

Ubuntu 20.04 Hadoop

- 2672
- 154
- Anaïs Charles
Apache Hadoop est composé de plusieurs packages de logiciels open source qui fonctionnent ensemble pour le stockage distribué et le traitement distribué des mégadonnées. Il y a quatre composants principaux à Hadoop:
- Hadoop commun - les différentes bibliothèques de logiciels dont Hadoop dépend pour exécuter
- Système de fichiers distribué Hadoop (HDFS) - un système de fichiers qui permet une distribution et un stockage efficaces du mégadon
- Hadoop Mapreduce - utilisé pour le traitement des données
- Fil Hadoop - une API qui gère l'attribution des ressources informatiques pour l'ensemble du cluster
Dans ce tutoriel, nous passerons en revue les étapes pour installer Hadoop Version 3 sur Ubuntu 20.04. Cela impliquera l'installation de HDFS (Namenode et Datanode), de fil et de MapReduce sur un seul cluster de nœuds configuré en mode pseudo distribué, qui est une simulation distribuée sur une seule machine. Chaque composant de Hadoop (HDFS, YARN, MapReduce) fonctionnera sur notre nœud en tant que processus Java séparé.
Dans ce tutoriel, vous apprendrez:
- Comment ajouter des utilisateurs pour un environnement Hadoop
- Comment installer Java Préalable
- Comment configurer SSH sans mot de passe
- Comment installer Hadoop et configurer les fichiers XML liés nécessaires
- Comment démarrer le cluster Hadoop
- Comment accéder à Namenode et à ResourceManager Web UI
Apache Hadoop sur Ubuntu 20.04 FOCAL FOSSA | Catégorie | Exigences, conventions ou version logicielle utilisée |
|---|---|
| Système | Installé Ubuntu 20.04 ou Ubuntu 20 amélioré.04 FOCAL FOSSA |
| Logiciel | Apache Hadoop, Java |
| Autre | Accès privilégié à votre système Linux en tant que racine ou via le Sudo commande. |
| Conventions | # - Exige que les commandes Linux soient exécutées avec des privilèges racine soit directement en tant qu'utilisateur racine, soit par l'utilisation de Sudo commande$ - Exige que les commandes Linux soient exécutées en tant qu'utilisateur non privilégié régulier |
Créer un utilisateur pour l'environnement Hadoop
Hadoop devrait avoir son propre compte d'utilisateur dédié sur votre système. Pour en créer un, ouvrez un terminal et tapez la commande suivante. Vous serez également invité à créer un mot de passe pour le compte.
$ sudo addUser Hadoop
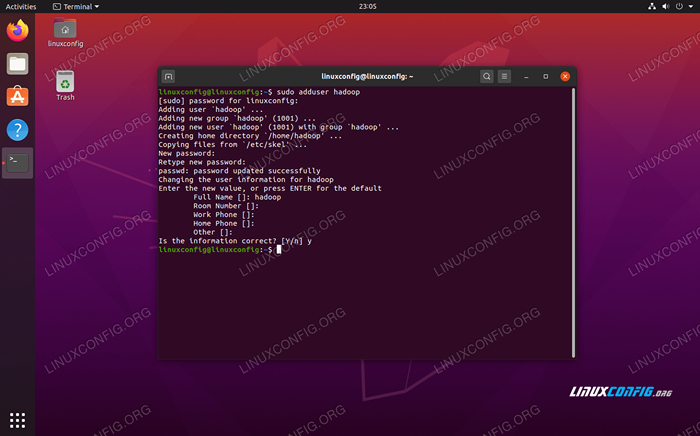 Créer un nouvel utilisateur Hadoop
Créer un nouvel utilisateur Hadoop Installez la condition préalable Java
Hadoop est basé sur Java, vous devrez donc l'installer sur votre système avant de pouvoir utiliser Hadoop. Au moment d'écrire ces lignes, la version 3 de Hadoop actuelle.1.3 nécessite Java 8, c'est donc ce que nous allons installer sur notre système.
