

Comment surveiller l'utilisation du système, les pannes et le dépannage des serveurs Linux - Partie 9

- 2578
- 276
- Maxence Arnaud
Bien que Linux soit très fiable, les administrateurs système sages devraient trouver un moyen de garder un œil sur le comportement et l'utilisation du système à tout moment. Assurer une disponibilité aussi proche de 100% que possible et la disponibilité des ressources sont des besoins critiques dans de nombreux environnements. L'examen de l'état passé et actuel du système nous permettra de prévoir et évitera très probablement les problèmes possibles.
 Ingénieur certifié de la Fondation Linux - Partie 9
Ingénieur certifié de la Fondation Linux - Partie 9 Présentation du programme de certification de la Fondation Linux
Dans cet article, nous présenterons une liste de quelques outils disponibles dans la plupart des distributions en amont pour vérifier l'état du système, analyser les pannes et résoudre les problèmes en cours. Plus précisément, de la myriade de données disponibles, nous nous concentrerons sur le processeur, l'espace de stockage et l'utilisation de la mémoire, la gestion des processus de base et l'analyse des journaux.
Utilisation de l'espace de stockage
Il existe 2 commandes bien connues dans Linux qui sont utilisées pour inspecter l'utilisation de l'espace de stockage: df et du.
Le premier, df (qui signifie Disk sans disque), est généralement utilisé pour signaler l'utilisation globale de l'espace du disque par système de fichiers.
Exemple 1: Reportation d'utilisation de l'espace disque dans les octets et format lisible par l'homme
Sans options, df rapporte l'utilisation de l'espace disque dans les octets. Avec le -H Indicateur Il affichera les mêmes informations à l'aide de MB ou GB à la place. Notez que ce rapport comprend également la taille totale de chaque système de fichiers (en blocs de 1 k), les espaces gratuits et disponibles et le point de montage de chaque périphérique de stockage.
# df # df -h
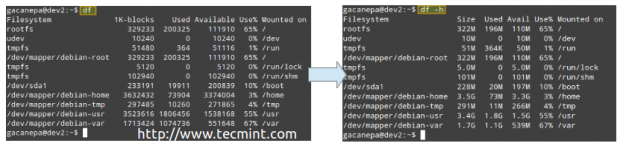 Utilisation de l'espace disque
Utilisation de l'espace disque C'est certainement bien - mais il y a une autre limitation qui peut rendre un système de fichiers inutilisable, et qui manque d'Inodes. Tous les fichiers d'un système de fichiers sont mappés sur un inode qui contient ses métadonnées.
Exemple 2: inspecter l'utilisation de l'inode par système de fichiers au format lisible par l'homme avec
# df -hti
Vous pouvez voir la quantité d'inodes d'occasion et disponibles:
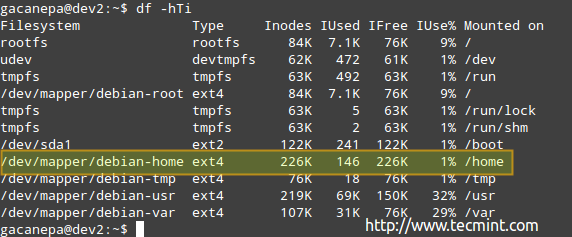 Utilisation du disque inode
Utilisation du disque inode Selon l'image ci-dessus, il y a 146 Inodes utilisé (1%) in / home, ce qui signifie que vous pouvez toujours créer des fichiers 226k dans ce système de fichiers.
Exemple 3: trouver et / ou supprimer des fichiers et répertoires vides
Notez que vous pouvez manquer d'espace de stockage bien avant de manquer d'Inodes, et vice-versa. Pour cette raison, vous devez surveiller non seulement l'utilisation de l'espace de stockage, mais aussi le nombre d'Inodes utilisés par le système de fichiers.
