

Comment installer kafka sur rhel 8
- 4341
- 1
- Jade Muller
Apache Kafka est une plate-forme de streaming distribuée. Avec son API riche (interface de programmation d'application), nous pouvons connecter principalement n'importe quoi à Kafka comme source de données, et à l'autre bout, nous pouvons configurer un grand nombre de consommateurs qui recevront la vapeur des enregistrements pour le traitement. Kafka est très évolutive et stocke les flux de données d'une manière fiable et tolérante aux pannes. Du point de vue de la connectivité, Kafka peut servir de pont entre de nombreux systèmes hétérogènes, qui à son tour peuvent s'appuyer sur ses capacités de transférer et de persister les données fournies.
Dans ce tutoriel, nous installerons Apache Kafka sur une entreprise Red Hat Linux 8, créer systemd Fichiers unitaires pour faciliter la gestion et tester les fonctionnalités avec les outils de ligne de commande expédiés.
Dans ce tutoriel, vous apprendrez:
- Comment installer Apache Kafka
- Comment créer des services Systemd pour Kafka et Zookeeper
- Comment tester Kafka avec les clients de la ligne de commande
Consommer des messages sur le sujet de Kafka à partir de la ligne de commande. Exigences et conventions logicielles utilisées
| Catégorie | Exigences, conventions ou version logicielle utilisée |
|---|---|
| Système | Red Hat Enterprise Linux 8 |
| Logiciel | Apache Kafka 2.11 |
| Autre | Accès privilégié à votre système Linux en tant que racine ou via le Sudo commande. |
| Conventions | # - Exige que les commandes Linux soient exécutées avec des privilèges racine soit directement en tant qu'utilisateur racine, soit par l'utilisation de Sudo commande$ - Exige que les commandes Linux soient exécutées en tant qu'utilisateur non privilégié régulier |
Comment installer Kafka sur Redhat 8 instructions étape par étape
Apache Kafka est écrit en java, donc tout ce dont nous avons besoin est d'OpenJDK 8 installé pour poursuivre l'installation. Kafka s'appuie sur Apache Zookeeper, un service de coordination distribué, qui est également écrit en Java, et est expédié avec le package que nous allons télécharger. Lors de l'installation de services HA (High Disponibilité) à un seul nœud tue leur objectif, nous installerons et exécuterons Zookeeper pour le bien de Kafka.
- Pour télécharger Kafka à partir du miroir le plus proche, nous devons consulter le site de téléchargement officiel. Nous pouvons copier l'URL du
.le goudron.gzdossier à partir de là. Nous utiliseronswget, et l'URL collée pour télécharger le package sur la machine cible:# wget https: // www-eu.apache.org / dist / kafka / 2.1.0 / kafka_2.11-2.1.0.tgz -o / opt / kafka_2.11-2.1.0.tgz
- Nous entrons dans le
/opterrépertoire et extraire les archives:# CD / OPT # TAR -XVF KAFKA_2.11-2.1.0.tgz
Et créer un lien symbolique appelé
/ opt / kafkaqui pointe vers le maintenant créé/ opt / kafka_2_11-2.1.0Répertoire pour nous faciliter la vie.ln -s / opt / kafka_2.11-2.1.0 / opt / kafka
- Nous créons un utilisateur non privilégié qui exécutera les deux
gardien de zooetkafkaservice.# useradd kafka
- Et définir le nouvel utilisateur en tant que propriétaire de l'ensemble du répertoire que nous avons extrait, récursivement:
# chown -r kafka: kafka / opt / kafka *
- Nous créons le fichier unitaire
/ etc / Systemd / System / Zookeeper.serviceavec le contenu suivant:
Copie[Unité] Description = ZooKeeper After = syslog.réseau cible.Target [Service] type = utilisateur simple = groupe Kafka = Kafka execstart = / opt / kafka / bin / zookeeper-server-start.sh / opt / kafka / config / zookeeper.Propriétés execstop = / opt / kafka / bin / zookeeper-server-stop.sh [installer] recherché = multi-utilisateurs.cibleNotez que nous n'avons pas besoin d'écrire le numéro de version trois fois en raison du lien symbolique que nous avons créé. Il en va de même pour le fichier unitaire suivant pour Kafka,
/ etc / Systemd / System / Kafka.service, qui contient les lignes de configuration suivantes:
Copie[Unité] Description = Apache kafka requiert = zookeeper.Service After = ZooKeeper.service [service] type = utilisateur simple = groupe kafka = kafka execstart = / opt / kafka / bin / kafka-server-start.sh / opt / kafka / config / serveur.Propriétés execstop = / opt / kafka / bin / kafka-server-stop.sh [installer] recherché = multi-utilisateurs.cible - Nous devons recharger
