

Introduction

- 2745
- 748
- Noa Faure
31 juillet 2009
Par Pierre Vignéras
Abstrait:
Comme vous le savez peut-être, Linux prend en charge divers systèmes de fichiers tels que EXT2, EXT3, EXT4, XFS, Reiserfs, JFS entre autres. Peu d'utilisateurs considèrent vraiment cette partie d'un système, en sélectionnant les options par défaut du programme d'installation de leur distribution. Dans cet article, je donnerai des raisons pour une meilleure considération du système de fichiers et de sa mise en page. Je suggérerai un processus haut de gamme pour la conception d'une disposition «intelligente» qui reste aussi stable que possible au fil du temps pour une utilisation d'ordinateur donnée.Introduction
La première question que vous pouvez vous poser est pourquoi il y a tant de systèmes de fichiers, et quelles sont leurs différences? Pour le faire court (voir Wikipedia pour plus de détails):
- EXT2: C'est le Linux FS, je veux dire, celui qui a été spécialement conçu pour Linux (influencé par EXT et BERKELEY FFS). Pro: rapide; Inconvénients: non journalisée (long FSCK).
- EXT3: L'extension EXT2 naturelle. Pro: compatible avec EXT2, journalisée; Inconvénients: plus lent qu'ext2, autant de concurrents, obsolètes aujourd'hui.
- Ext4: La dernière extension de la famille EXT. Pro: compatibilité ascendante avec ext3, grande taille; Bonne performance de lecture; Inconvénients: un peu trop récent pour savoir?
- JFS: IBM AIX FS porté sur Linux. Pro: mature, rapide, léger et fiable, grande taille; Inconvénients: toujours développé?
- XFS: SGI IRIX FS porté sur Linux. Pro: très mature et fiable, bonne performance moyenne, grande taille, de nombreux outils (comme un défragmenteur); Inconvénients: aucun pour autant que je sache.
- Reiserfs: alternative au système de fichiers ext2 / 3 sur Linux. Pro: rapide pour les petits fichiers; Inconvénients: toujours développé?
Il existe d'autres systèmes de fichiers, en particulier de nouveaux tels que BTRFS, ZFS et NILFS2 qui peuvent sembler très intéressants aussi. Nous les traiterons plus tard dans cet article.
Alors maintenant, la question est: quel système de fichiers est le plus adapté à votre situation particulière? La réponse n'est pas simple. Mais si vous ne savez pas vraiment, si vous avez un doute, je recommanderais XFS pour diverses raisons:
- Il fonctionne très bien en général et en particulier en lecture / écriture simultanée (voir Benchmark);
- Il est très mature et a donc été testé et réglé de manière approfondie;
- Surtout, il est livré avec de grandes fonctionnalités telles que XFS_FSR, un défragmenter facile à utiliser (faites simplement un ln -sf $ (qui xfs_fsr) / etc / cron.quotidien / Defrag et oubliez-le).
Le seul problème que je vois avec XFS, c'est que vous ne pouvez pas réduire un XFS FS. Vous pouvez développer une partition XFS même lorsque vous êtes monté et en usage actif (croissance à chaud), mais vous ne pouvez pas réduire sa taille. Par conséquent, si vous avez des besoins en réduction du système de fichiers, choisissez un autre système de fichiers tel que EXT2 / 3/4 ou Reiserfs (pour autant que je sache, vous ne pouvez de toute façon que vous ne réduisez ni Ext3 ni Reiserfs Systems) de toute façon). Une autre option consiste à conserver les XF et à toujours commencer par une petite taille de partition (comme vous pouvez toujours faire une croissance à chaud après).
Si vous avez un ordinateur à profil bas (ou un serveur de fichiers) et que si vous avez vraiment besoin de votre processeur pour autre chose que de gérer les opérations d'entrée / sortie, je suggère de JFS.
Si vous avez de nombreux répertoires ou / et petits fichiers, Reiserfs peut être une option.
Si vous avez besoin de performances à tout prix, je suggérerais ext2.
Honnêtement, je ne vois aucune raison de choisir EXT3 / 4 (performance? vraiment?).
C'est pour le choix du système de fichiers. Mais alors, l'autre question est de savoir quelle disposition dois-je utiliser? Deux partitions? Trois? Dédié / home /? Lecture seulement /? Séparé / TMP?
De toute évidence, il n'y a pas de réponse unique à cette question. De nombreux facteurs doivent être pris en compte pour faire un bon choix. Je vais d'abord définir ces facteurs:
- Complexité: dans quelle mesure la disposition est complexe à l'échelle mondiale;
- La flexibilité: Comme il est facile de changer la disposition;
- Performance: À quelle vitesse la mise en page permet au système d'exécuter.
Trouver la disposition parfaite est un compromis entre ces facteurs.
Disposition par défaut
Souvent, un utilisateur final de bureau avec peu de connaissances de Linux suivra les paramètres par défaut de sa distribution où (généralement) seules deux ou trois partitions sont conçues pour Linux, avec le système de fichiers racine '/', / boot et l'échange. Les avantages d'une telle configuration sont la simplicité. Le principal problème est que cette disposition n'est ni flexible ni performante.
Manque de flexibilité
Le manque de flexibilité est évident pour de nombreuses raisons. Premièrement, si l'utilisateur final veut une autre mise en page (par exemple, il souhaite redimensionner le système de fichiers racine, ou s'il veut utiliser un système de fichiers séparé / TMP), il devra redémarrer le système et utiliser un logiciel de partitionnement (à partir d'un livecd par exemple). Il devra prendre soin de ses données car la remise en parts est une opération à force brute que le système d'exploitation n'est pas au courant de.
De plus, si l'utilisateur final veut ajouter un peu de stockage (par exemple un nouveau disque dur), il finira par modifier la disposition du système (/ etc / fstab) et après un certain temps, son système dépendra simplement de la disposition de stockage sous-jacente (numéro et emplacement des disques durs, des partitions, etc.).
Soit dit en passant, avoir des partitions distinctes pour vos données (/ à domicile mais aussi tous les audio, vidéo, base de données,…) facilite le changement du système (par exemple d'une distribution Linux à une autre). Il facilite également le partage de données entre les systèmes d'exploitation (BSD, Opensolaris, Linux et même Windows). mais c'est une autre histoire.