Utilisez les commandes suivantes pour trouver des fichiers ou des répertoires vides (qui occupent 0b) qui utilisent des inodes sans raison:
# Find / Home -Type F -Empty # Find / Home -Type D -Empty
De plus, vous pouvez ajouter le -supprimer Indicateur à la fin de chaque commande si vous souhaitez également supprimer ces fichiers et répertoires vides:
# Find / Home -Type F -Empty - Delete # Find / Home -Type F -Empty
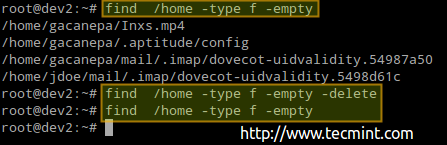 Trouver et supprimer des fichiers vides dans Linux
Trouver et supprimer des fichiers vides dans Linux La procédure précédente a supprimé 4 fichiers. Vérifions à nouveau le nombre de nœuds utilisés / disponibles dans / à domicile:
# df -hti | maison grep
 Vérifiez l'utilisation de Linux Inode
Vérifiez l'utilisation de Linux Inode Comme vous pouvez le voir, il y a 142 utilisé des inodes maintenant (4 de moins qu'avant).
Exemple 4: Examiner l'utilisation du disque par répertoire
Si l'utilisation d'un certain système de fichiers est supérieure à un pourcentage prédéfini, vous pouvez utiliser du (abréviation pour l'utilisation du disque) pour savoir quels sont les fichiers qui occupent le plus d'espace.
L'exemple est donné pour / var, qui, comme vous pouvez le voir, dans la première image ci-dessus, est utilisé à ses 67%.
# du -sch / var / *
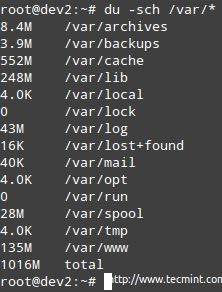 Vérifiez l'utilisation de l'espace disque par répertoire
Vérifiez l'utilisation de l'espace disque par répertoire Note: Que vous pouvez passer à l'une des sous-répertoires ci-dessus pour savoir exactement ce qu'il y a et combien chaque article occupe. Vous pouvez ensuite utiliser ces informations pour supprimer certains fichiers s'il n'y a pas besoin ou étendre la taille du volume logique si nécessaire.
Lire aussi
- 12 Commandes «DF» utiles pour vérifier l'espace disque
- 10 Commandes «DU» utiles pour trouver l'utilisation du disque des fichiers et répertoires
Mémoire et utilisation du processeur
L'outil classique de Linux qui est utilisé pour effectuer une vérification globale de l'utilisation du processeur / mémoire et de la gestion des processus est la commande supérieure. De plus, le haut affiche une vue en temps réel d'un système en cours d'exécution. Il y a d'autres outils qui pourraient être utilisés dans le même but, comme HTOP, mais je me suis installé pour le top car il est installé prêt à l'emploi dans n'importe quelle distribution Linux.
Exemple 5: Affichage d'un état en direct de votre système avec le haut
Pour démarrer en haut, tapez simplement la commande suivante dans votre ligne de commande et appuyez sur Entrée.
# haut
Examinons une sortie supérieure typique:
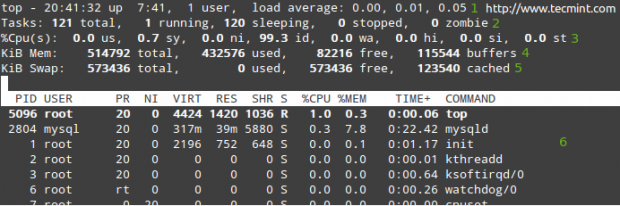 Liste tous les processus en cours d'exécution dans Linux
Liste tous les processus en cours d'exécution dans Linux Dans les lignes 1 à 5, les informations suivantes s'affichent:
1. L'heure actuelle (8:41:32) et la disponibilité (7 heures et 41 minutes). Un seul utilisateur est connecté au système et à la moyenne de charge au cours des 1, 5 et 15 dernières minutes, respectivement. 0.00, 0.01, et 0.05 Indiquez que sur ces intervalles de temps, le système était inactif pour 0% du temps (0.00: Aucun processus n'attendait le CPU), il a ensuite été surchargé de 1% (0.01: une moyenne de 0.01 Les processus attendaient le CPU) et 5% (0.05). Si moins de 0 et plus le nombre est petit (0.65, par exemple), le système était inactif de 35% au cours des 1, 5 ou 15 dernières minutes, selon l'endroit où 0.65 apparaît.
