

Comment configurer et maintenir une haute disponibilité / clustering dans Linux
- 3934
- 384
- Maëlle Perez
La haute disponibilité (HA) fait simplement référence à une qualité d'un système pour fonctionner en continu sans échec pendant une longue période. Les solutions HA peuvent être implémentées à l'aide du matériel et / ou des logiciels, et l'une des solutions courantes à l'implémentation de HA est le regroupement.
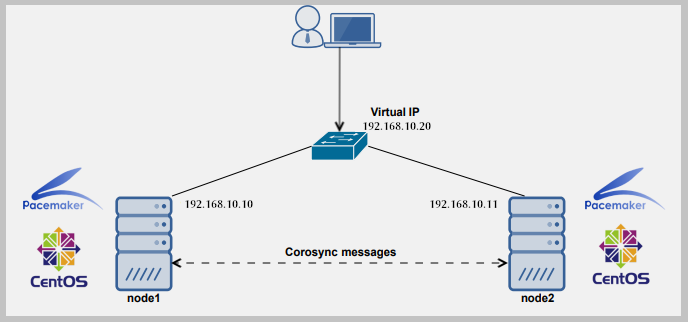
En informatique, un cluster est composé de deux ordinateurs ou plus (communément appelé nœuds ou membres) qui travaillent ensemble pour effectuer une tâche. Dans une telle configuration, un seul nœud fournit au service le (s) nœud secondaire prenant le relais s'il échoue.
Les clusters se répartissent en quatre types principaux:
- Stockage: Fournir une image de système de fichiers cohérente sur les serveurs dans un cluster, permettant aux serveurs de lire et d'écrire simultanément sur un seul système de fichiers partagé.
- La haute disponibilité: éliminer les points de défaillance uniques et en défaillant les services d'un nœud de cluster à un autre au cas où un nœud deviendra inopérant.
- L'équilibrage de charge: Découvrez les demandes de service réseau à plusieurs nœuds de cluster pour équilibrer la charge de demande parmi les nœuds de cluster.
- Haute performance: effectuer un traitement parallèle ou simultané, contribuant ainsi à améliorer les performances des applications.
Une autre solution largement utilisée pour fournir HA est une réplication (spécifiquement les réplications des données). La réplication est le processus par lequel une ou plusieurs bases de données (secondaires) peuvent être maintenues en synchronisation avec une seule base de données principale (ou maître).
Pour configurer un cluster, nous avons besoin d'au moins deux serveurs. Aux fins de ce guide, nous utiliserons deux serveurs Linux:
- Node1: 192.168.dix.dix
- Node2: 192.168.dix.11
Dans cet article, nous démontrerons les bases de la façon de déployer, configurer et maintenir une haute disponibilité / clustering dans Ubuntu 16.04/18.04 et Centos 7. Nous allons montrer comment ajouter le service nginx http au cluster.
Configuration des paramètres DNS locaux sur chaque serveur
Pour que les deux serveurs puissent se communiquer les uns aux autres, nous devons configurer les paramètres DNS locaux appropriés dans le / etc / hôtes fichier sur les deux serveurs.
Ouvrez et modifiez le fichier à l'aide de votre éditeur de ligne de commande préféré.
$ sudo vim / etc / hôtes
Ajoutez les entrées suivantes avec des adresses IP réelles de vos serveurs.
192.168.dix.10 Node1.exemple.com 192.168.dix.11 node2.exemple.com
Enregistrez les modifications et fermez le fichier.
Installation du serveur Web Nginx
Installez maintenant le serveur Web Nginx à l'aide des commandes suivantes.
$ sudo apt install nginx [sur ubuntu] $ sudo yum install epel-release && sudo yum install nginx [sur centos 7]
Une fois l'installation terminée, démarrez le service Nginx pour l'instant et permettez-lui de démarrer automatiquement à l'heure du démarrage, puis vérifiez s'il est opérationnel à l'aide de la commande SystemCTL.
Sur Ubuntu, le service doit être démarré automatiquement immédiatement après la préconfiguration du package terminé, vous pouvez simplement l'activer.
