

Hadoop - Exécution d'un exemple de MapReduce WordCount
- 4646
- 1396
- Victor Charpentier
Ce tutoriel vous aidera à exécuter un exemple de MapReduce WordCount dans Hadoop en utilisant la ligne de commande. Cela peut également être un test initial pour vos tests de configuration Hadoop.
1. Conditions préalables
Vous devez avoir une configuration de Hadoop sur votre système. Si vous n'avez pas installé Hadoop, visitez Hadoop Installation sur le tutoriel Linux.
2. Copier les fichiers sur le système de fichiers NameNode
Après avoir réussi à formater Namenode, vous devez avoir démarré correctement tous les services Hadoop. Créez maintenant un répertoire dans le système de fichiers Hadoop.
$ hdfs dfs -mkdir -p / user / hadoop / entrée
Copiez copier un fichier texte sur le système de fichiers Hadoop dans le répertoire d'entrée. Ici je copie une licence.txt. Vous pouvez copier plus que les fichiers.
$ HDFS DFS -PUT LICENCE.txt / user / hadoop / input /
3. Commande de WordCount en cours d'exécution
Maintenant, exécutez l'exemple MapReduce WordCount en utilisant la commande suivante. La commande ci-dessous lira tous les fichiers du dossier d'entrée et le processus avec le fichier de jar MapReduce. Une fois réussi, les résultats de la tâche seront placés sur le répertoire de sortie.
$ CD $ HADOOP_HOME $ HADOOP JAR Partage / Hadoop / MapReduce / Hadoop-Mapreduce-Examples-2.6.0.sortie d'entrée de nombre de mots jar
4. Montrer les résultats
Vérifiez d'abord les noms du fichier de résultat créé sous [Système de fichiers User / User / Hadoop / Output à l'aide de la commande suivante.
$ hdfs dfs -ls / utilisateur / hadoop / sortie
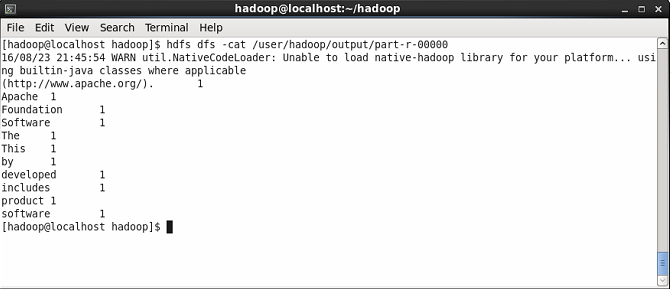
Affichez maintenant le contenu du fichier de résultat où vous verrez le résultat de WordCount. Vous verrez le compte de chaque mot.
$ HDFS DFS -CAT / USER / HADOOP / OUTPUT / Part-R-00000
- « Comment installer Go 1.19 sur Fedora 36/35 & Centos / Rhel 8/7
- Comment installer Apache Maven sur Centos / Rhel 8/7 »