

Comment configurer Hadoop 2.6.5 (cluster de nœuds unique) sur Ubuntu, Centos et Fedora

- 2893
- 828
- Anaïs Charles
Apache Hadoop 2.6.5 Améliorations notables par rapport à l'écurie précédente 2.X.Sormes Y. Cette version a de nombreuses améliorations de HDFS et MapReduce. Ce guide pratique vous aidera à installer Hadoop 2.6 sur Centos / Rhel 7/6/5, Ubuntu et autre système d'exploitation basé à Debian. Cet article n'inclut pas la configuration globale pour configurer Hadoop, nous n'avons que la configuration de base requise pour commencer à travailler avec Hadoop.
Étape 1: Installation de Java
Java est la principale exigence pour configurer Hadoop sur n'importe quel système, alors assurez-vous que Java soit installé sur votre système en utilisant la commande suivante.
# Java -Version Java Version "1.8.0_101 "Java (TM) SE Runtime Environment (Build 1.8.0_131-b11) Java Hotspot (TM) VM du serveur 64 bits (build 25.131-b11, mode mixte)
Si vous n'avez pas installé Java sur votre système, utilisez l'un des liens suivants pour l'installer d'abord.
Installer Java 8 sur Centos / Rhel 7/6/5
Installez Java 8 sur Ubuntu
Étape 2: Création d'un utilisateur Hadoop
Nous vous recommandons de créer un compte normal (ni de racine) pour le travail Hadoop. Créez donc un compte système en utilisant la commande suivante.
# AddUser Hadoop # Passwd Hadoop
Après avoir créé un compte, il devait également configurer SSH basé sur des clés sur son propre compte. Pour ce faire, utilisez des commandes suivantes.
# su - hadoop $ ssh-keygen -t rsa $ cat ~ /.ssh / id_rsa.pub >> ~ /.ssh / autorisé_keys $ chmod 0600 ~ /.SSH / AUTORISED_KEYS
Vérinons la connexion basée sur la clé. La commande ci-dessous ne doit pas demander le mot de passe, mais la première fois, il incitera à ajouter RSA à la liste des hôtes connus.
$ ssh localhost $ exit
Étape 3. Télécharger Hadoop 2.6.5
Maintenant télécharger hadoop 2.6.0 Fichier d'archive source à l'aide de la commande ci-dessous. Vous pouvez également sélectionner un autre miroir de téléchargement pour l'augmentation de la vitesse de téléchargement.
$ cd ~ $ wget http: // www-eu.apache.org / dist / hadoop / commun / hadoop-2.6.5 / Hadoop-2.6.5.le goudron.gz $ tar xzf hadoop-2.6.5.le goudron.gz $ mv hadoop-2.6.5 Hadoop
Étape 4. Configurer le mode hadoop pseudo-distribué
4.1. Configuration des variables d'environnement Hadoop
Tout d'abord, nous devons définir des utilisations variables de l'environnement par Hadoop. Modifier ~ /.bashrc fichier et ajouter les valeurs suivantes à la fin du fichier.
export hadoop_home = / home / hadoop / hadoop export hadoop_install = $ hadoop_home export hadoop_mapred_home = $ hadoop_home export hadoop_common_home = $ hadoop_home export_hoop_hdfs_home = $ hadoop_common " Hadoop_home / sbin: $ hadoop_home / bin
Appliquez maintenant les modifications de l'environnement en cours actuel
$ source ~ /.bashrc
Modifiez maintenant $ Hadoop_home / etc / hadoop / hadoop-env.shot fichier et régler Java_home variable d'environnement. Modifiez le chemin Java selon l'installation de votre système.
exporter java_home = / opt / jdk1.8.0_131 /
4.2. Modifier les fichiers de configuration
Hadoop a de nombreux fichiers de configuration, qui doivent configurer selon les exigences pour configurer l'infrastructure Hadoop. Commençons par la configuration avec la configuration de Basic Hadoop Node Cluster. Tout d'abord, accédez à l'emplacement ci-dessous
$ cd $ hadoop_home / etc / hadoop
Modifier le site core.xml
FS.défaut.nom hdfs: // localhost: 9000
Modifier le site HDFS.xml
DFS.réplication 1 DFS.nom.DIR FILE: /// home / hadoop / hadoopdata / hdfs / namenode dfs.données.DIR FILE: /// home / hadoop / hadoopdata / hdfs / datanode
Modifier le site Mapred.xml
mapreduce.cadre.Nommez le fil
Modifier le site du fil.xml
fil.nodemanager.Aux-Services MapReduce_Shuffle
4.3. Format namenode
Maintenant, formatez le namenode à l'aide de la commande suivante, assurez-vous que le répertoire de stockage est
$ hdfs namenode -format
Exemple de sortie:
15/02/04 09:58:43 Info namenode.Namenode: startup_msg: / ********************************************* *************** startup_msg: Démarrage de NameNode startup_msg: host = svr1.técadmin.net / 192.168.1.133 startup_msg: args = [-format] startup_msg: version = 2.6.5… 15/02/04 09:58:57 Info Commun.Stockage: Directoire de stockage / Home / Hadoop / HadoopData / HDFS / NameNode a été formaté avec succès. 15/02/04 09:58:57 Info namenode.NnstorageRetentionManager: va conserver 1 images avec txid> = 0 15/02/04 09:58:57 info util.EXITUTIL: Sortie avec statut 0 15/02/04 09:58:57 Info namenode.Namenode: shutdown_msg: / ********************************************* *************** shutdown_msg: arrêt namenode à SVR1.técadmin.net / 192.168.1.133 ************************************************* *********** /
Étape 5. Démarrer le cluster Hadoop
Maintenant, démarrez votre cluster Hadoop en utilisant les scripts fourni par Hadoop. Accédez simplement à votre répertoire Hadoop Sbin et exécutez des scripts un par un.