Utilisez les deux commandes suivantes pour récupérer les dernières listes de packages dans apte et installer Java 8:
$ sudo apt mise à jour $ sudo apt install openjdk-8-jdk openjdk-8-jre
Configurer SSH sans mot de passe
Hadoop s'appuie sur SSH pour accéder à ses nœuds. Il se connectera aux machines distantes via SSH ainsi que votre machine locale si vous avez Hadoop en cours d'exécution. Donc, même si nous ne confions que Hadoop sur notre machine locale dans ce tutoriel, nous devons toujours faire installer SSH. Nous devons également configurer SSH sans mot de passe
Pour que Hadoop puisse établir silencieusement des connexions en arrière-plan.
- Nous aurons besoin du package client OpenSSH Server et OpenSSH. Installez-les avec cette commande:
$ sudo apt install openssh-server openssh-client
- Avant de continuer plus loin, il est préférable d'être connecté au
hadoopcompte d'utilisateur que nous avons créé plus tôt. Pour modifier les utilisateurs dans votre terminal actuel, utilisez la commande suivante:$ su Hadoop
- Avec ces packages installés, il est temps de générer des paires de clés publiques et privées avec la commande suivante. Notez que le terminal vous invitera plusieurs fois, mais tout ce que vous devrez faire est de continuer à frapper
ENTRERprocéder.$ ssh-keygen -t rsa
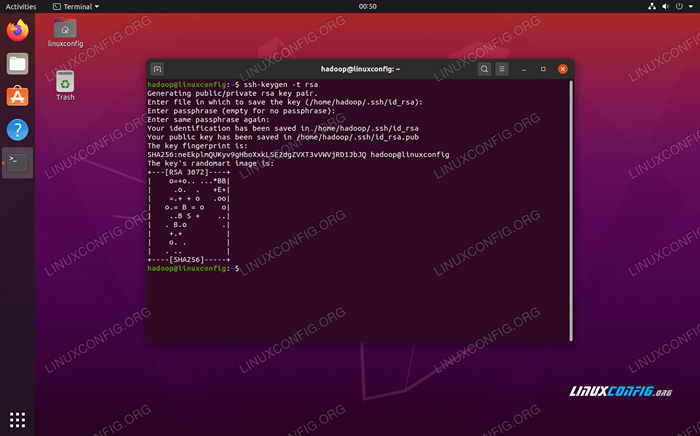 Générer des clés RSA pour SSH sans mot de passe
Générer des clés RSA pour SSH sans mot de passe - Ensuite, copiez la clé RSA nouvellement générée dans
id_rsa.pubversautorisé_keys:$ cat ~ /.ssh / id_rsa.pub >> ~ /.SSH / AUTORISED_KEYS
- Vous pouvez vous assurer que la configuration a été réussie en sshing dans localhost. Si vous pouvez le faire sans être invité à un mot de passe, vous êtes prêt à partir.
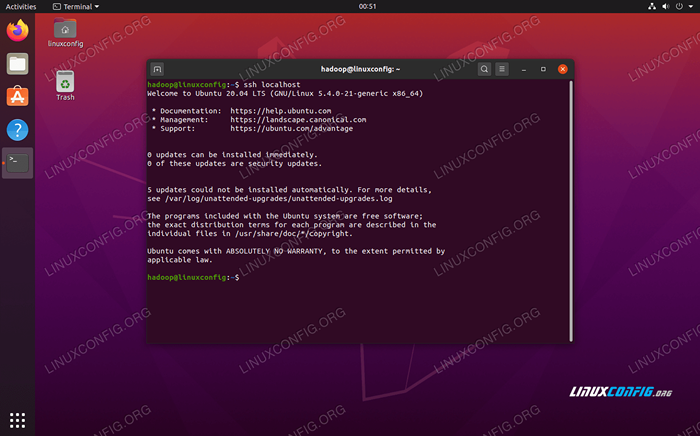 Sshing dans le système sans être invité à mot de passe signifie qu'il a fonctionné
Sshing dans le système sans être invité à mot de passe signifie qu'il a fonctionné
Installez Hadoop et configurez les fichiers XML connexes
Rendez-vous sur le site Web d'Apache pour télécharger Hadoop. Vous pouvez également utiliser cette commande si vous souhaitez télécharger la version 3 de Hadoop.1.3 binaire directement:
$ wget https: // téléchargements.apache.org / hadoop / commun / hadoop-3.1.3 / Hadoop-3.1.3.le goudron.gz
Extraire le téléchargement sur le hadoop Répertoire personnel de l'utilisateur avec cette commande:
$ TAR -XZVF HADOOP-3.1.3.le goudron.GZ -C / Home / Hadoop
Configuration de la variable d'environnement