Une bonne option consiste à utiliser la gestion du volume logique (LVM). LVM résout le problème de flexibilité d'une manière très agréable, comme nous le verrons. La bonne nouvelle est que la plupart des distributions modernes prennent en charge LVM et certains l'utilisent par défaut. LVM ajoute une couche d'abstraction au-dessus du matériel supprimant les dépendances dures entre le système d'exploitation (/ etc / fstab) et les périphériques de stockage sous-jacents (Dev / HDA, / dev / sda, et autres). Cela signifie que vous pouvez modifier la disposition du stockage - ajoutant et supprimant les disques durs - sans déranger votre système. Pour autant que je sache, le principal problème de LVM est que vous pouvez avoir du mal à lire un volume LVM à partir d'autres systèmes d'exploitation.
Manque de performance.
Quel que soit le système de fichiers utilisé (EXT2 / 3/4, XFS, Reiserfs, JFS), il n'est pas parfait pour toutes sortes de modèles de données et d'utilisation (AKA Workload). Par exemple, XFS est connu pour être bon dans la gestion de gros fichiers tels que les fichiers vidéo. De l'autre côté, Reiserfs est connu pour être efficace dans la gestion de petits fichiers (tels que les fichiers de configuration dans votre répertoire domestique ou dans / etc). Par conséquent, avoir un système de fichiers pour toutes sortes de données et d'utilisation n'est certainement pas optimal. Le seul bon point avec cette disposition est que le noyau n'a pas besoin de prendre en charge de nombreux systèmes de fichiers différents, donc il réduit la quantité de mémoire que le noyau utilise à son strict (cela est également vrai avec les modules). Mais à moins que nous ne nous concentrions sur les systèmes intégrés, je considère cet argument comme non pertinent avec les ordinateurs d'aujourd'hui.
Choisir la bonne chose: une approche du haut-fond
Souvent, lorsqu'un système est conçu, il se fait généralement dans une approche inférieure et supérieure: le matériel est acheté en fonction des critères qui ne sont pas liés à leur utilisation. Par la suite, une disposition du système de fichiers est définie selon ce matériel: «J'ai un disque, je peux le partitionner de cette façon, cette partition apparaîtra là, cet autre là-bas, et ainsi de suite».
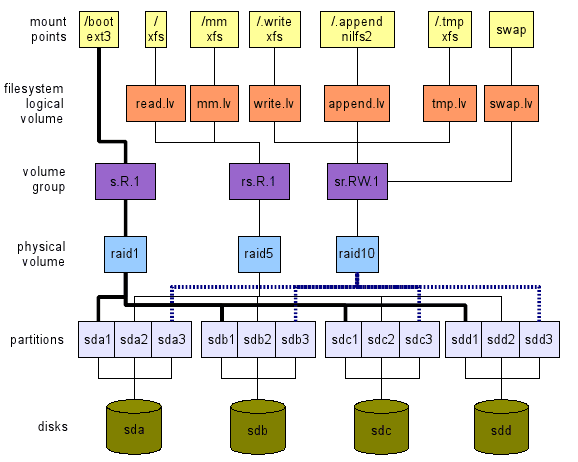
Je propose l'approche inverse. Nous définissons ce que nous voulons à un niveau élevé. Ensuite, nous parcourons les calques de haut en bas, jusqu'à réel matériel - périphériques de stockage dans notre cas - comme indiqué sur la figure 1. Cette illustration est juste un exemple de ce qui peut être fait. Il existe de nombreuses options comme nous le verrons. Les prochaines sections expliqueront comment nous pouvons arriver à une telle mise en page globale.
Figure 1: Un exemple de disposition du système de fichiers. Notez que deux partitions restent gratuites (SDB3 et SDC3). Ils peuvent être utilisés pour / démarrer, pour l'échange ou les deux. Ne pas «copier / coller» cette mise en page. Il n'est pas optimisé pour votre charge de travail. C'est juste un exemple.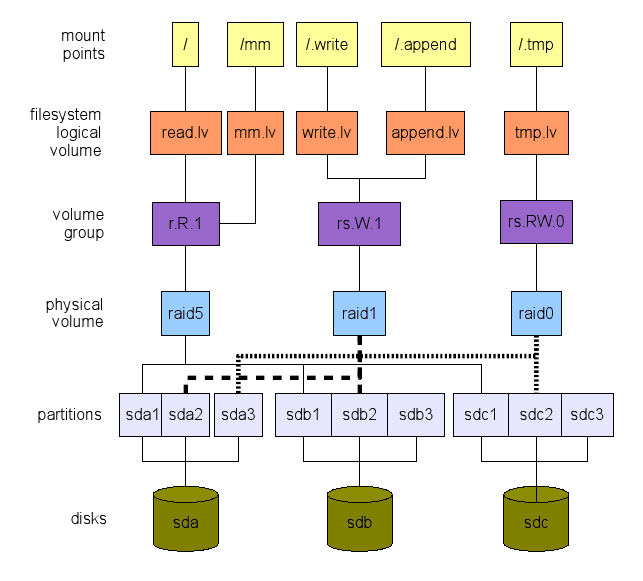
Acheter le bon matériel
Avant d'installer un nouveau système, l'utilisation cible doit être prise en compte. D'abord d'un point de vue matériel. Est-ce un système embarqué, un bureau, un serveur, un ordinateur multi-utilisateur polyvalent (avec TV / Audio / Video / OpenOffice / Web / Chat / P2P,…)?
Par exemple, je recommande toujours les utilisateurs finaux avec des besoins de bureau simples (Web, courrier, chat, peu d'observation des médias) pour acheter un processeur à faible coût (le moins cher), beaucoup de RAM (le maximum) et au moins deux disques durs.
De nos jours, même le processeur le moins cher est suffisamment loin pour la surface Web et l'observation des films. Beaucoup de RAM donne un bon cache (Linux utilise une mémoire libre pour la mise en cache - réduisant la quantité d'entrée / sortie coûteuse sur les périphériques de stockage). Soit dit en passant, l'achat de la quantité maximale de RAM que votre carte mère peut prendre en charge est un investissement pour deux raisons:
- Les applications ont tendance à nécessiter de plus en plus de mémoire; Par conséquent, avoir la quantité maximale de mémoire vous empêche déjà d'ajouter de la mémoire plus tard pendant un certain temps;
- La technologie change si rapidement que votre système peut ne pas prendre en charge la mémoire disponible en 5 ans. À ce moment-là, l'achat de la vieille mémoire sera probablement assez cher.
Avoir deux disques durs leur permet d'être utilisés dans Mirror. Par conséquent, si l'on échoue, le système continuera de fonctionner normalement et vous aurez le temps d'obtenir un nouveau disque dur. De cette façon, votre système restera disponible et vos données, assez sûres (ce n'est pas suffisant, sauvegarde vos données également).