$ cd $ hadoop_home / sbin /
MAINTENANT start-dfs.shot scénario.
$ start-dfs.shot
Exemple de sortie:
15/02/04 10:00:34 Warn Util.NativeCodeLoader: Impossible de charger la bibliothèque native-Hadoop pour votre plate-forme… en utilisant des classes intégrées-java le cas échéant le cas échéant NameNodes sur [LocalHost] LocalHost: Démarrage de NameNode, Loggation à / Home / Hadoop / Hadoop / Logs / Hadoop-Hadoop-NameNode-Svr1.técadmin.filet.Out localhost: Démarrage de Datanode, connexion vers / home / hadoop / hadoop / logs / hadoop-hadoop-datanode-svr1.técadmin.filet.OUT DÉMARRAGE Namenodes secondaires [0.0.0.0] L'authenticité de l'hôte '0.0.0.0 (0.0.0.0) «Je ne peux pas être établi. L'empreinte digitale de la clé RSA est 3C: C4: F6: F1: 72: D9: 84: F9: 71: 73: 4A: 0D: 55: 2C: F9: 43. Êtes-vous sûr de vouloir continuer à vous connecter (oui / non)? Oui 0.0.0.0: AVERTISSEMENT: Ajouté en permanence '0.0.0.0 '(RSA) à la liste des hôtes connus. 0.0.0.0: Démarrage du secondarynamenode, journalisation vers / home / hadoop / hadoop / journaux / Hadoop-Hadoop-Secondarynamenode-Svr1.técadmin.filet.Out 15/02/04 10:01:15 Warn Util.NativeCodeLoader: Impossible de charger la bibliothèque native-hadoop pour votre plate-forme… en utilisant des classes intégrées-java, le cas échéant, le cas échéant
MAINTENANT démarrage.shot scénario.
$ start-yarn.shot
Exemple de sortie:
Démarrer les démons du fil Démarrage de ResourceManager, enregistrez-vous / Home / Hadoop / Hadoop / Logs / Yarn-Hadoop-ResourceManager-Svr1.técadmin.filet.Out localhost: Démarrage de nodemanager, se connectant à / home / hadoop / hadoop / journaux / yarn-hadoop-nodemanager-svr1.técadmin.filet.dehors
Étape 6. Accès aux services Hadoop dans le navigateur
Hadoop NameNode a commencé sur le port 50070 par défaut. Accédez à votre serveur sur le port 50070 dans votre navigateur Web préféré.
http: // svr1.técadmin.net: 50070 /
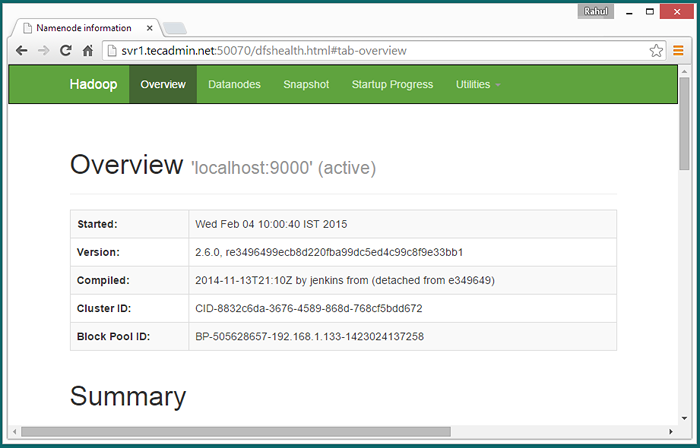
Maintenant, accédez au port 8088 pour obtenir les informations sur le cluster et toutes les applications
http: // svr1.técadmin.net: 8088 /
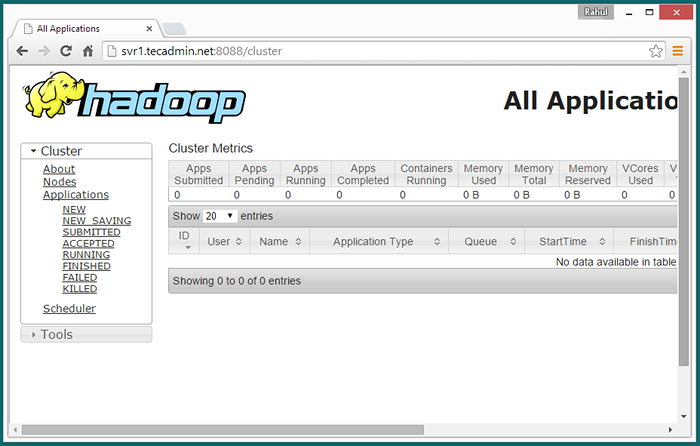
Accès au port 50090 pour obtenir des détails sur le namenode secondaire.
