

Comment installer Apache Kafka sur Ubuntu 22.04

- 4247
- 207
- Jade Muller
Apache Kafka est une plate-forme de streaming d'événements distribuée à source ouverte développée par l'Apache Software Foundation. Ceci est écrit dans les langages de programmation Scala et Java. Vous pouvez installer Kafka sur n'importe quelle plate-forme qui prend en charge le langage de programmation Java.
Ce tutoriel vous fournit des instructions étape par étape pour installer Apache Kafka sur Ubuntu 22.04 Système LTS Linux. Vous apprendrez également à créer des sujets dans Kafka et gérer les nœuds producteurs et consommateurs.
Conditions préalables
Vous devez avoir l'accès du compte privilégié sudo à l'Ubuntu 22.04 Système Linux.
Étape 1 - Installation de Java
Nous pouvons exécuter le serveur Apache Kafka sur des systèmes qui prennent en charge Java. Alors assurez-vous que Java a installé sur votre système Ubuntu.
Utilisez les commandes suivantes pour installer OpenJDK sur votre système Ubuntu à partir des référentiels officiels.
Mise à jour Sudo Aptsudo apt installer par défaut-jdk
Vérifiez la version Java active actuelle.
Java - Version Sortie: Version OpenJDK "11.0.15 "2022-04-19 OpenJDK Runtime Environment (Build 11.0.15 + 10-Ubuntu-0ubuntu0.22.04.1) VM du serveur OpenJDK 64 bits (build 11.0.15 + 10-Ubuntu-0ubuntu0.22.04.1, mode mixte, partage)
Étape 2 - Télécharger la dernière apache kafka
Vous pouvez télécharger les derniers fichiers binaires Apache Kafka à partir de sa page de téléchargement officielle. Alternativatiy Vous pouvez télécharger Kafka 3.2.0 avec la commande ci-dessous.
wget https: // dlcdn.apache.org / kafka / 3.2.0 / kafka_2.13-3.2.0.tgz Ensuite, extraire le fichier d'archives téléchargé et placez-les sous / usr / local / kafka annuaire.
Tar XZF Kafka_2.13-3.2.0.tgzsudo mv kafka_2.13-3.2.0 / usr / local / kafka
Étape 3 - Créer des scripts de démarrage SystemD
Maintenant, créez des fichiers d'unité Systemd pour les services Zookeeper et Kafka. Cela vous aidera à démarrer / arrêter le service Kafka d'une manière facile.
Créez d'abord un fichier unitaire Systemd pour ZooKeeper:
Sudo Nano / etc / Systemd / System / Zookeeper.service Et ajouter le contenu suivant:
[Unité] Description = Apache ZooKeeper Server Documentation = http: // ZooKeeper.apache.org requiert = réseau.Target Remote-FS.cible après = réseau.Target Remote-FS.Target [service] type = simple execstart = / usr / local / kafka / bin / zookeeper-server-start.sh / usr / local / kafka / config / zookeeper.Propriétés execstop = / usr / local / kafka / bin / zookeeper-server-stop.sh redémarrer = en borne [installation] WantedBy = Multi-utilisateur.cible
Enregistrez le fichier et fermez-le.
Ensuite, créez un fichier unitaire Systemd pour le service Kafka:
Sudo Nano / etc / Systemd / System / Kafka.service Ajouter le contenu ci-dessous. Assurez-vous de définir le bon Java_home chemin selon le java installé sur votre système.
[Unité] Description = Apache Kafka Server Documentation = http: // kafka.apache.org / documentation.html requiert = zookeeper.service [service] type = Simple Environment = "java_home = / usr / lib / jvm / java-11-openjdk-amd64" execstart = / usr / local / kafka / bin / kafka-server-start.sh / usr / local / kafka / config / serveur.Propriétés execstop = / usr / local / kafka / bin / kafka-server-stop.sh [installer] recherché = multi-utilisateurs.cible
Enregistrer le fichier et fermer.
Recharger le démon systemd pour appliquer de nouvelles modifications.
Sudo Systemctl Daemon-Reload Cela rechargera tous les fichiers systemd dans l'environnement système.
Étape 4 - Démarrez les services ZooKeeper et Kafka
Commençons les deux services un par un. Tout d'abord, vous devez démarrer le service ZooKeeper, puis démarrer Kafka. Utilisez la commande SystemCTL pour démarrer une instance de gardien de zoo à un nœud.
sudo systemctl start zookeepersudo systemctl start kafka
Vérifiez les deux services de l'état des services:
Sudo Systemctl Status ZookeeperSudo Systemctl Status Kafka
C'est ça. Vous avez réussi à installer le serveur Apache Kafka sur Ubuntu 22.04 Système. Ensuite, nous créerons des sujets sur le serveur Kafka.