2. Actuellement, il y a 121 processus en cours d'exécution (vous pouvez voir la liste complète en 6). Un seul d'entre eux est en cours d'exécution (en haut dans ce cas, comme vous pouvez le voir dans la colonne% CPU) et les 120 restants attendent en arrière-plan mais «dorment» et resteront dans cet état jusqu'à ce que nous les appelons. Comment? Vous pouvez le vérifier en ouvrant une invite MySQL et en exécuter quelques requêtes. Vous remarquerez comment le nombre de processus en cours augmente.
Alternativement, vous pouvez ouvrir un navigateur Web et accéder à une page donnée qui est servie par Apache et vous obtiendrez le même résultat. Bien sûr, ces exemples supposent que les deux services sont installés dans votre serveur.
3. US (processus utilisateur en cours d'exécution avec une priorité non modifiée), SY (Processus de noyau d'exécution de temps), NI (processus utilisateur de temps avec une priorité modifiée), WA (temps en attente d'achèvement d'E / S), HI (temps passé à entretenir les interruptions matérielles), SI (temps passé à entretenir les interruptions logicielles), ST (temps volé à la machine virtuelle actuelle par l'hyperviseur - uniquement dans des environnements virtualisés).
4. Utilisation de la mémoire physique.
5. Échanger l'utilisation de l'espace.
Exemple 6: inspecter l'utilisation de la mémoire physique
Pour inspecter la mémoire RAM et l'échange d'utilisation, vous pouvez également utiliser gratuit commande.
# gratuit
 Vérifiez l'utilisation de la mémoire Linux
Vérifiez l'utilisation de la mémoire Linux Bien sûr, vous pouvez également utiliser le -m (MB) ou -g (GB) passe pour afficher les mêmes informations sous forme lisible par l'homme:
# gratuit -m
 Afficher l'utilisation de la mémoire Linux
Afficher l'utilisation de la mémoire Linux Quoi qu'il en soit, vous devez être conscient du fait que le noyau se réserve autant de mémoire que possible et le rend disponible pour les processus lorsqu'ils le demandent. En particulier, le «-/ + tampons / cache»Ligne montre les valeurs réelles après ce cache d'E / S.
En d'autres termes, la quantité de mémoire utilisée par les processus et le montant disponible pour d'autres processus (dans ce cas, 232 MB utilisé et 270 Mb Disponible, respectivement). Lorsque les processus ont besoin de cette mémoire, le noyau diminuera automatiquement la taille du cache d'E / S.
Lire aussi: 10 Commande «gratuite» utile pour vérifier l'utilisation de la mémoire Linux
En examinant de plus près les processus
À tout moment, il y a de nombreux processus fonctionnant sur notre système Linux. Il existe deux outils que nous utiliserons pour surveiller de près les processus: ps et ptree.
Exemple 7: Affichage de l'ensemble de la liste de processus dans votre système avec PS (format standard complet)
En utilisant le -e et -F Options combinées en une (-ef) Vous pouvez répertorier tous les processus qui s'exécutent actuellement sur votre système. Vous pouvez tuer cette sortie vers d'autres outils, tels que grep (comme expliqué dans la partie 1 de la série LFCS) pour affiner la sortie à votre (ES) de processus souhaité:
# ps -ef | grep -i Squid | grep -v grep
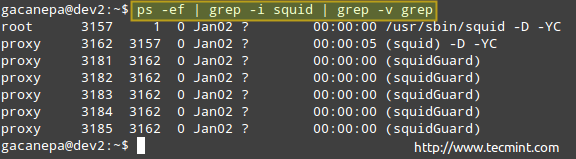 Processus de surveillance de Linux
Processus de surveillance de Linux La liste des processus ci-dessus montre les informations suivantes:
Propriétaire du processus, PID, Parent PID (le processus parent), utilisation du processeur, temps où le commandement a démarré, tty (le ? indique que c'est un démon), le temps de processeur cumulé et la commande associée au processus.