Ce qui suit exporter Les commandes configureront les variables d'environnement Hadoop requises sur notre système. Vous pouvez copier et coller tous ces éléments sur votre terminal (vous devrez peut-être modifier la ligne 1 si vous avez une version différente de Hadoop):
exporter hadoop_home = / home / hadoop / hadoop-3.1.3 export hadoop_install = $ hadoop_home export hadoop_mapred_home = $ hadoop_home export hadoop_common_home = $ hadoop_home export hadoop_hdfs_home = $ hadoop_home export yarn_home = $ hadoop_home export hadoop_common_lib_native_dir = $ hadhome_home_hoom / binome " exporter hadoop_opts = "- djava.bibliothèque.path = $ hadoop_home / lib / natif "Source le .bashrc Fichier dans la session de connexion actuelle:
$ source ~ /.bashrc
Ensuite, nous allons apporter quelques modifications au Hadoop-env.shot Fichier, qui peut être trouvé dans le répertoire d'installation Hadoop sous / etc / hadoop. Utilisez Nano ou votre éditeur de texte préféré pour l'ouvrir:
$ nano ~ / hadoop-3.1.3 / etc / hadoop / hadoop-env.shot
Changer la Java_home variable à où Java est installé. Sur notre système (et probablement le vôtre aussi, si vous utilisez Ubuntu 20.04 Et nous avons suivi avec nous jusqu'à présent), nous changeons cette ligne en:
Exporter java_home = / usr / lib / jvm / java-8-openjdk-amd64
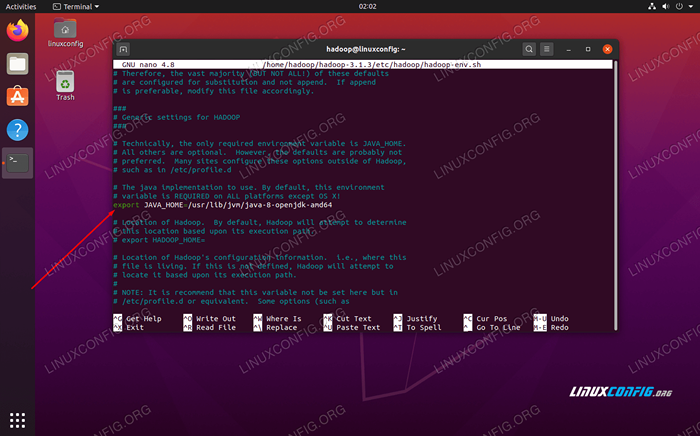 Changer la variable de l'environnement Java_Home
Changer la variable de l'environnement Java_Home Ce sera le seul changement que nous devons apporter ici. Vous pouvez enregistrer vos modifications dans le fichier et la fermer.
Modifications de configuration dans le site core.fichier xml
Le prochain changement que nous devons faire est à l'intérieur du site de base.xml déposer. Ouvrez-le avec cette commande:
$ nano ~ / hadoop-3.1.3 / etc / Hadoop / Core Site.xml
Entrez la configuration suivante, qui demande aux HDF de s'exécuter sur le port localhost 9000 et configure un répertoire pour les données temporaires.
FS.defaultfs hdfs: // localhost: 9000 hadoop.TMP.dir / home / hadoop / hadooptmpdata 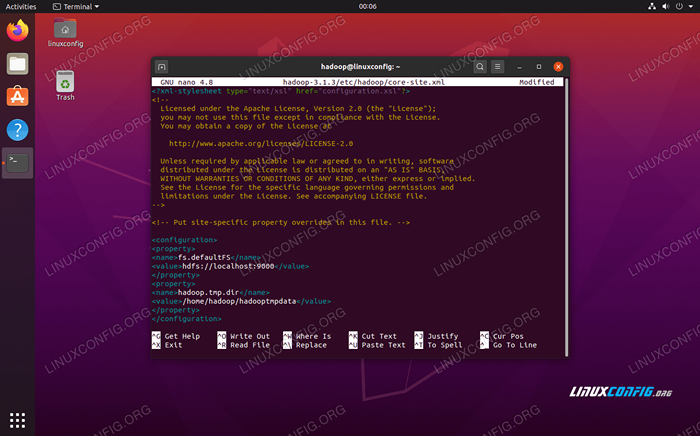 site de base.Modifications du fichier de configuration XML
site de base.Modifications du fichier de configuration XML Enregistrez vos modifications et fermez ce fichier. Ensuite, créez le répertoire dans lequel les données temporaires seront stockées:
$ mkdir ~ / hadooptmpdata
Modifications de configuration dans le site HDFS.fichier xml
Créez deux nouveaux répertoires pour Hadoop pour stocker les informations Namenode et Datanode.
