

Comment installer Hadoop sur Ubuntu 18.04 Bionic Beaver Linux
- 3230
- 100
- Noa Faure
Apache Hadoop est un cadre open source utilisé pour le stockage distribué ainsi que le traitement distribué des mégadonnées sur des clusters d'ordinateurs qui s'exécutent sur des marchandises de marchandises. Hadoop stocke les données dans le système de fichiers distribué Hadoop (HDFS) et le traitement de ces données est effectué à l'aide de MapReduce. YARN fournit une API pour demander et allouer des ressources dans le cluster Hadoop.
Le cadre Apache Hadoop est composé des modules suivants:
- Hadoop commun
- Système de fichiers distribué Hadoop (HDFS)
- FIL
- Mapreduce
Cet article explique comment installer Hadoop Version 2 sur Ubuntu 18.04. Nous installerons HDFS (Namenode et Datanode), le fil, MapReduce sur le cluster de nœuds unique en mode pseudo distribué qui est distribué de simulation sur une seule machine. Chaque démon Hadoop tel que HDFS, fil, MapReduce, etc. fonctionnera comme un processus Java séparé / individuel.
Dans ce tutoriel, vous apprendrez:
- Comment ajouter des utilisateurs pour un environnement Hadoop
- Comment installer et configurer l'Oracle JDK
- Comment configurer SSH sans mot de passe
- Comment installer Hadoop et configurer les fichiers XML liés nécessaires
- Comment démarrer le cluster Hadoop
- Comment accéder à Namenode et à ResourceManager Web UI
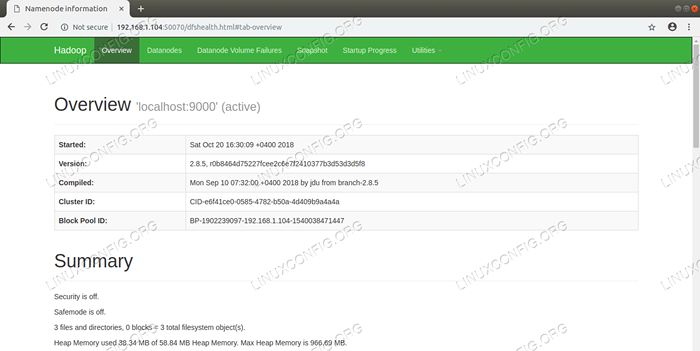
Interface utilisateur Web Nameode. Exigences et conventions logicielles utilisées
| Catégorie | Exigences, conventions ou version logicielle utilisée |
|---|---|
| Système | Ubuntu 18.04 |
| Logiciel | Hadoop 2.8.5, Oracle JDK 1.8 |
| Autre | Accès privilégié à votre système Linux en tant que racine ou via le Sudo commande. |
| Conventions | # - Exige que les commandes Linux soient exécutées avec des privilèges racine soit directement en tant qu'utilisateur racine, soit par l'utilisation de Sudo commande$ - Exige que les commandes Linux soient exécutées en tant qu'utilisateur non privilégié régulier |
Autres versions de ce tutoriel
Ubuntu 20.04 (Focal Fossa)
Ajouter des utilisateurs pour l'environnement Hadoop
Créez le nouvel utilisateur et le nouvel groupe à l'aide de la commande:
# Ajouter l'utilisateur
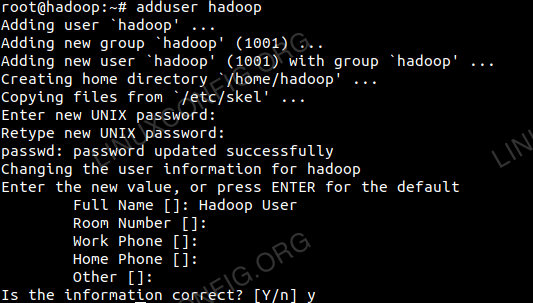 Ajouter un nouvel utilisateur pour Hadoop.
Ajouter un nouvel utilisateur pour Hadoop.
Installer et configurer l'Oracle JDK
Télécharger et extraire les archives Java sous le /opter annuaire.