$ sudo systemctl activer nginx $ sudo systemctl start nginx $ sudo systemctl status nginx
Après avoir démarré le service NGINX, nous devons créer des pages Web personnalisées pour identifier et tester les opérations sur les deux serveurs. Nous modifierons le contenu de la page d'index Nginx par défaut comme indiqué.
$ echo "Ceci est la page par défaut pour Node1.exemple.com "| sudo tee / usr / share / nginx / html / index.html # vps1 $ echo "Ceci est la page par défaut pour node2.exemple.com "| sudo tee / usr / share / nginx / html / index.html # vps2
Installation et configuration du corosync et du stimulateur cardiaque
Ensuite, nous devons installer Stimulateur cardiaque, Corosync, et PCS sur chaque nœud comme suit.
$ sudo apt install corosync sacemaker pcs #ubuntu $ sudo yum install corosync sacemaker pcs #centos
Une fois l'installation terminée, assurez-vous que PCS Daemon fonctionne sur les deux serveurs.
$ sudo systemctl activer pcsd $ sudo systemctl start pcsd $ sudo systemctl status pcsd
Créer le cluster
Pendant l'installation, un utilisateur système appelé "Hacluster" est créé. Nous devons donc configurer l'authentification nécessaire pour PCS. Commençons par créer un nouveau mot de passe pour le "Hacluster" Utilisateur, nous devons utiliser le même mot de passe sur tous les serveurs:
$ sudo passwd hacluster
 Créer un mot de passe utilisateur en cluster
Créer un mot de passe utilisateur en cluster Ensuite, sur l'un des serveurs (Node1), exécutez la commande suivante pour configurer l'authentification nécessaire pour PCS.
$ sudo pcs cluster node1.exemple.com node2.exemple.com -u hacluster -p password_here --Force
 Configuration de l'authentification pour PCS
Configuration de l'authentification pour PCS Créez maintenant un cluster et remplissez-le avec quelques nœuds (le nom du cluster ne peut pas dépasser 15 caractères, dans cet exemple, nous avons utilisé examplecluster) sur le serveur Node1.
$ sudo pcs Cluster Configuration - Name ExampleCluster Node1.exemple.com node2.exemple.com
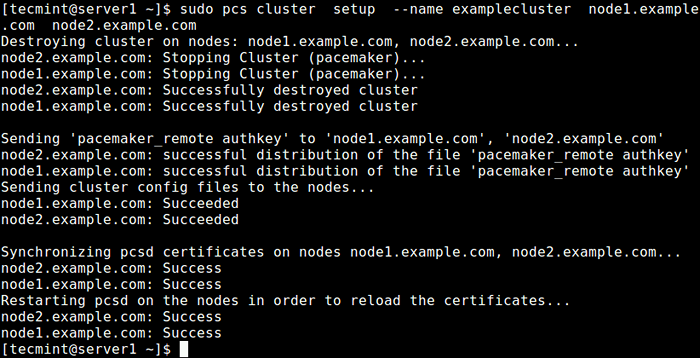 Créer un cluster sur Node1
Créer un cluster sur Node1 Activez maintenant le cluster sur le démarrage et démarrez le service.
$ sudo pcs cluster Activer - tout le cluster de cluster PCS $ sudo - tout
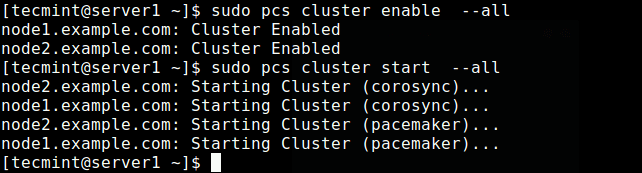 Activer et démarrer le cluster
Activer et démarrer le cluster Vérifiez maintenant si le service de cluster est opérationnel en utilisant la commande suivante.