Étape 5 - Créez un sujet à Kafka
Kafka fournit plusieurs scripts shell prédéfinis pour y travailler. Tout d'abord, créez un sujet nommé «TestTopic» avec une seule partition avec une seule réplique:
CD / USR / Local / Kafkabac / kafka-topics.sh --create --bootstrap-server localhost: 9092 - Réplication-facteur 1 - partitions 1 - Testtopic topic
Sortie créée de sujets testtopic.
Ici:
- Utiliser
--créerOption pour créer un nouveau sujet - Le
--facteur de réplicationDécrit combien de copies de données seront créées. Au fur et à mesure que nous fonctionnons avec une seule instance, gardez cette valeur 1. - Met le
--partitionsOptions en tant que nombre de courtiers que vous souhaitez que vos données soient divisées entre. Comme nous courons avec un seul courtier, gardez cette valeur 1. - Le
--sujetDéfinissez le nom du sujet
Vous pouvez créer plusieurs sujets en exécutant la même commande que ci-dessus. Après cela, vous pouvez voir les sujets créés sur Kafka par la commande en cours d'exécution ci-dessous:
bac / kafka-topics.sh - list --bootstrap-server localhost: 9092 La sortie ressemble à la capture d'écran ci-dessous:
 Énumérer les sujets de Kafka
Énumérer les sujets de KafkaAlternativement, au lieu de créer manuellement des sujets, vous pouvez également configurer vos courtiers pour créer automatiquement des sujets lorsqu'un sujet inexistant est publié pour.
Étape 6 - Envoyer et recevoir des messages à Kafka
Le «producteur» est le processus responsable de la mise en place de données dans notre Kafka. Le Kafka est livré avec un client en ligne de commande qui prendra les commentaires d'un fichier ou de l'entrée standard et l'envoie comme messages au cluster Kafka. Le Kafka par défaut envoie chaque ligne en tant que message séparé.
Exécutons le producteur, puis tapons quelques messages dans la console pour envoyer au serveur.
bac / kafka-console producteur.SH - Broker-list localhost: 9092 - Testtopic topic > Bienvenue à Kafka> Ceci est mon premier sujet> Vous pouvez quitter cette commande ou maintenir ce terminal en cours d'exécution pour des tests supplémentaires. Ouvrez maintenant un nouveau terminal au processus de consommation Kafka à l'étape suivante.
Kafka a également un consommateur de ligne de commande pour lire les données du cluster Kafka et afficher les messages en sortie standard.
bac / kafka-consoleur.SH --bootstrap-server localhost: 9092 - Testtopic topic --dro-beginning Bienvenue à Kafka C'est mon premier sujet Maintenant, si vous avez toujours dirigé le producteur de Kafka dans un autre terminal. Tapez simplement du texte sur ce terminal producteur. il sera immédiatement visible sur le terminal de consommation. Voir la capture d'écran ci-dessous du producteur et des consommateurs de Kafka en travaillant:
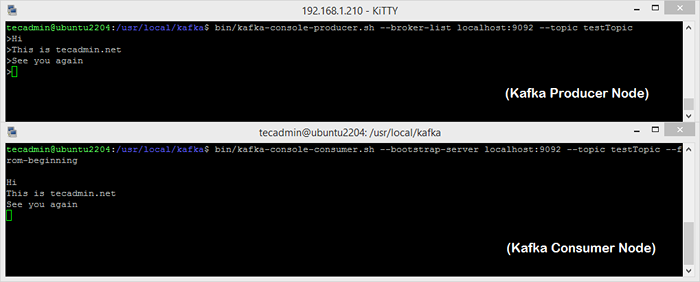 Exécution du producteur et du nœud de consommation Apache Kafka
Exécution du producteur et du nœud de consommation Apache KafkaConclusion
Ce tutoriel vous a aidé à installer et à configurer le serveur Apache Kafka sur un Ubuntu 22.04 Système Linux. De plus, vous avez appris à créer un nouveau sujet dans le serveur Kafka et à exécuter un exemple de production de production et de consommation avec Apache Kafka.
- « Comment créer une branche vide dans Git (sans parrent)
- Comment remplacer la chaîne en javascript »