Définition du modèle d'utilisation
Lorsque vous choisissez du matériel, et en particulier la disposition du système de fichier, vous devez considérer les applications qui l'utiliseront. Différentes applications ont une charge de travail d'entrée / sortie différente. Considérez les applications suivantes: Logueurs (Syslog), lecteurs de courrier (Thunderbird, Kmail), moteur de recherche (Beagle), base de données (MySQL, Postgresql), P2P (Emule, Gnutella, Vuze), Shels (bash)… pouvez-vous voir leur entrée / modèles de sortie et combien ils diffèrent?
Par conséquent, je définis l'emplacement de stockage abstrait suivant appelé volume logique - LV - dans la terminologie LVM:
- TMP.LV:
- Pour des données temporaires telles que celle trouvée dans / tmp, / var / tmp et également dans le répertoire domestique de chaque utilisateur $ home / tmp (notez que les répertoires de poubelle tels que $ home / trash, $ home /.Les déchets peuvent également être cartographiés ici. Veuillez consulter les spécifications de la poubelle Freedesktop pour les implications). Un autre candidat est / var / cache. L'idée de ce volume logique est que nous pouvons le terminer pour les performances et que nous pouvons accepter une perte de données quelque peu car ces données ne sont pas essentielles pour le système (voir Linux File-System Hiérarchy Standard (FHS) pour plus de détails sur ces emplacements).
- lire.LV:
- Pour les données qui sont principalement lues comme pour la plupart des fichiers binaires dans / bin, / usr / bin, / lib, / usr / lib, les fichiers de configuration dans / etc. et la plupart des fichiers de configuration dans chaque répertoire utilisateur $ home /.bashrc, et ainsi de suite. Cet emplacement de stockage peut être réglé pour la lecture-performance. Nous pouvons accepter de mauvaises performances en écriture car elles se produisent à de rares occasions (e.G: Lors de la mise à niveau du système). Perdre des données ici est clairement inacceptable.
- écrire.LV:
- Pour les données qui sont principalement écrites de manière aléatoire telles que les données écrites par des applications P2P ou les bases de données. Nous pouvons le régler pour des performances d'écriture. Notez que les performances de lecture ne peuvent pas être trop faibles: les applications P2P et la base de données sont lues au hasard et assez souvent les données qu'ils écrivent. Nous pouvons considérer cet emplacement comme l'emplacement «polyvalent»: si vous ne connaissez pas vraiment le modèle d'utilisation d'une application donnée, configurez-le pour qu'il utilise ce volume logique. Perdre des données ici est également inacceptable.
- ajouter.LV:
- pour les données qui sont principalement écrites de manière séquentielle comme pour la plupart des fichiers dans / var / log et aussi $ home /.xSession-Errors entre autres. Nous pouvons le régler pour des performances d'ajout qui peuvent être très différentes des performances d'écriture aléatoire. Là, les performances de lecture n'est généralement pas si importante (sauf si vous avez des besoins spécifiques bien sûr). La perte de données ici est inacceptable pour des utilisations normales (le journal donne des informations sur les problèmes. Si vous perdez vos journaux, comment pouvez-vous savoir quel était le problème?).
- MM.LV:
- pour les fichiers multimédias; Leur cas est un peu spécial en ce qu'ils sont généralement gros (vidéo) et lisent séquentiellement. Le réglage pour la lecture séquentielle peut être effectué ici. Les fichiers multimédias sont écrits une fois (par exemple à partir de l'écriture.LV où les applications P2P écrivent au MM.lv), et lire plusieurs fois séquentiellement.
Vous pouvez ajouter / suggérer toutes les autres catégories ici avec différents modèles tels que séquentiel.lire.LV, par exemple.
Définition des points de montage
Supposons que nous ayons déjà tous ces emplacements abstraits de stockage sous la forme de / dev / tbd / lv où:
- TBD est un groupe de volumes à définir plus tard (voir 3.5);
- LV est l'un des volumes logiques que nous venons de définir dans la section précédente (lire.LV, TMP.lv,…).
Nous supposons donc que nous avons déjà / dev / tbd / tmp.lv, / dev / tbd / read.lv, / dev / tbd / write.lv, et ainsi de suite.
Soit dit en passant, nous considérons que chaque groupe de volumes est optimisé pour son modèle d'utilisation (un compromis a été trouvé entre les performances et la flexibilité).
Données temporaires: TMP.LV
Nous aimerions avoir / tmp, / var / tmp, et tout $ home / tmp tous mappés à / dev / tbd / tmp.LV.
Ce que je suggère, c'est ce qui suit:
- mont / dev / tbd / tmp.lv à a /.TMP Hidden Directory au niveau racine; Dans / etc / fstab, vous aurez quelque chose comme ça (bien sûr, puisque le groupe de volumes est inconnu, cela ne fonctionnera pas; le fait est d'expliquer le processus ici.):
# Remplacez l'auto par le système de fichiers réel si vous souhaitez # Remplacer les défauts de défaut 0 2 par vos propres besoins (man fstab) / dev / tbd / tmp.lv /.TMP Auto par défaut 0 2
- lier les autres emplacements au répertoire dans /.TMP. Par exemple, supposons que vous ne vous souciez pas d'avoir des répertoires séparés pour / tmp et / var / tmp (voir FHS pour les implications), vous pouvez simplement créer un répertoire ALL_TMP à l'intérieur / dev / tbd / tmp.lv et liez-le à la fois / tmp et / var / tmp. Dans / etc / fstab, ajouter ces lignes:
/ /.tmp / all_tmp / tmp nul bind 0 0 /.tmp / all_tmp / var / tmp non lier 0 0
Bien sûr, si vous préférez vous conformer à FHS, aucun problème. Créez deux répertoires distincts FHS_TMP et FHS_VAR_TMP dans le TMP.Volume LV et ajouter ces lignes:
/ /.TMP / FHS_TMP / TMP Aucun Bind 0 0 /.TMP / FHS_VAR_TMP / VAR / TMP Aucun Bind 0 0
- Faire un lien symbolique pour le répertoire TMP utilisateur vers / tmp / utilisateur. Par exemple, $ home / tmp est un lien symbolique vers / tmp / $ user_name / tmp (j'utilise l'environnement KDE, par conséquent, mon $ home / tmp est un lien symbolique vers / tmp / kDE- $ l'utilisateur donc toutes les applications KDE Utilisez le même LV). Vous pouvez automatiser ce processus en utilisant certaines lignes dans votre .bash_profile (ou même dans le / etc / skel /.bash_profile pour que tout nouvel utilisateur l'ait). Par exemple:
Si tester ! -e $ home / tmp -a ! -E / TMP / KDE- $ Utilisateur; puis MKDIR / TMP / KDE- $ User; LN -S / TMP / KDE- $ USER $ HOME / TMP; Fi
(Ce script est assez simple et ne fonctionne que dans le cas où l'utilisateur $ home / tmp et / tmp / kDE- $ n'existe pas déjà. Vous pouvez l'adapter à votre propre besoin.)