$ sudo PCS Status ou $ sudo crm_mon -1
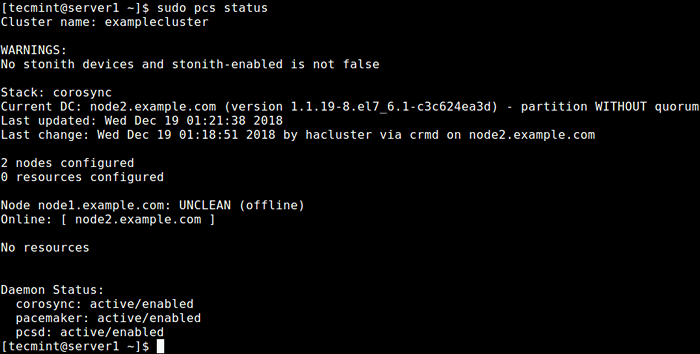 Vérifier l'état du cluster
Vérifier l'état du cluster D'après la sortie de la commande ci-dessus, vous pouvez voir qu'il y a un avertissement Stonith dispositifs pourtant le Stonith est toujours activé dans le cluster. De plus, aucune ressource / services de cluster n'a été configuré.
Configuration des options de cluster
La première option consiste à désactiver Stonith (ou Tirez sur l'autre nœud dans la tête), la mise en œuvre des clôtures sur Stimulateur cardiaque.
Ce composant aide à protéger vos données contre la corruption par un accès simultanément. Aux fins de ce guide, nous le désactiverons car nous n'avons configuré aucun appareils.
Éteindre Stonith, Exécutez la commande suivante:
$ sudo PCS Propriété définir stonith-compatible = false
Ensuite, ignorez également le Quorum Politique en exécutant la commande suivante:
$ sudo PCS Propriété définir sans quorum-politique = ignorer
Après avoir défini les options ci-dessus, exécutez la commande suivante pour voir la liste des propriétés et assurez-vous que les options ci-dessus, stonith et le politique quorum sont handicapés.
Liste de propriétés PCS $ sudo
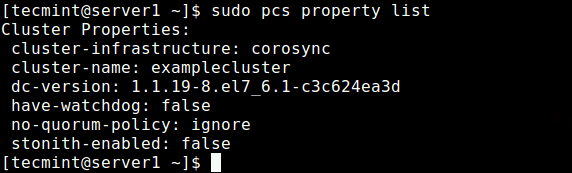 Afficher les propriétés du cluster
Afficher les propriétés du cluster Ajout d'un service de ressources / cluster
Dans cette section, nous examinerons comment ajouter une ressource de cluster. Nous allons configurer une IP flottante qui est l'adresse IP qui peut être déplacée instantanément d'un serveur à un autre dans le même réseau ou au même centre de données. En bref, une IP flottante est un terme commun technique, utilisé pour les IP qui ne sont pas liés strictement à une seule interface.
Dans ce cas, il sera utilisé pour soutenir le basculement dans un cluster à haute disponibilité. Gardez à l'esprit que les IP flottants ne sont pas seulement pour les situations de basculement, ils ont quelques autres cas d'utilisation. Nous devons configurer le cluster de telle manière que seul le membre actif du cluster «possède» ou répond à l'IP flottante à un moment donné.
Nous ajouterons deux ressources de cluster: la ressource d'adresse IP flottante appelée «Floating_ip»Et une ressource pour le serveur Web Nginx appelé«http_server".
Commencez d'abord par ajouter le Floating_ip comme suit. Dans cet exemple, notre adresse IP flottante est 192.168.dix.20.
$ sudo PCS Resource Create Floating_ip OCF: Heartbeat: iPaddr2 ip = 192.168.dix.20 CIDR_NETMASK = 24 OP Interval de moniteur = 60S
où:
- Floating_ip: est le nom du service.
- "OCF: Heartbeat: iPaddr2": indique Pacemaker quel script utiliser, iPaddr2 dans ce cas, dans quel espace de noms il se trouve (Pacemaker) et quelle norme il est conforme à l'OCF.
- "intervalle de moniteur OP = 60S»: Demande de stimulateur cardiaque de vérifier la santé de ce service toutes les minutes en appelant l'action du moniteur de l'agent.
Puis ajoutez la deuxième ressource, nommée http_server. Ici, l'agent de ressources du service est OCF: Roideur cardiaque: nginx.
$ sudo PCS Resource Créer HTTP_SERVER OCF: Heartbeat: Nginx Configfile = "/ etc / nginx / nginx.conf "op monitor timeout =" 20s "interval =" 60s "
Une fois que vous avez ajouté les services de cluster, émettez la commande suivante pour vérifier l'état des ressources.