$ mkdir -p ~ / hdfs / namenode ~ / hdfs / datanode
Ensuite, modifiez le fichier suivant pour dire à Hadoop où trouver ces répertoires:
$ nano ~ / hadoop-3.1.3 / etc / hadoop / hdfs-site.xml
Apporter les modifications suivantes au site HDFS.xml fichier, avant de l'enregistrer et de la clôturer:
DFS.réplication 1 DFS.nom.DIR FILE: /// home / hadoop / hdfs / namenode dfs.données.DIR FILE: /// home / hadoop / hdfs / datanode 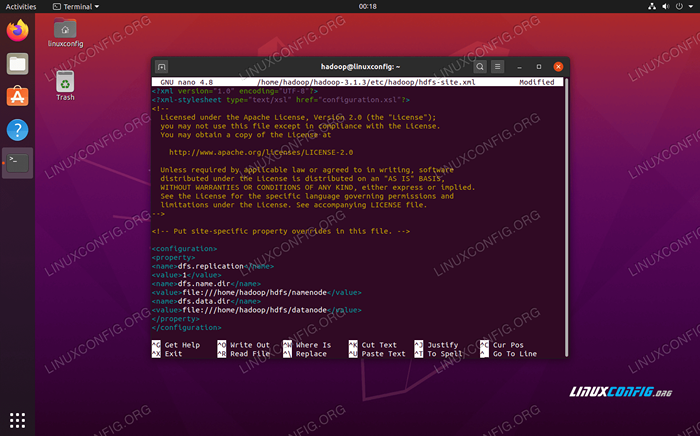 site HDFS.Modifications du fichier de configuration XML
site HDFS.Modifications du fichier de configuration XML Modifications de configuration dans le site mapred.fichier xml
Ouvrez le fichier de configuration XML MapReduce avec la commande suivante:
$ nano ~ / hadoop-3.1.3 / etc / hadoop / site mapred.xml
Et apporter les modifications suivantes avant d'enregistrer et de fermer le fichier:
mapreduce.cadre.Nommez le fil 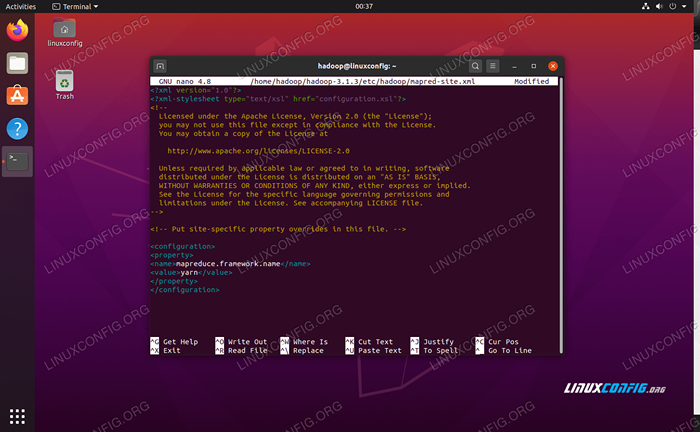 site mapred.Modifications du fichier de configuration XML
site mapred.Modifications du fichier de configuration XML Modifications de configuration dans le site de fil.fichier xml
Ouvrez le fichier de configuration du fil avec la commande suivante:
$ nano ~ / hadoop-3.1.3 / etc / hadoop / yarn-site.xml