Lire principalement des données: lire.LV
Puisque le système de fichiers racine contient / etc, / bin, / usr / bin et ainsi de suite, ils sont parfaits pour lire.LV. Par conséquent, dans / etc / fstab, je placerais ce qui suit:
/ dev / tbd / read.LV / AUTO par défaut 0 1
Pour les fichiers de configuration dans les répertoires domestiques des utilisateurs, les choses ne sont pas aussi simples que vous le devinez. On peut essayer d'utiliser la variable d'environnement XDG_CONFIG_HOME (voir Freedesktop)
Mais je ne recommanderais pas cette solution pour deux raisons. Premièrement, quelques applications y conforment en fait de nos jours (l'emplacement par défaut est $ home /.Config lorsqu'il n'est pas réglé explicitement). Deuxièmement, c'est que si vous définissez xdg_config_home à une lecture.sous-répertoire LV, les utilisateurs finaux auront du mal à trouver leurs fichiers de configuration. Par conséquent, dans ce cas, je n'ai pas de bonne solution et je ferai des répertoires domestiques et tous les fichiers de configuration stockés à l'écriture générale.Emplacement LV.
Données principalement écrites: écrire.LV
Pour ce cas, je reproduisrai en quelque sorte le modèle utilisé pour TMP.LV. Je lierai différents répertoires pour différentes applications. Par exemple, j'aurai dans le FSTAB quelque chose de similaire:
/ dev / tbd / write.lv /.Écrivez les paramètres automobiles 0 2 /.écriture / db / db Aucun Bind 0 0 /.écriture / p2p / p2p Aucun Bind 0 0 /.Écriture / Accueil / Accueil Aucun Bind 0 0
Bien sûr, cela supposait que les répertoires DB et P2P ont été créés en écriture.LV.
Notez que vous devrez peut-être être conscient de l'accès aux droits. Une option consiste à fournir les mêmes droits que pour / TMP où n'importe qui peut écrire / lire ses propres données. Ceci est réalisé par la commande Linux suivante par exemple: Chmod 1777 / P2P.
Principalement des données d'ajout: ajouter.LV
Ce volume a été réglé pour les applications de style Loggers telles que Syslog (et ses variantes syslog_ng par exemple), et tout autre journal (Java Loggers par exemple). Le / etc / fstab doit être similaire à ceci:
/ dev / tbd / annexe.lv /.Ajouter les défauts automatique des valeurs par défaut 0 2 /.APPEND / SYSLOG / VAR / LOG None Bind 0 0 /.APPENDE / ULOG / VAR / ULOG None Bind 0 0
Encore une fois, Syslog et Ulog sont des répertoires précédemment créés en ajout.LV.
Données multimédias: mm.LV
Pour les fichiers multimédias, j'ajoute simplement la ligne suivante:
/ dev / tbd / mm.LV / mm automatique par défaut 0 2
À l'intérieur / mm, je crée des photos, des audios et des répertoires de vidéos. En tant qu'utilisateur de bureau, je partage généralement mes fichiers multimédias avec d'autres membres de la famille. Par conséquent, les droits d'accès doivent être correctement conçus.
Vous préférez peut-être avoir des volumes distincts pour les fichiers photo, audio et vidéo. N'hésitez pas à créer des volumes logiques en conséquence: Photos.LV, audios.LV et vidéos.LV.
Autres
Vous pouvez ajouter vos propres volumes logiques en fonction de vos besoins. Les volumes logiques sont tout à fait gratuits à gérer. Ils n'ajoutent pas de grands frais généraux et ils offrent beaucoup de flexibilité pour vous aider à retirer le maximum de votre système, en particulier lorsque vous choisissez le bon système de fichiers pour votre charge de travail.
Définition des systèmes de fichiers pour les volumes logiques
Maintenant que nos points de montage et nos volumes logiques ont été définis en fonction de nos modèles d'utilisation de l'application, nous pouvons choisir le système de fichiers pour chaque volume logique. Et ici, nous avons beaucoup de choix comme nous l'avons déjà vu. Tout d'abord, vous avez le système de fichiers lui-même (e.G: ext2, ext3, ext4, reiserfs, xfs, jfs et ainsi de suite). Pour chacun d'eux, vous avez également leurs paramètres de réglage (tels que la taille du bloc de réglage, le nombre d'inodes, les options de journal (XFS), etc.). Enfin, lors du montage, vous pouvez également spécifier différentes options selon un modèle d'utilisation (noatime, data = writeback (ext3), barrière (XFS), etc.). La documentation du système de fichiers doit être lue et comprise afin que vous puissiez mapper les options au modèle d'utilisation correct. Si vous n'avez aucune idée de la FS à utiliser à quel point, voici mes suggestions:
- TMP.LV:
- Ce volume contiendra de nombreuses types de données, écrites / lues par les applications et les utilisateurs, petits et grands. Sans aucun modèle d'utilisation défini (principalement lu, principalement écrivant), j'utiliserais un système de fichiers générique tel que XFS ou EXT4.
- lire.LV:
- Ce volume contient le système de fichiers racine avec de nombreux binaires (/ bin, / usr / bin), bibliothèques (/ lib, / usr / lib), de nombreux fichiers de configurations (/ etc)… puisque la plupart de ses données sont lues, le fichier -Système peut être celui qui a la meilleure performance de lecture même si ses performances d'écriture sont médiocres. XFS ou EXT4 sont des options ici.
- écrire.LV:
- C'est assez difficile car cet emplacement est le "s'adapter à tous»Emplacement, il devrait gérer à la fois la lecture et l'écriture correctement. Encore une fois, XFS ou EXT4 sont également des options.
- ajouter.LV:
- Là, nous pouvons choisir un système de fichiers structuré de journal pur tel que le nouveau NILFS2 pris en charge par Linux depuis 2.6.30 qui devrait fournir de très bonnes performances d'écriture (mais méfiez-vous de ses limites (en particulier, pas de support pour Atime, des attributs étendus et de la LCA).
- MM.LV:
- contient des fichiers audio / vidéo qui peuvent être assez importants. C'est un choix parfait pour XFS. Notez que sur IRIX, XFS prend en charge une section en temps réel pour les applications multimédias. Ce n'est pas pris en charge (encore?) sous Linux pour autant que je sache.
