / mybucket / user / rahul' -d '"name": "Rahul kumar"'
$ curl -xput 'http: // node_1: 9200 / mybucket / post / 1' -d '"user": "Rahul", "postdate": "01-16-2015", "body": "ajout de données Dans Elasticsearch Cluster "," Title ":" Elasticsearch Cluster Test " '
Rechercher des données sur tous les nœuds
Recherchez maintenant les mêmes données à partir de Node_2 et Node_3 et vérifier si les mêmes données sont reproduites à d'autres nœuds de cluster. Selon les commandes ci-dessus, nous avons créé un utilisateur nommé Rahul et ajouté quelques données là-bas. Utilisez donc les commandes suivantes pour rechercher les données associées à l'utilisateur Rahul.
$ curl 'http: // node_1: 9200 / mybucket / post / _search?Q = utilisateur: Rahul & pretty = true '$ curl' http: // node_2: 9200 / mybucket / post / _search?Q = utilisateur: Rahul & pretty = true '$ curl' http: // node_3: 9200 / mybucket / post / _search?Q = utilisateur: Rahul & Pretty = true '
Et vous obtiendrez des résultats quelque chose comme ci-dessous pour toutes les commandes ci-dessus.
? " : 1.0, "Hits": ["_index": "mybucket", "_type": "post", "_id": "1", "_score": 1.0, "_Source": "User": "Rahul", "postdate": "01-16-2015", "Body": "Adding Data dans Elasticsearch Cluster", "Title": "Elasticsearch Cluster Test" ]
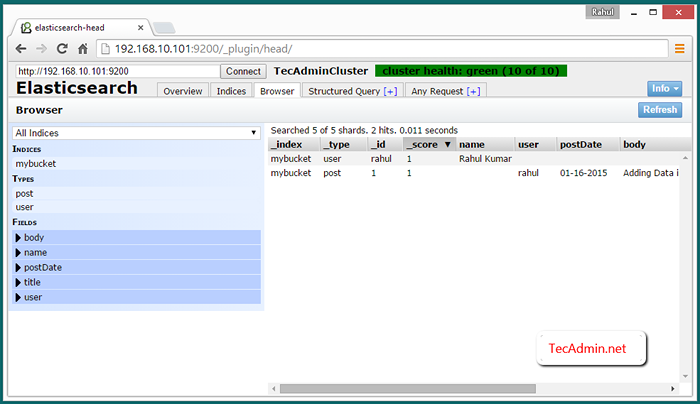
Afficher les données de cluster sur le navigateur Web
Pour afficher les données sur l'accès au cluster Elasticsearch du plugin Elasticsearch-head à l'aide de l'un des cluster IP sur URL ci-dessous. Puis cliquez sur Navigateur languette.
http: // node_1: 9200 / _plugin / head /
- « Comment utiliser la commande SystemCTL pour gérer les services SystemD
- Ajout de référentiel supplémentaire EPEL et REMI sur un système basé sur RHEL »