Ajoutez les entrées suivantes dans ce fichier, avant d'enregistrer les modifications et de la clôturer:
mapreduceyarn.nodemanager.Aux-Services MapReduce_Shuffle 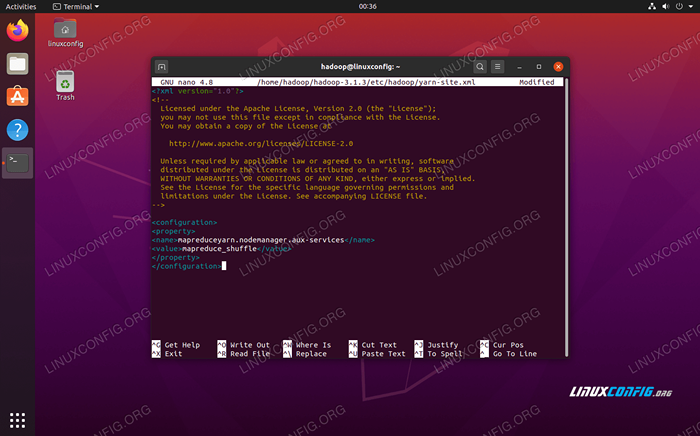 Modifications du fichier de configuration du site de fil
Modifications du fichier de configuration du site de fil Démarrer le cluster Hadoop
Avant d'utiliser le cluster pour la première fois, nous devons formater le namenode. Vous pouvez le faire avec la commande suivante:
$ hdfs namenode -format
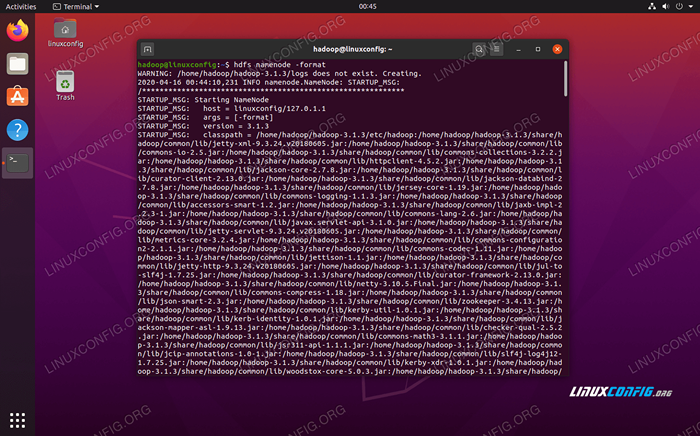 Formatage du namenode HDFS
Formatage du namenode HDFS Votre terminal crachera beaucoup d'informations. Tant que vous ne voyez aucun message d'erreur, vous pouvez supposer que cela a fonctionné.
Ensuite, démarrez les HDF en utilisant le start-dfs.shot scénario:
$ start-dfs.shot
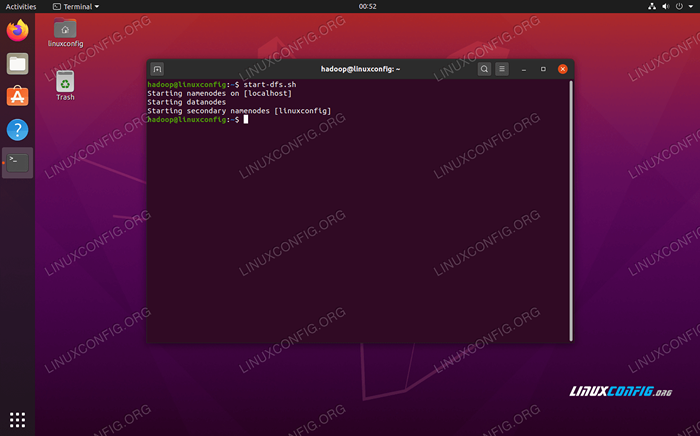 Exécutez le début-DFS.script
Exécutez le début-DFS.script Maintenant, démarrez les services de fil via le démarrage.shot scénario:
$ start-yarn.shot
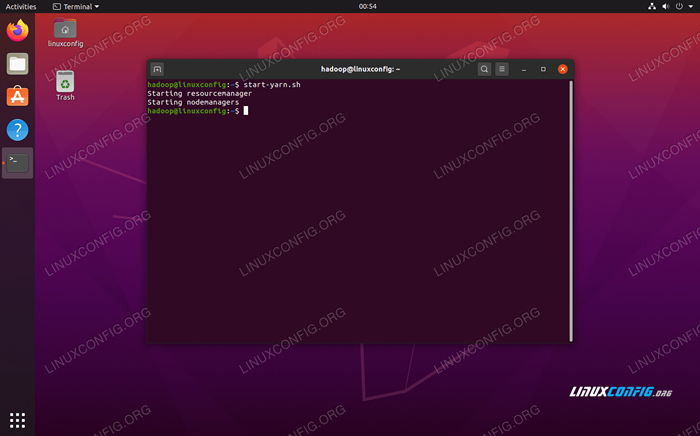 Exécutez le start-yarn.script
Exécutez le start-yarn.script Pour vérifier que tous les services / daémons Hadoop sont lancés avec succès, vous pouvez utiliser le JPS commande. Cela montrera tous les processus qui utilisent actuellement Java qui s'exécutent sur votre système.