- Vous pouvez jouer avec les paramètres de réglage XFS (voir Man XFS), mais cela nécessite de bonnes connaissances sur votre modèle d'utilisation et sur les internes XFS.
À ce niveau élevé, vous pouvez également décider si vous avez besoin d'un support de chiffrement ou de compression. Cela peut aider à choisir le système de fichiers. Par exemple, pour mm.LV, la compression est inutile (car les données multimédias sont déjà compressées) alors qu'elle peut sembler utile pour / à la maison. Considérez également si vous avez besoin de cryptage.
À cette étape, nous avons choisi les systèmes de fichiers pour tous nos volumes logiques. Le temps est maintenant de descendre à la couche suivante et de définir nos groupes de volumes.
Définition du groupe de volumes (VG)
La prochaine étape consiste à définir des groupes de volumes. À ce niveau, nous définirons nos besoins en termes de réglage des performances et de tolérance aux défauts. Je propose de définir les VG selon le schéma suivant: [r | s].[R | w].[n] où:
- 'R' - signifie aléatoire;
- 'S' - signifie séquentiel;
- 'R' - signifie lire;
- 'W' - signifie écrire;
- 'n' - est un entier positif, zéro inclus.
Lettres déterminez le type d'optimisation auquel le volume nommé a été réglé. Le nombre donne une représentation abstraite du niveau de tolérance aux défauts. Par exemple:
- r.R.0 signifie optimisé pour la lecture aléatoire avec un niveau de tolérance à la défaut de 0: la perte de données se produit dès qu'un dispositif de stockage échoue (a déclaré que le système est tolérant à 0 défaillance du périphérique de stockage).
- s.W.2 signifie optimisé pour une écriture séquentielle avec un niveau de tolérance à la défaut de 2: la perte de données se produit dès que trois appareils de stockage échouent (a déclaré que le système est tolérant à 2 défaillances de dispositifs de stockage).
Nous devons ensuite cartographier chaque volume logique à un groupe de volumes donné. Je suggère ce qui suit:
- TMP.LV:
- peut être mappé à un RS.Rw.0 groupe de volumes ou un RS.Rw.1 selon vos exigences concernant la tolérance aux défauts. De toute évidence, si votre désir est que votre système reste en ligne sur une base 24/24 heures, 365 jours / an, la deuxième option devrait certainement être considérée. Malheureusement, la tolérance aux pannes a un coût à la fois en termes d'espace de stockage et de performance. Par conséquent, vous ne devez pas vous attendre au même niveau de performance d'un RS.Rw.0 VG et un RS.Rw.1 VG avec le même nombre de périphériques de stockage. Mais si vous pouvez vous permettre les prix, il existe des solutions pour des RS assez performants.Rw.1 et même Rs.Rw.2, 3 et plus! Plus à ce sujet au niveau des baisses suivantes.
- lire.LV:
- peut être mappé à un r.R.1 VG (augmenter le nombre tolérant aux défauts si vous avez besoin);
- écrire.LV:
- peut être mappé à un r.W.1 VG (même chose);
- ajouter.LV:
- peut être mappé à un s.W.1 VG;
- MM.LV:
- peut être mappé à un s.R.1 VG.
Bien sûr, nous avons une déclaration «mai» et non «incontournable» car elle dépend du nombre de dispositifs de stockage que vous pouvez mettre dans l'équation. Définir VG est en fait assez difficile car vous ne pouvez pas toujours vraiment résumer complètement le matériel sous-jacent. Mais je crois que définir d'abord vos besoins peut aider à définir la disposition de votre système de stockage à l'échelle mondiale.
Nous verrons au niveau suivant, comment implémenter ces groupes de volumes.
Définition des volumes physiques (PV)
Ce niveau est l'endroit où vous implémentez réellement une exigence de groupe de volume donné (défini en utilisant la notation RS.Rw.n décrit ci-dessus). J'espère qu'il n'y a pas - pour autant que je sache - de nombreuses façons de mettre en œuvre une exigence VG. Vous pouvez utiliser certaines des fonctionnalités LVM (miroir, décapage), raid logiciel (avec Linux MD) ou raid matériel. Le choix dépend de vos besoins et de votre matériel. Cependant, je ne recommanderais pas le raid matériel (de nos jours) pour un ordinateur de bureau ou même un petit serveur de fichiers, pour deux raisons:
- Très souvent (la plupart du temps en fait), ce qu'on appelle un raid matériel, est en fait un raid logiciel: vous avez un chipset sur votre carte mère qui présente un contrôleur RAID à faible coût qui nécessite des logiciels (pilotes) pour effectuer le travail réel. Certainement, Linux Raid (MD) est bien meilleur à la fois en termes de performances (je pense) et en termes de flexibilité (c'est sûr).
- À moins que vous n'ayez un très vieux CPU (classe Pentium II), Soft Raid n'est pas si coûteux (ce n'est pas si vrai pour RAID5 en fait, mais pour RAID0, RAID1 et RAID10, c'est vrai).
Donc, si vous n'avez aucune idée de la façon de mettre en œuvre une spécification donnée en utilisant RAID, veuillez voir la documentation RAID.
Cependant, quelques indices:
- tout avec un .0 peut être mappé à Raid0 qui est la combinaison RAID la plus performante (mais si un périphérique de stockage échoue, vous perdez tout).
- s.R.1, R.R.1 et SR.R.1 peut être cartographié par ordre de préférences à RAID10 (minimum de 4 dispositifs de stockage (ET) requis), RAID5 (3 SD requis), RAID1 (2 SD).
- s.W.1, peut être cartographié par ordre de préférences à RAID10, RAID1 et RAID5.
- r.W.1, peut être cartographié par ordre de préférences à RAID10 et RAID1 (RAID5 a de très mauvaises performances en écriture aléatoire).
- SR.R.2 peut être cartographié à RAID10 (certaines façons) et à RAID6.
Lorsque vous mappez l'espace de stockage à un volume physique donné, ne fixez pas deux espaces de stockage du même périphérique de stockage (i.e. partitions). Vous perdrez les deux avantages de la performance et de la tolérance aux défauts! Par exemple, la fabrication / dev / sda1 et / dev / sda2 partie du même volume physique RAID1 est assez inutile.
Enfin, si vous ne savez pas quoi choisir entre LVM et MDADM, je suggère que MDADM ait, il est un peu plus flexible (il prend en charge RAID0, 1, 5 et 10, tandis que LVM ne prend en charge que Striping (similaire à RAID0) et en miroir (Similaire à RAID1)).