Exemple 8: Personnalisation et tri de la sortie de PS
Cependant, vous n'avez peut-être pas besoin de toutes ces informations et que vous souhaitez afficher le propriétaire du processus, la commande qui l'a commencé, son PID et PPID, et le pourcentage de mémoire qu'il utilise actuellement - dans cet ordre, et trier par Utilisation de la mémoire dans l'ordre descendant (notez que PS par défaut est trié par PID).
# ps -eo utilisateur, comm, pid, ppid,% mem --sort -% mem
Où le signe moins devant% MEM indique le tri par ordre décroissant.
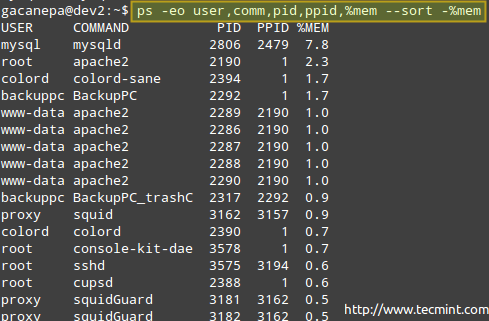 Surveiller l'utilisation de la mémoire du processus Linux
Surveiller l'utilisation de la mémoire du processus Linux Si pour une raison quelconque, un processus commence à prendre trop de ressources système et qu'il est probable que. D'autres raisons pour lesquelles vous envisageriez de le faire, c'est quand vous avez commencé un processus au premier plan, mais que vous voulez le faire en pause et reprendre en arrière-plan.
| Nom du signal | Numéro de signal | Description |
| Sigterm | 15 | Tuez le processus gracieusement. |
| Sigint | 2 | Ceci est le signal qui est envoyé lorsque nous appuyons sur Ctrl + C. Il vise à interrompre le processus, mais le processus peut l'ignorer. |
| Sigkill | 9 | Ce signal interrompt également le processus, mais il le fait inconditionnellement (utilisez avec soin!) Puisqu'un processus ne peut pas l'ignorer. |
| Faire un coup de pouce | 1 | Abréviation de «raccrocher», ce signaux demande aux démons de relire son fichier de configuration sans arrêter le processus. |
| Sigtstp | 20 | Pause l'exécution et attendez prêt à continuer. Ceci est le signal qui est envoyé lorsque nous tapons la combinaison de clé Ctrl + Z. |
| Sigstop | 19 | Le processus est interrompu et n'obtient plus d'attention des cycles du processeur jusqu'à ce qu'il soit redémarré. |
| Sigcontte | 18 | Ce signal indique au processus de reprendre l'exécution après avoir reçu SIGTSTP ou SIGSTOP. Ceci est le signal qui est envoyé par le shell lorsque nous utilisons les commandes FG ou BG. |
Exemple 9: pause de l'exécution d'un processus en cours et reprendre en arrière-plan
Lorsque l'exécution normale d'un certain processus implique qu'aucune sortie ne sera envoyée à l'écran pendant qu'il s'exécute, vous voudrez peut-être le démarrer en arrière-plan (ajoutant un ampère et à la fin de la commande).
nom du processus &
ou,
Une fois qu'il a commencé à fonctionner au premier plan, faites-le une pause et envoyez-le à l'arrière-plan avec
Ctrl + z
# Kill -18 pid
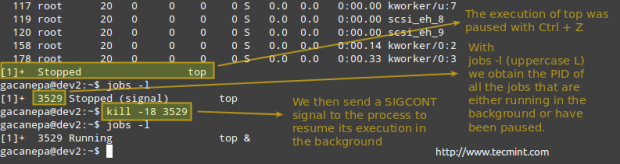 Tuer le processus à Linux
Tuer le processus à Linux Exemple 10: Killing by Force a procédé «Gone Wild»
Veuillez noter que chaque distribution fournit des outils pour arrêter / démarrer / redémarrer / recharger / recharger les services communs, tels que service dans les systèmes basés sur SYSV ou systemctl Dans les systèmes basés sur Systemd.
Si un processus ne répond pas à ces services publics, vous pouvez le tuer par force en lui envoyant le signal Sigkill.