$ jps
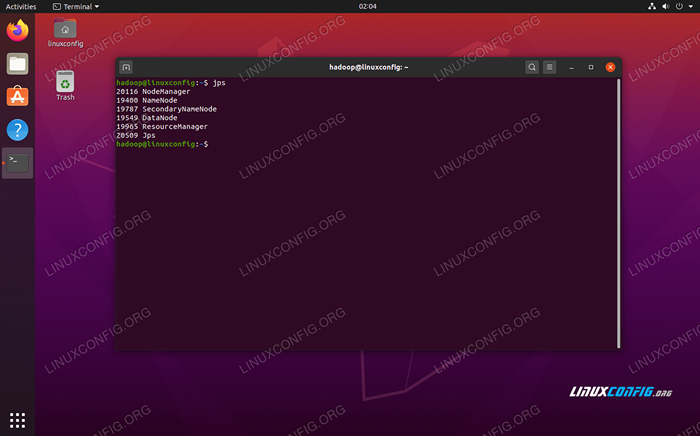 Exécuter JPS pour voir tous les processus dépendants de Java et vérifier que les composants Hadoop s'exécutent
Exécuter JPS pour voir tous les processus dépendants de Java et vérifier que les composants Hadoop s'exécutent Maintenant, nous pouvons vérifier la version Hadoop actuelle avec l'une des commandes suivantes:
$ Hadoop Version
ou
Version HDFS $
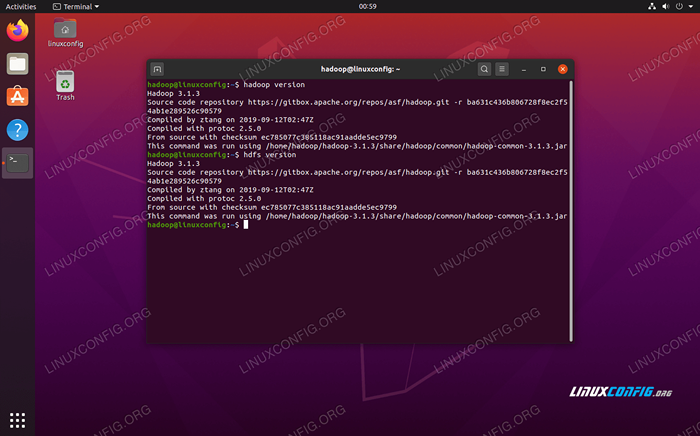 Vérification de l'installation de Hadoop et de la version actuelle
Vérification de l'installation de Hadoop et de la version actuelle Interface de ligne de commande HDFS
La ligne de commande HDFS est utilisée pour accéder à HDFS et pour créer des répertoires ou émettre d'autres commandes pour manipuler des fichiers et des répertoires. Utilisez la syntaxe de commande suivante pour créer certains répertoires et les répertorier:
$ hdfs dfs -mkdir / test $ hdfs dfs -mkdir / hadooponubuntu $ hdfs dfs -ls /
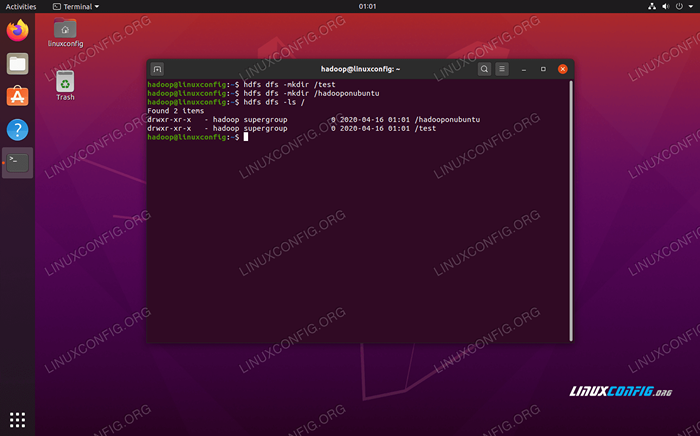 Interagir avec la ligne de commande HDFS
Interagir avec la ligne de commande HDFS Accéder au Namenode et au fil du navigateur
Vous pouvez accéder à la fois sur l'interface utilisateur Web pour NameNode et Yarn Resource Manager via n'importe quel navigateur de votre choix, comme Mozilla Firefox ou Google Chrome.