Même s'il n'est pas strictement nécessaire, si vous utilisez MDADM, vous vous retrouverez probablement avec une cartographie un à un entre VGS et PVS. Dit sinon, vous pouvez cartographier de nombreux PV à un VG. Mais c'est un peu inutile à mon humble avis. MDADM offre toute la flexibilité requise dans la cartographie des partitions / périphériques de stockage dans les implémentations VG.
Définition des partitions
Enfin, vous voudrez peut-être faire certaines partitions à partir de vos différents dispositifs de stockage afin de répondre à vos besoins en PV (par exemple, RAID5 nécessite au moins 3 espaces de stockage différents). Notez que dans la grande majorité des cas, vos partitions devront être de la même taille.
Si vous le pouvez, je vous suggère d'utiliser des périphériques de stockage directement (ou de ne faire qu'une seule partition à partir d'un disque). Mais il peut être difficile si vous êtes court dans les dispositifs de stockage. De plus, si vous avez des périphériques de stockage de différentes tailles, vous devrez en séparer l'un d'eux au moins.
Vous devrez peut-être trouver un compromis entre vos besoins en PV et vos dispositifs de stockage disponibles. Par exemple, si vous n'avez que deux disques durs, vous ne pouvez certainement pas implémenter un PV RAID5. Vous devrez vous fier à une implémentation RAID1 uniquement.
Notez que si vous suivez vraiment le processus top-fond décrit dans ce document (et si vous pouvez vous permettre le prix de vos exigences bien sûr), il n'y a pas de compromis réel à traiter avec! 😉
/botte
Nous n'avons pas mentionné dans notre étude le système de fichiers / démarrage où le chargeur de démarrage est stocké. Certains préféreraient avoir un seul seul / où / le démarrage n'est qu'un sous-répertoire. D'autres préfèrent séparer / et / démarrer. Dans notre cas, où nous utilisons LVM et MDADM, je suggère l'idée suivante:
- / boot est un système de fichiers séparé car un chargeur de démarrage peut avoir des problèmes avec les volumes LVM;
- / boot est un système de fichiers EXT2 ou EXT3 car ces formats sont bien pris en charge par n'importe quel chargeur de démarrage;
- / La taille du démarrage serait de 100 Mo de taille car les initRamfs peuvent être assez lourds et vous pouvez avoir plusieurs noyaux avec leurs propres initRamfs;
- / Le démarrage n'est pas un volume LVM;
- / boot est un volume RAID1 (créé à l'aide de mdadm). Cela garantit qu'au moins deux périphériques de stockage ont exactement le même contenu composé de noyau, initramfs, système.Carte et autres éléments requis pour le démarrage;
- Le volume / boot raid1 est composé de deux partitions principales qui sont la première partition sur leurs disques respectifs. Cela empêche certains vieux bios ne trouvent pas le chargeur de démarrage en raison des anciennes limitations de 1 Go.
- Le chargeur de démarrage a été installé sur les deux partitions (disques) afin que le système puisse démarrer à partir des deux disques.
- Le BIOS a été configuré correctement pour démarrer à partir de n'importe quel disque.
Échanger
Swap est aussi une chose dont nous n'avons pas discuté jusqu'à présent. Vous avez de nombreuses options ici:
- performance:
- Si vous avez besoin de performances à tout prix, créez certainement une partition sur chacun de votre périphérique de stockage et utilisez-le comme partition d'échange. Le noyau équilibrera les entrées / sorties à chaque partition en fonction de son propre besoin conduisant à la meilleure performance. Notez que vous pouvez jouer avec priorité afin de donner certaines préférences aux disques durs donnés (par exemple, un disque rapide peut être accordé une priorité plus élevée).
- tolérance aux pannes:
- Si vous avez besoin d'une tolérance aux défauts, considérez certainement la création d'un volume d'échange LVM d'un R.Rw.1 groupe de volumes (implémenté par un PV RAID1 ou RAID10 par exemple).
- la flexibilité:
- Si vous devez redimensionner votre échange pour certaines raisons, je suggère d'utiliser un ou plusieurs volumes de swap LVM.
Systèmes de fichiers futurs et / ou exotiques
En utilisant LVM, il est assez facile de configurer un nouveau volume logique créé à partir d'un groupe de volumes (selon ce que vous souhaitez tester et votre matériel) et de le formater sur certains systèmes de fichiers. LVM est très flexible à cet égard. N'hésitez pas à créer et à supprimer les systèmes de fichiers à volonté.
Mais à certains égards, les futurs systèmes de fichiers tels que ZFS, BTRFS et NILFS2 ne correspondront pas parfaitement à LVM. La raison en est que LVM conduit à une séparation claire entre les besoins d'application / utilisateur et les implémentations de ces besoins, comme nous l'avons vu. De l'autre côté, ZFS et BTRFS intègrent à la fois les besoins et la mise en œuvre dans une seule chose. Par exemple, ZFS et BTRFS prennent en charge le niveau RAID directement. La bonne chose est que cela facilite la création de la disposition du système de fichiers. La mauvaise chose est que cela viole certaines façons de séparer la stratégie de préoccupation.
Par conséquent, vous pouvez vous retrouver avec un XFS / LV / VG / MD1 / SD A, B 1 et Btrfs / SD A, B 2 dans le même système. Je ne recommanderais pas une telle mise en page et vous suggérerais d'utiliser ZFS ou BTRFS pour tout ou pas du tout.
Un autre système de fichiers qui peut être intéressant est Nilfs2. Ce système de fichiers structuré de journal aura de très bonnes performances d'écriture (mais peut-être les mauvaises performances de lecture). Par conséquent, un tel système de fichiers peut être un très bon candidat pour le volume logique d'ajout ou sur tout volume logique créé à partir d'un RS.W.n groupe de volume.
Drives USB
Si vous souhaitez utiliser un ou plusieurs lecteurs USB dans votre disposition, considérez ce qui suit:
- La bande passante du bus USB V2 est de 480 MBITS / s (60 mytes / s), ce qui est suffisant pour la grande majorité des applications de bureau (sauf peut-être la vidéo HD);
- Pour autant que je sache, vous ne trouverez aucun appareil USB qui peut remplir la bande passante USB V2.
