

Suppression des lignes en double d'un fichier texte à l'aide de la ligne de commande Linux
- 1466
- 223
- Jeanne Dupont
La suppression des lignes en double d'un fichier texte peut être effectuée à partir de la ligne de commande Linux. Une telle tâche peut être plus courante et nécessaire que vous ne le pensez. Le scénario le plus courant où cela peut être utile est avec les fichiers journaux. Souvent, les fichiers journaux répéteront les mêmes informations encore et encore, ce qui rend le fichier presque impossible à parcourir, ce qui rend parfois les journaux.
Dans ce guide, nous afficherons divers exemples de ligne de commande que vous pouvez utiliser pour supprimer les lignes en double d'un fichier texte. Essayez certaines des commandes sur votre propre système et utilisez le plus pratique pour votre scénario.
Dans ce tutoriel, vous apprendrez:
- Comment supprimer les lignes en double du fichier lors du tri
- Comment compter le nombre de lignes en double dans un fichier
- Comment supprimer les lignes en double sans trier le fichier
Divers exemples pour supprimer les lignes en double d'un fichier texte sur Linux | Catégorie | Exigences, conventions ou version logicielle utilisée |
|---|---|
| Système | Toute distribution Linux |
| Logiciel | Coquille |
| Autre | Accès privilégié à votre système Linux en tant que racine ou via le Sudo commande. |
| Conventions | # - Exige que les commandes Linux soient exécutées avec des privilèges racine soit directement en tant qu'utilisateur racine, soit par l'utilisation de Sudo commande$ - Exige que les commandes Linux soient exécutées en tant qu'utilisateur non privilégié régulier |
Supprimer les lignes en double du fichier texte
Ces exemples fonctionneront sur n'importe quelle distribution Linux, à condition que vous utilisiez le shell bash.
Pour notre exemple de scénario, nous travaillerons avec le fichier suivant, qui contient juste les noms de diverses distributions Linux. Ceci est un fichier texte très simple pour un exemple, mais en réalité, vous pouvez utiliser ces méthodes sur des documents contenant même des milliers de lignes répétées. Nous verrons comment supprimer tous les doublons de ce fichier en utilisant les exemples ci-dessous.
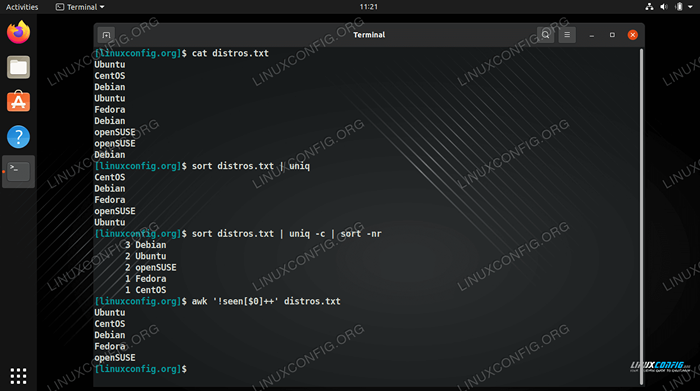
$ Distros de chat.txt ubuntu centos debian ubuntu fedora debian opensuse opensuse debian
- Le
uniqLa commande est capable d'isoler toutes les lignes uniques de notre fichier, mais cela ne fonctionne que si les lignes en double sont adjacentes les unes aux autres. Pour que les lignes soient adjacentes, elles devraient d'abord être triees dans l'ordre alphabétique. La commande suivante fonctionnerait en utilisanttrieretuniq.$ Distros de tri.txt | Uniq Centos Debian Fedora OpenSuse Ubuntu
Pour faciliter les choses, nous pouvons simplement utiliser le
-uavec un tri pour obtenir le même résultat exact, au lieu de tuyauter à Uniq.
$ Sort -u Distros.txt Centos Debian Fedora OpenSuse Ubuntu
- Pour voir combien d'occurrences de chaque ligne se trouve dans le fichier, nous pouvons utiliser le
-c(Count) Option avec Uniq.$ Distros de tri.txt | Uniq -C 1 Centos 3 Debian 1 Fedora 2 OpenSUSE 2 Ubuntu
- Pour voir les lignes qui se répètent le plus souvent, nous pouvons tuer à une autre commande de tri avec le
-n(tri numérique) et-rOptions inversées. Cela nous permet de voir rapidement quelles lignes sont les plus dupliquées dans le fichier - une autre option pratique pour passer au filtre les journaux.$ Distros de tri.txt | Uniq -C | Trier -Nr 3 Debian 2 Ubuntu 2 OpenSUSUS 1 Fedora 1 Centos
- Un problème avec l'utilisation des commandes précédentes est que nous comptons sur
trier. Cela signifie que notre sortie finale est triée par ordre alphabétique ou triée par quantité de répétitions comme dans l'exemple précédent. Cela peut être une bonne chose parfois, mais que se passe-t-il si nous avons besoin du fichier texte pour conserver son ordre précédent? Nous pouvons éliminer les lignes en double sans trier le fichier en utilisant leawkcommande dans la syntaxe suivante.$ awk '!Distros [0 0] ++ '.txt ubuntu centos debian fedora opensuse
Avec cette commande, la première occurrence d'une ligne est conservée et les futures lignes en double sont supprimées de la sortie.
- Les exemples précédents enverront la sortie directement à votre terminal. Si vous souhaitez un nouveau fichier texte avec vos lignes en double filtrées, vous pouvez adapter l'un de ces exemples en utilisant simplement le
>Bash Operator comme dans la commande suivante.$ awk '!Distros [0 0] ++ '.txt> Distros-new.SMS
Il s'agit de toutes les commandes dont vous avez besoin pour déposer des lignes en double à partir d'un fichier, tout en trier ou compter les lignes. Plus de méthodes existent, mais ce sont les plus faciles à utiliser et à retenir.
Réflexions de clôture
Dans ce guide, nous avons vu divers exemple de commande pour supprimer les lignes en double d'un fichier texte sur Linux. Vous pouvez appliquer ces commandes sur les fichiers journaux ou tout autre type de fichier en texte clair qui a des lignes en double. Nous avons également appris à trier les lignes d'un fichier texte ou à compter le nombre de doublons, car cela peut parfois accélérer l'isolement des informations dont nous avons besoin à partir d'un document.
Tutoriels Linux connexes:
- Choses à installer sur Ubuntu 20.04
- Comment améliorer le rendu de la police de Firefox sur Linux
- Une introduction à l'automatisation Linux, des outils et des techniques
- Masterring Bash Script Loops
- Choses à faire après l'installation d'Ubuntu 20.04 Focal Fossa Linux
- Commandes Linux: les 20 meilleures commandes les plus importantes que vous devez…
- Commandes Linux de base
- Comment monter l'image ISO sur Linux
- Fichiers de configuration Linux: 30 premiers
- Exemples RSync dans Linux
- « Exemple de réseautage de base sur la façon de connecter les conteneurs Docker
- Comment configurer NFS sur Linux »