http: // svr1.técadmin.net: 50090 /
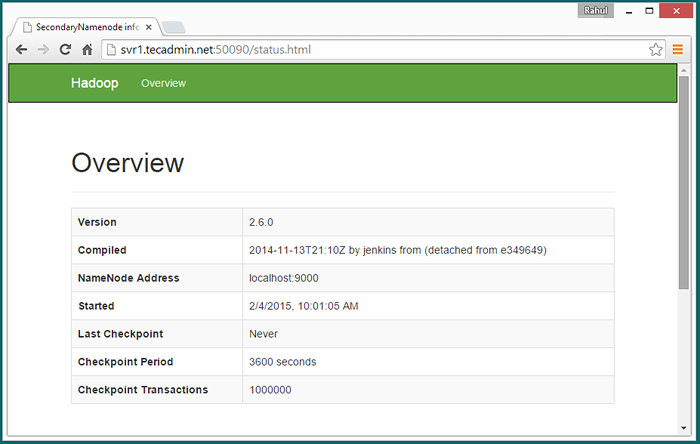
Accès au port 50075 pour obtenir des détails sur Datanode
http: // svr1.técadmin.net: 50075 /
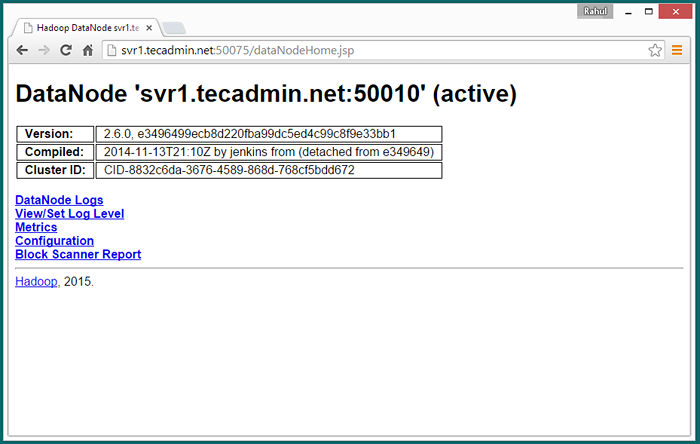
Étape 7. Tester la configuration du nœud unique Hadoop
7.1 - Faire les répertoires HDFS requis en utilisant les commandes suivantes.
$ bin / hdfs dfs -mkdir / user $ bin / hdfs dfs -mkdir / user / hadoop
7.2 - Copiez maintenant tous les fichiers du système de fichiers local / var / log / httpd au système de fichiers distribué hadoop à l'aide de la commande ci-dessous
$ bin / hdfs dfs -put / var / log / httpd journaux
7.3 - Découvrez maintenant le système de fichiers distribué Hadoop en ouvrant sous URL dans le navigateur.
http: // svr1.técadmin.Net: 50070 / Explorer.html # / utilisateur / hadoop / journaux
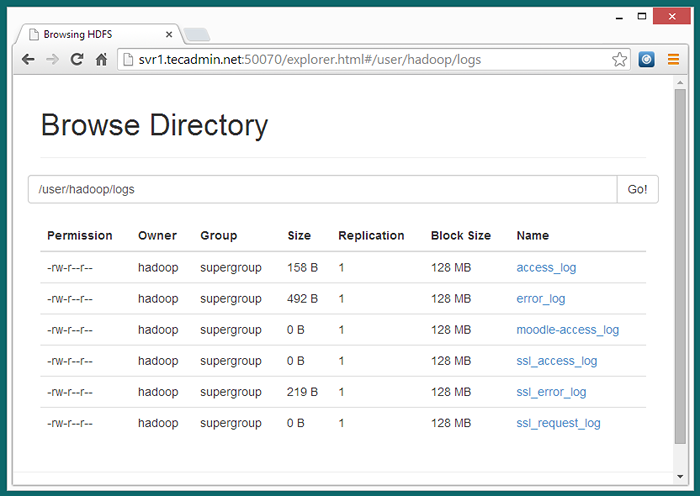
7.4 - Copiez maintenant le répertoire des journaux pour le système de fichiers distribué Hadoop au système de fichiers local.
$ bin / hdfs dfs -get logs / tmp / logs $ ls -l / tmp / logs /
Vous pouvez également vérifier ce tutoriel pour exécuter un exemple de travail WordCount MapReduce en utilisant la ligne de commande.
- « Comment supprimer les espaces de la chaîne en javascript
- Comment créer une base de données Aspstate dans SQL Server »