Par conséquent, il peut être intéressant d'utiliser plusieurs disques USB (ou même bâton) pour les faire partie d'un système RAID, en particulier un système RAID1. Avec une telle disposition, vous pouvez retirer un lecteur USB d'un tableau RAID1 et l'utiliser (en mode lecture seule) ailleurs. Ensuite, vous le tirez à nouveau dans votre tableau RAID1 d'origine, et avec une commande MDADM magique telle que:
MDADM / DEV / MD0 -ADD / DEV / SDA1
Le tableau reconstruirea automatiquement et reviendra à son état d'origine. Je ne recommanderais pas de faire un autre tableau RAID à partir de Drive USB. Pour RAID0, il est évident: si vous supprimez un lecteur USB, vous perdez toutes vos données! Pour RAID5, avoir un lecteur USB, et donc, la capacité de bouchée à chaud n'offre aucun avantage: le lecteur USB que vous avez retiré est inutile dans un mode RAID5! (même remarque pour RAID10).
Drives à l'état solide
Enfin, de nouveaux disques SSD peuvent être pris en compte lors de la définition des volumes physiques. Leurs propriétés doivent être prises en compte:
- Ils ont une latence très faible (lire et écrire);
- Ils ont de très bonnes performances de lecture aléatoire et la fragmentation n'a aucun impact sur leurs performances (performance déterministe);
- Le nombre d'écritures est limité.
Par conséquent, les lecteurs SSD conviennent à la mise en œuvre des groupes de volumes RSR # n. Par exemple, MM.LV et lire.Les volumes LV peuvent être stockés sur SSDS car les données sont généralement écrites une fois et lues plusieurs fois. Ce modèle d'utilisation est parfait pour SSD.
Conclusion
Dans le processus de conception d'une disposition du système de fichiers, l'approche du haut-fond commence par des besoins de haut niveau. Cette méthode a l'avantage sur lequel vous pouvez compter les exigences précédemment faites pour des systèmes similaires. Seule l'implémentation changera. Par exemple, si vous concevez un système de bureau: vous pouvez vous retrouver avec une disposition donnée (comme celle de la figure 1). Si vous installez un autre système de bureau avec différents périphériques de stockage, vous pouvez compter sur vos premières exigences. Il vous suffit d'adapter les couches inférieures: PVS et partitions. Par conséquent, le grand travail, le modèle d'utilisation ou la charge de travail, l'analyse ne peut être effectuée qu'une seule fois par système, naturellement.
Dans la section suivante et dernière, je donnerai quelques exemples de mise en page, à peu près à régler pour des usages d'ordinateurs bien connus.
Exemples de disposition
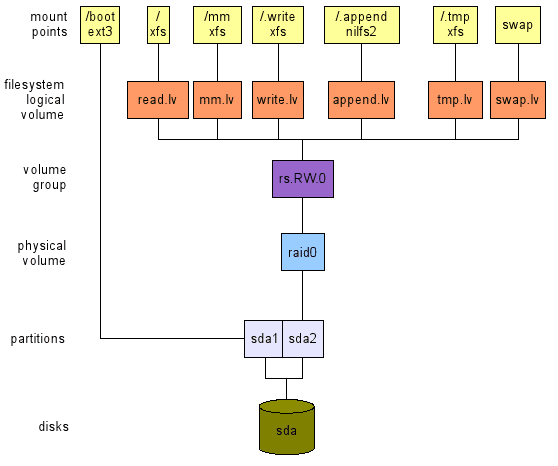
Toute utilisation, 1 disque.
Ceci (voir la disposition supérieure de Figure 2) est une situation plutôt étrange à mon avis. Comme déjà dit, je considère que tout ordinateur doit être dimensionné en fonction d'un modèle d'utilisation. Et avoir un seul disque attaché à votre système signifie que vous en acceptez une défaillance complète d'une certaine manière. Mais je sais que la grande majorité des ordinateurs aujourd'hui - en particulier les ordinateurs portables et les netbooks - sont vendus (et conçus) avec un seul disque. Par conséquent, je propose la disposition suivante qui se concentre sur la flexibilité et les performances (autant que possible):
- la flexibilité:
- Comme la disposition vous permet de redimensionner les volumes à volonté;
- performance:
- Comme vous pouvez choisir un système de fichiers (EXT2 / 3, XFS, etc.) selon les modèles d'accès aux données.
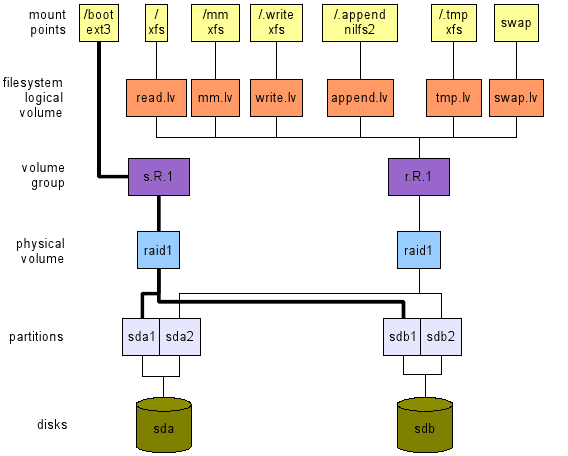
- Figure 2: Une disposition avec un disque (en haut) et une pour l'utilisation de bureau avec deux disques (en bas).
-
-
- la flexibilité:
- Comme la disposition vous permet de redimensionner les volumes à volonté;
- performance:
- Comme vous pouvez choisir un système de fichiers (EXT2 / 3, XFS, etc.) selon les modèles d'accès aux données et depuis un R.R.1 VG peut être fourni par un PV RAID1 pour de bonnes performances de lecture aléatoire (en moyenne). Remarque cependant, que les deux.R.n et rs.W.n ne peut pas être fourni avec seulement 2 disques pour toute valeur de n.
- La haute disponibilité:
- Si un disque échoue, le système continuera de travailler dans un mode dégradé.
- la flexibilité:
- Comme la disposition vous permet de redimensionner les volumes à volonté;
- performance:
- Comme vous pouvez choisir un système de fichiers (EXT2 / 3, XFS, etc.) selon les modèles d'accès aux données, et puisque R.R.1 et Rs.Rw.0 peut être fourni avec 2 disques grâce à RAID1 et RAID0.
- Disponibilité moyenne:
- Si un disque échoue, les données importantes resteront accessibles, mais le système ne pourra pas fonctionner correctement à moins que certaines actions ne soient prises pour cartographier /.TMP et échange sur un autre LV mappé à un VG en toute sécurité.
Utilisation du bureau, haute disponibilité, 2 disques.
Ici (voir la disposition inférieure de la figure 2), notre préoccupation est la haute disponibilité. Puisque nous n'avons que deux disques, seul RAID1 peut être utilisé. Cette configuration fournit:
Note: La région d'échange doit être sur le PV RAID1 afin d'assurer la haute disponibilité.