Ressources d'état PCS $ Sudo $
 Vérifiez les ressources du cluster
Vérifiez les ressources du cluster En regardant la sortie de la commande, les deux ressources ajoutées: "Floating_ip" et "Http_server" ont été répertoriés. Le service Floating_ip est désactivé car le nœud principal est en fonctionnement.
Si le pare-feu est activé sur votre système, vous devez autoriser tout le trafic à Nginx et tous les services de haute disponibilité via le pare-feu pour une communication appropriée entre les nœuds:
-------------- Centos 7 -------------- $ Sudo Firewall-CMD - Permanent --Add-Service = Http $ sudo Firewall-CMD - Permanent --Add-Service = High-Adisponibilité $ sudo Firewall-CMD - Reload -------------- Ubuntu -------------- $ sudo ufw Autoriser http $ sudo ufw Autoriser la haute disponibilité $ sudo ufw recharger
Tester la haute disponibilité / clustering
L'étape finale et importante consiste à tester que notre configuration à haute disponibilité fonctionne. Ouvrez un navigateur Web et accédez à l'adresse 192.168.dix.20 vous devriez voir la page Nginx par défaut de la node2.exemple.com Comme indiqué dans la capture d'écran.
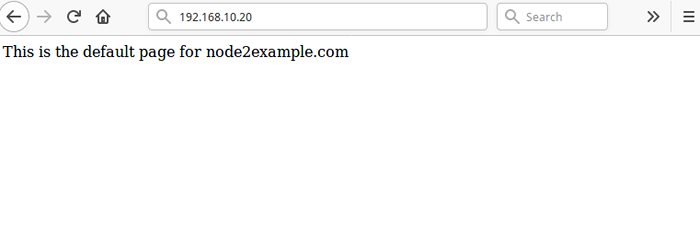 Cluster de test avant l'échec
Cluster de test avant l'échec Pour simuler une panne, exécutez la commande suivante pour arrêter le cluster sur le node2.exemple.com.
$ sudo pcs cluster stop http_server
Puis recharger la page à 192.168.dix.20, Vous devez désormais accéder à la page Web Nginx par défaut à partir du node1.exemple.com.
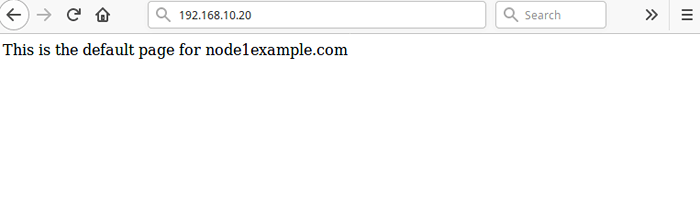 Cluster de test après échec
Cluster de test après échec Alternativement, vous pouvez simuler une erreur en disant au service d'arrêter directement, sans arrêter le cluster sur n'importe quel nœud, en utilisant la commande suivante sur l'un des nœuds:
$ sudo crm_resource --resource http_server --force-stop
Alors tu dois courir CRM_MON En mode interactif (par défaut), dans l'intervalle de moniteur de 2 minutes, vous devriez être en mesure de voir le cluster remarquer que http_server Échec et le déplacer vers un autre nœud.
Pour que vos services de cluster s'exécutent efficacement, vous devrez peut-être définir certaines contraintes. Tu peux voir le PCS Page man (homme PCS) pour une liste de toutes les commandes d'utilisation.
Pour plus d'informations sur Corosync et Pacemaker, consultez: https: // clusterlabs.org /
Résumé
Dans ce guide, nous avons montré les bases de la façon de déployer, configurer et maintenir une haute disponibilité / clustering / réplication dans Ubuntu 16.04/18.04 et Centos 7. Nous avons démontré comment ajouter le service nginx http à un cluster. Si vous avez des pensées à partager ou à questions, utilisez le formulaire de rétroaction ci-dessous.
- « Comment cloner une partition ou un disque dur à Linux
- Comment configurer le client LDAP pour connecter l'authentification externe »