systemdPour le faire lire les nouveaux fichiers unitaires:
# SystemCTL Daemon-Reload
- Nous pouvons maintenant démarrer nos nouveaux services (dans cet ordre):
# systemctl start zookeeper # systemctl start kafka
Si tout va bien,
systemdDoit signaler l'état d'exécution sur l'état des deux services, similaire aux sorties ci-dessous:# SystemCTl Status Zookeeper.Service Zookeeper.Service - Zookeeper chargé: chargé (/ etc / systemd / système / zookeeper.service; désactivé; Vendor Preset: Disabled) Active: Active (Running) Depuis le jeu 2019-01-10 20:44:37 CET; Il y a 6S PID principal: 11628 (Java) Tâches: 23 (Limite: 12544) Mémoire: 57.0m cgroup: / système.Slice / Zookeeper.Service 11628 Java -XMX512M -XMS512M -SERVER […] # Systemctl Status Kafka.service kafka.Service - Apache Kafka chargé: chargé (/ etc / systemd / système / kafka.service; désactivé; Vendor Preset: Disabled) Active: Active (Running) Depuis le jeu 2019-01-10 20:45:11 CET; Il y a 11S, PID principal: 11949 (Java) Tâches: 64 (Limite: 12544) Mémoire: 322.2m cgroup: / système.tranche / kafka.Service 11949 Java -xmx1g -xms1g -server […]
- Éventuellement, nous pouvons activer le démarrage automatique sur le démarrage pour les deux services:
# SystemCTL Activer Zookeeper.Service # SystemCTL Activer Kafka.service
- Pour tester les fonctionnalités, nous nous connecterons à Kafka avec un producteur et un client grand public. Les messages fournis par le producteur doivent apparaître sur la console du consommateur. Mais avant cela, nous avons besoin d'un médium, ces deux messages échangent sur. Nous créons un nouveau canal de données appelé
sujeten termes de Kafka, où le fournisseur publiera et où le consommateur s'abonnera à. Nous appellerons le sujetFirstkafkatopic. Nous utiliserons lekafkaUtilisateur pour créer le sujet:$ / opt / kafka / bin / kafka-topics.sh --create --zookeeper localhost: 2181 --réplication-factor 1 - partitions 1 - Topic Firstkafkatopic
- Nous commençons un client grand public à partir de la ligne de commande qui souscrire au sujet (à ce stade vide) créé à l'étape précédente:
$ / opt / kafka / bin / kafka-console-consommateur.sh --bootstrap-server localhost: 9092 --Sujet Firstkafkatopic --Depuis le début
Nous quittons la console et le client qui s'y entraînait ouvert. Cette console est l'endroit où nous recevrons le message que nous publions avec le client producteur.
- Sur un autre terminal, nous commençons un client producteur et publions quelques messages sur le sujet que nous avons créé. Nous pouvons interroger Kafka pour les sujets disponibles:
$ / opt / kafka / bin / kafka-topics.sh - list --zookeeper localhost: 2181 firstkafkatopic
Et connectez-vous à celui que le consommateur est abonné, puis envoyez un message:
$ / opt / kafka / bin / kafka-console producteur.SH - Broker-list localhost: 9092 - Topic Firstkafkatopic> nouveau message publié par le producteur de la console # 2
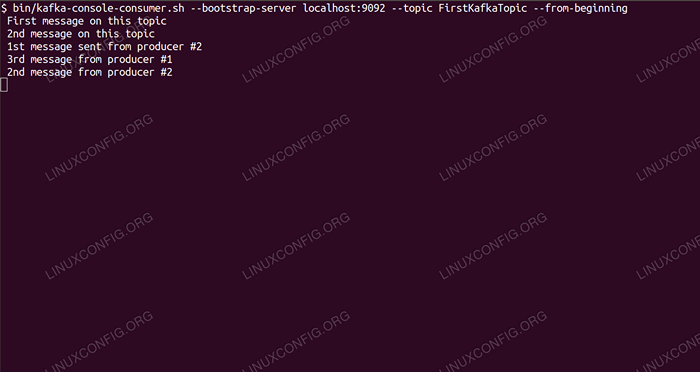
Au terminal des consommateurs, le message doit apparaître sous peu:
$ / opt / kafka / bin / kafka-console-consommateur.SH --bootstrap-server localhost: 9092 - Topic Firstkafkatopic --in-beginning nouveau message publié par le producteur de la console n ° 2
Si le message apparaît, notre test est réussi et notre installation de Kafka fonctionne comme prévu. De nombreux clients pourraient fournir et consommer un ou plusieurs enregistrements de sujet de la même manière, même avec une configuration de nœud unique que nous avons créée dans ce tutoriel.
Tutoriels Linux connexes:
- Comment utiliser le réseautage ponté avec Libvirt et KVM
- Choses à installer sur Ubuntu 20.04
- Comment empêcher la vérification de la connectivité NetworkManager
- Comment installer Steam sur Ubuntu 22.04 Jammy Jellyfish Linux
- Une introduction à l'automatisation Linux, des outils et des techniques
- Comment utiliser ADB Android Debug Bridge pour gérer votre Android…
- Masterring Bash Script Loops
- Boucles imbriquées dans les scripts bash
- Ubuntu 20.04 WordPress avec installation Apache
- Comment travailler avec l'API WooCommerce REST avec Python