# CD / OPT # TAR -XZVF JDK-8U192-LINUX-X64.le goudron.gz
ou
$ TAR -XZVF JDK-8U192-LINUX-X64.le goudron.gz -c / opt
Pour définir le JDK 1.8 MISE À JOUR 192 En tant que JVM par défaut, nous utiliserons les commandes suivantes:
# Mise à jour-alternatifs - install / usr / bin / java java / opt / jdk1.8.0_192 / bin / java 100 # mise à jour-alternatifs - install / usr / bin / javac javac / opt / jdk1.8.0_192 / bin / javac 100
Après l'installation pour vérifier que le java a été configuré avec succès, exécutez les commandes suivantes:
# Update-Alteratives - Display Java # Update-Alteratives - Display Javac
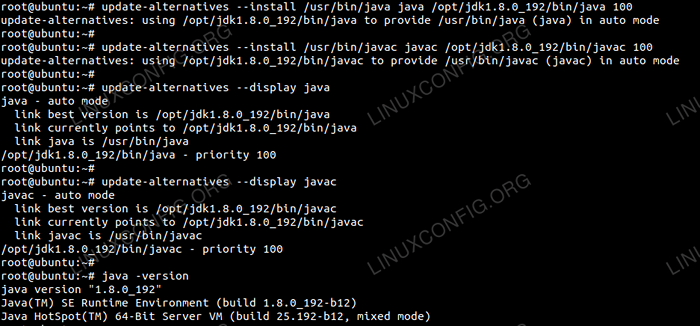 Installation et configuration d'OracleJDK.
Installation et configuration d'OracleJDK. Configurer SSH sans mot de passe
Installez le serveur SSH ouvert et ouvrez le client SSH avec la commande:
# sudo apt-get install openssh-server openssh-client
Générer des paires de clés publiques et privées avec la commande suivante. Le terminal incitera à saisir le nom du fichier. Presse ENTRER et procéder. Après cette copie, le formulaire de clés publics id_rsa.pub pour autorisé_keys.
$ ssh-keygen -t rsa $ cat ~ /.ssh / id_rsa.pub >> ~ /.SSH / AUTORISED_KEYS
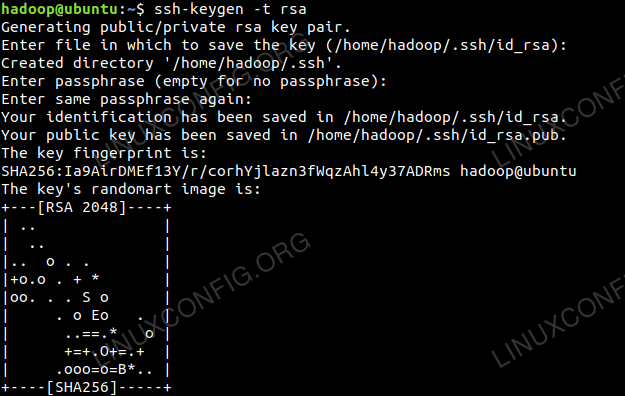 Configuration SSH sans mot de passe.
Configuration SSH sans mot de passe.
Vérifiez la configuration SSH sans mot de passe avec la commande:
$ ssh localhost
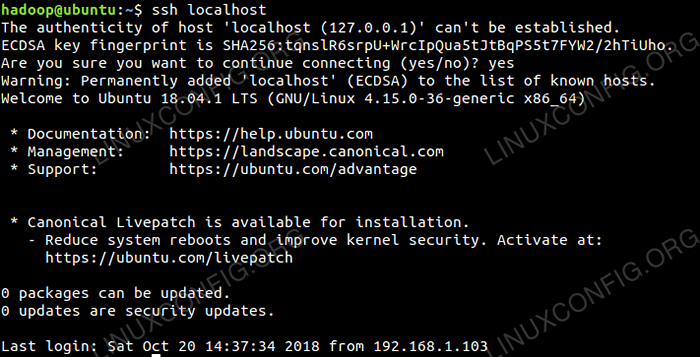 Vérification SSH sans mot de passe.
Vérification SSH sans mot de passe.
Installez Hadoop et configurez les fichiers XML connexes
Télécharger et extraire Hadoop 2.8.5 du site officiel Apache.
# TAR -XZVF HADOOP-2.8.5.le goudron.gz
Configuration des variables d'environnement
Modifier le bashrc Pour l'utilisateur Hadoop via la configuration des variables d'environnement Hadoop suivantes:
exporter hadoop_home = / home / hadoop / hadoop-2.8.5 export hadoop_install = $ hadoop_home export hadoop_mapred_home = $ hadoop_home export hadoop_common_home = $ hadoop_home export hadoop_hdfs_home = $ hadoop_home export yarn_home = $ hadoop_home export hadoop_common_lib_native exporter hadoop_opts = "- djava.bibliothèque.path = $ hadoop_home / lib / natif " Source le .bashrc Dans la session de connexion actuelle.