Pour l'interface utilisateur Web Namenode, accédez à http: // hadoop-hostname-or-ip: 50070
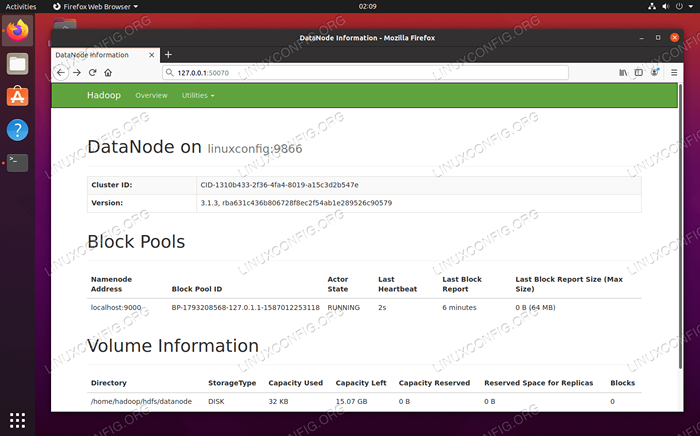 Interface Web de Datanode pour Hadoop
Interface Web de Datanode pour Hadoop Pour accéder à l'interface Web de gestion des ressources YARN, qui affichera tous les travaux en cours d'exécution sur le cluster Hadoop, accédez à http: // hadoop-hostname-or-ip: 8088
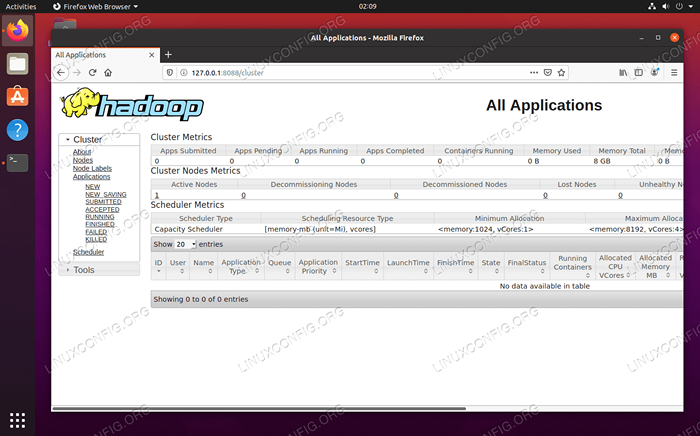 Interface Web du gestionnaire de ressources de fil pour Hadoop
Interface Web du gestionnaire de ressources de fil pour Hadoop Conclusion
Dans cet article, nous avons vu comment installer Hadoop sur un seul cluster de nœuds dans Ubuntu 20.04 FOCAL FOSSA. Hadoop nous fournit une solution d'orientation pour faire face aux mégadonnées, ce qui nous permet d'utiliser des clusters pour le stockage et le traitement de nos données. Cela nous facilite la vie lorsque vous travaillez avec de grands ensembles de données avec sa configuration flexible et son interface Web pratique.
Tutoriels Linux connexes:
- Choses à installer sur Ubuntu 20.04
- Comment créer un cluster Kubernetes
- Ubuntu 20.04 WordPress avec installation Apache
- Comment installer Kubernetes sur Ubuntu 20.04 Focal Fossa Linux
- Comment travailler avec l'API WooCommerce REST avec Python
- Boucles imbriquées dans les scripts bash
- Choses à faire après l'installation d'Ubuntu 20.04 Focal Fossa Linux
- Masterring Bash Script Loops
- Comment installer Kubernetes sur Ubuntu 22.04 Jammy Jellyfish…
- Une introduction à l'automatisation Linux, des outils et des techniques