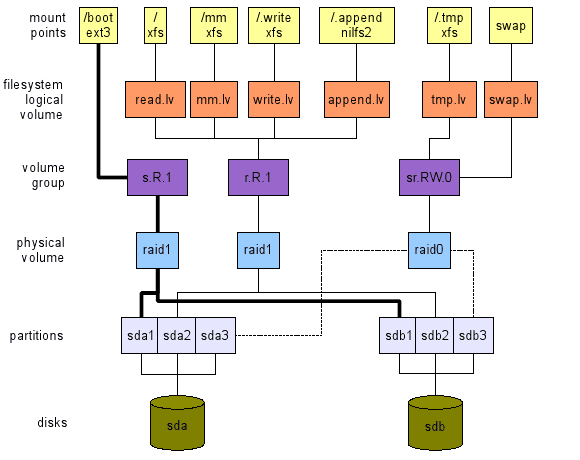
Utilisation du bureau, haute performance, 2 disques
Ici (voir la disposition supérieure de la figure 3), notre préoccupation est une performance élevée. Notez cependant que je considère toujours inacceptable pour perdre des données. Cette disposition fournit les éléments suivants:
- Note: La région d'échange est fabriquée à partir du RS.Rw.0 VG mis en œuvre par le PV RAID0 pour assurer la flexibilité (redimensionner les régions d'échange est indolore). Une autre option consiste à utiliser directement une quatrième partition à partir des deux disques.
Figure 3: En haut: mise en page pour une utilisation de bureau haute performance avec deux disques. En bas: mise en page pour le serveur de fichiers avec quatre disques.
- la flexibilité:
- Comme la disposition vous permet de redimensionner les volumes à volonté;
- performance:
- Comme vous pouvez choisir un système de fichiers (EXT2 / 3, XFS, etc.) selon les modèles d'accès aux données, et depuis les deux RS.R.1 et Rs.Rw.1 peut être fourni avec 4 disques grâce à RAID5 et RAID10.
- La haute disponibilité:
- Si un disque échoue, les données resteront accessibles et le système pourra fonctionner correctement.
- Soit vous avez suffisamment de stockage, soit / et vos utilisateurs ont des besoins d'accès à l'écriture aléatoires / séquentiels élevés, le PV RAID10 est la bonne option;
- Ou, vous n'avez pas assez de stockage ou / et vos utilisateurs n'ont pas de besoins d'accès à l'écriture aléatoires / séquentiels élevés, le PV RAID5 est la bonne option.
Serveur de fichiers, 4 disques.
Ici (voir la disposition inférieure de la figure 3), notre préoccupation est à la fois haute performance et haute disponibilité. Cette disposition fournit les éléments suivants:
Note 1:
Nous avons peut-être utilisé RAID10 pour l'ensemble du système car il fournit une très bonne mise en œuvre de RS.Rw.1 VG (et d'une certaine manière aussi RS.Rw.2). Malheureusement, cela est livré avec un coût: 4 dispositifs de stockage sont nécessaires (ici partitions), chacune des mêmes capacités (laissez dire S = 500 gigaoctets). Mais le volume physique RAID10 ne fournit pas de capacité 4 * (2 téraoctets) comme vous pouvez vous y attendre. Il n'en fournit que la moitié, 2 * S (1 téraoctets). Les 2 * S (1 téraoctets) sont utilisés pour la haute disponibilité (miroir). Voir la documentation RAID pour plus de détails. Par conséquent, je choisis d'utiliser RAID5 pour implémenter RS.R.1. RAID5 fournira une capacité 3 * (1.5 gigaoctets), le S restant (500 gigaoctets) est utilisé pour la haute disponibilité. Le mm.LV nécessite généralement une grande quantité d'espace de stockage car il contient des fichiers multimédias.
Note 2:
Si vous exportez via NFS ou les répertoires «à domicile», vous pouvez considérer avec soin leur emplacement. Si vos utilisateurs ont besoin de beaucoup d'espace, de faire des maisons sur l'écriture.LV (l'emplacement de «Fit-All») peut être coûteux de stockage car il est soutenu par un PV RAID10 où la moitié de l'espace de stockage est utilisé pour la mise en miroir (et les performances). Vous avez deux options ici:
Questions, commentaires et suggestions
Si vous avez une question, un commentaire et / ou une suggestion sur ce document, n'hésitez pas à me contacter à l'adresse suivante: Pierre @ Vigneras.nom.
Droits d'auteur
Ce document est autorisé sous un Creative Commons Attribution-partage 2.0 Licence de France.
Clause de non-responsabilité
Les informations contenues dans ce document sont à des fins d'information générales uniquement. Les informations sont fournies par Pierre Vignéras et bien que je m'efforce de garder les informations à jour et à corriger, je ne fais aucune représentation ou garantie d'aucune sorte, expresse ou implicite, sur l'exhaustivité, l'exactitude, la fiabilité, l'aptitude ou la disponibilité en ce qui concerne le document ou les informations, produits, services ou graphiques connexes contenus dans le document à quelque fin que ce soit.
Toute dépendance que vous accordez à ces informations est donc strictement à vos risques et périls. En aucun cas, je serons responsables de toute perte ou dommage, y compris sans limitation, une perte ou des dommages indirects ou consécutifs, ou toute perte ou dommage résultant de la perte de données ou de bénéfices résultant de, ou en relation avec l'utilisation de cette document.
Grâce à ce document, vous pouvez créer un lien vers d'autres documents qui ne sont pas sous le contrôle de Pierre Vignéras. Je n'ai aucun contrôle sur la nature, le contenu et la disponibilité de ces sites. L'inclusion de tout lien n'implique pas nécessairement une recommandation ou approuve les opinions exprimées en eux.
Tutoriels Linux connexes:
- Choses à installer sur Ubuntu 20.04
- Choses à faire après l'installation d'Ubuntu 20.04 Focal Fossa Linux
- Fichiers de configuration Linux: 30 premiers
- Choses à faire après l'installation d'Ubuntu 22.04 Jammy Jellyfish…
- Comment vérifier une santé du disque dur à partir de la ligne de commande…
- Mint 20: Mieux que Ubuntu et Microsoft Windows?
- Téléchargement Linux
- Ubuntu 20.04 Guide
- Manjaro Linux Windows 10 Double démarrage
- Une introduction à l'automatisation Linux, des outils et des techniques
- « 101 HowpO de commencer par OpenCV et Vision par ordinateur sur Ubuntu Linux
- Problème de clés de flèche VMware sur Ubuntu »