# ps -ef | grep apache # kill -9 3821
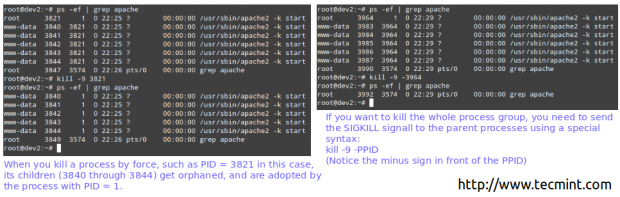 Tuez avec force le processus Linux
Tuez avec force le processus Linux Alors… ce qui s'est passé / se passe?
Lorsqu'il y a eu une sorte de panne dans le système (que ce soit une panne de courant, une défaillance matérielle, une interruption planifiée ou imprévue d'un processus ou toute anomalie), le se connectait en / var / log sont vos meilleurs amis pour déterminer ce qui s'est passé ou ce qui pourrait causer les problèmes auxquels vous êtes confronté.
# cd / var / log
 Afficher les journaux Linux
Afficher les journaux Linux Certains des articles dans / var / log sont des fichiers texte réguliers, d'autres sont des répertoires et d'autres sont des fichiers compressés des journaux tournés (historiques). Vous voudrez vérifier ceux qui ont le mot erre dans leur nom, mais inspecter le reste peut également être utile.
Exemple 11: Examiner les journaux pour les erreurs dans les processus
Imaginez ce scénario. Vos clients LAN ne sont pas en mesure d'imprimer pour les imprimantes en réseau. La première étape pour dépanner cette situation va / var / log / tasses répertoire et voir ce qu'il y a là-dedans.
Vous pouvez utiliser le queue commande pour afficher les 10 dernières lignes du fichier error_log, ou tail -f error_log Pour une vue en temps réel du journal.
# CD / var / log / tasses # ls # tail error_log
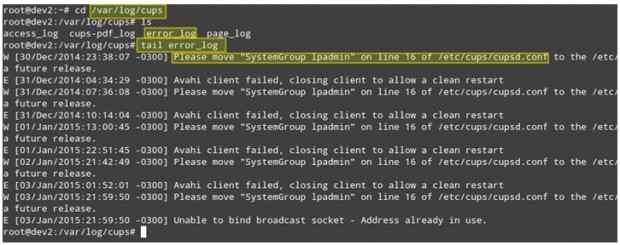 Surveiller les fichiers journaux en temps réel
Surveiller les fichiers journaux en temps réel La capture d'écran ci-dessus fournit des informations utiles pour comprendre ce qui pourrait causer votre problème. Notez que suivre les étapes ou corriger le désactivation du processus peut toujours ne pas résoudre le problème global, mais si vous êtes utilisé dès le début pour vérifier les journaux à chaque problème (que ce soit un réseau local ou un réseau) vous 'sera définitivement sur la bonne voie.
Exemple 12: Examiner les journaux pour les échecs matériels
Bien que les défaillances matérielles puissent être difficiles à dépanner, vous devez vérifier le dmesg et les journaux de messages et le grep pour les mots connexes à une partie matérielle présumée défectueuse.
L'image ci-dessous est tirée de / var / log / messages Après avoir cherché la parole du mot en utilisant la commande suivante:
# moins / var / log / messages | Erreur grep -i
Nous pouvons voir que nous avons un problème avec deux dispositifs de stockage: / dev / sdb et / dev / sdc, ce qui à son tour provoque un problème avec le tableau des raids.
 Dépannage des problèmes linux
Dépannage des problèmes linux Conclusion
Dans cet article, nous avons exploré certains des outils qui peuvent vous aider à être toujours conscients de l'état global de votre système. De plus, vous devez vous assurer que votre système d'exploitation et vos packages installés sont mis à jour vers leurs dernières versions stables. Et jamais, jamais, oubliez de vérifier les journaux! Ensuite, vous vous dirigerez dans la bonne direction pour trouver la solution définitive à tous les problèmes.
N'hésitez pas à laisser vos commentaires, suggestions ou questions - si vous avez quelque chose qui utilise le formulaire ci-dessous.
Devenir ingénieur certifié Linux- « Comment configurer un référentiel réseau pour installer ou mettre à jour les packages - partie 11
- Comment configurer un pare-feu iptables pour permettre l'accès à distance aux services dans Linux - partie 8 »