

Shell Linux supprime les lignes en double du fichier
- 4653
- 1188
- Emilie Colin
Bash est l'un des coquilles les plus populaires et est utilisé par de nombreux utilisateurs de Linux. L'une des grandes choses que vous pouvez faire avec Bash est supprimé les lignes en double des fichiers. C'est un excellent moyen de désencombrer un fichier et de le rendre plus propre et plus organisé. Cela peut être fait avec une commande simple dans le shell bash.
Tout ce que vous avez à faire est de saisir la commande "Trier -u" suivi du nom du fichier. Cela prendra le fichier et triera le contenu, puis utilise la commande "Uniq" Pour supprimer tous les doublons. C'est un moyen facile et efficace de supprimer les lignes en double de vos fichiers. Si vous êtes un utilisateur Linux, c'est un excellent outil à avoir dans votre arsenal. Donc, la prochaine fois que vous devez nettoyer un fichier, essayez cette commande bash et voyez comment cela fonctionne pour vous!
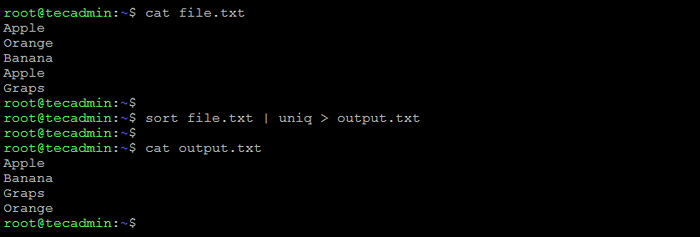
Suppression des lignes en double du fichier
Pour supprimer les lignes en double d'un fichier en bash, vous pouvez utiliser les commandes de tri et UNIQ.
Voici un exemple de la façon de le faire:
trier.txt | UNIQ> Sortie.SMS Cela triera les lignes dans déposer.SMS, Supprimer les doublons et enregistrer le résultat dans un nouveau fichier appelé sortie.SMS.
Suppression des lignes en double du fichierVous pouvez également utiliser le -u Option de la commande de tri pour obtenir le même résultat:
Trier -u fichier.TXT> Sortie.SMS Si vous souhaitez supprimer les doublons en place, sans créer de nouveau fichier, vous pouvez utiliser la commande TEE pour rediriger la sortie vers le fichier d'origine:
trier.txt | Uniq | fichier.SMS[OU]Trier -u fichier.txt | fichier.SMS
Gardez à l'esprit que ces commandes ne supprimeront les doublons que si les lignes sont exactement les mêmes. Si vous souhaitez ignorer l'espace blanc en tête ou en arrière ou des différences de cas, vous pouvez utiliser le -je, -b, et -F Options, respectivement. Par exemple:
Trier -f -u fichier.TXT> Sortie.SMS Cela supprimera les doublons, ignorant les différences de cas.
Trier -f -b -u fichier.TXT> Sortie.SMS Cela supprimera les doublons, ignorera les différences de cas et l'espace blanc dirigeant / traînant.
- « Comment ouvrir le port pour un réseau spécifique dans le pare-feu
- Configuration du proxy inversé Nginx devant Apache »