$ source ~ /.bashrc
Modifier le Hadoop-env.shot fichier qui est dans / etc / hadoop À l'intérieur du répertoire d'installation de Hadoop et effectuez les modifications suivantes et vérifiez si vous souhaitez modifier d'autres configurations.
exporter java_home = / opt / jdk1.8.0_192 export hadoop_conf_dir = $ hadoop_conf_dir: - "/ home / hadoop / hadoop-2.8.5 / etc / hadoop " 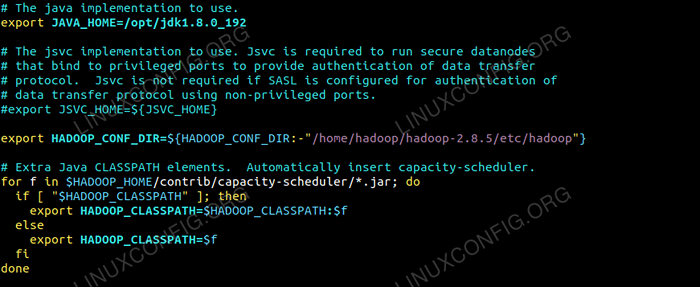 Changements dans Hadoop-env.fichier SH.
Changements dans Hadoop-env.fichier SH. Modifications de configuration dans le site core.fichier xml
Modifier le site de base.xml avec VIM ou vous pouvez utiliser l'un des éditeurs. Le fichier est sous / etc / hadoop à l'intérieur hadoop Répertoire d'accueil et ajouter les entrées suivantes.
FS.defaultfs hdfs: // localhost: 9000 hadoop.TMP.diron / home / hadoop / hadooptmpdata De plus, créez le répertoire sous hadoop dossier à domicile.
$ mkdir hadooptmpdata
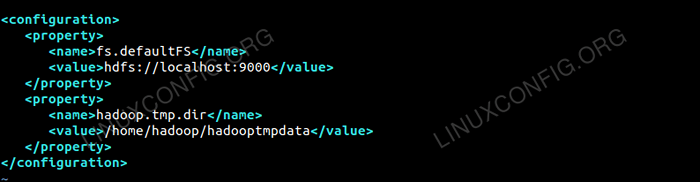 Configuration du site core.fichier xml.
Configuration du site core.fichier xml. Modifications de configuration dans le site HDFS.fichier xml
Modifier le site HDFS.xml qui est présent sous le même endroit que je.e / etc / hadoop à l'intérieur hadoop Répertoire d'installation et créez le Namenode / Datanode répertoires sous hadoop répertoire de la maison utilisateur.
$ mkdir -p hdfs / namenode $ mkdir -p hdfs / datanode
DFS.réplication 1 DFS.nom.diron fichier: /// home / hadoop / hdfs / namenode DFS.données.diron fichier: /// home / hadoop / hdfs / datanode 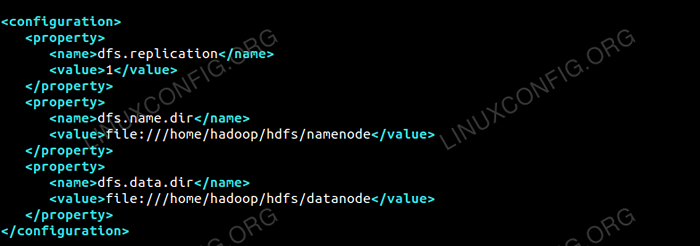 Configuration pour le site HDFS.fichier xml.
Configuration pour le site HDFS.fichier xml. Modifications de configuration dans le site mapred.fichier xml
Copier le site mapred.xml depuis site mapred.xml.modèle en utilisant CP commande puis modifier le site mapred.xml placé dans / etc / hadoop sous hadoop Répertoire d'instillation avec les modifications suivantes.
$ cp mapred site.xml.modèle de site mapred.xml
 Création du nouveau site Mapred.fichier xml.
Création du nouveau site Mapred.fichier xml. mapreduce.cadre.nom fil  Configuration du site mapred.fichier xml.
Configuration du site mapred.fichier xml. Modifications de configuration dans le site de fil.fichier xml
Modifier Site de fil.xml avec les entrées suivantes.
mapreduceyarn.nodemanager.services aux auxiliaires MapReduce_Shuffle  Configuration pour le site de fil.fichier xml.
Configuration pour le site de fil.fichier xml. Démarrer le cluster Hadoop
Formatez le namenode avant de l'utiliser pour la première fois. Au fur et à mesure que l'utilisateur HDFS exécute la commande ci-dessous pour formater le namenode.
$ hdfs namenode -format
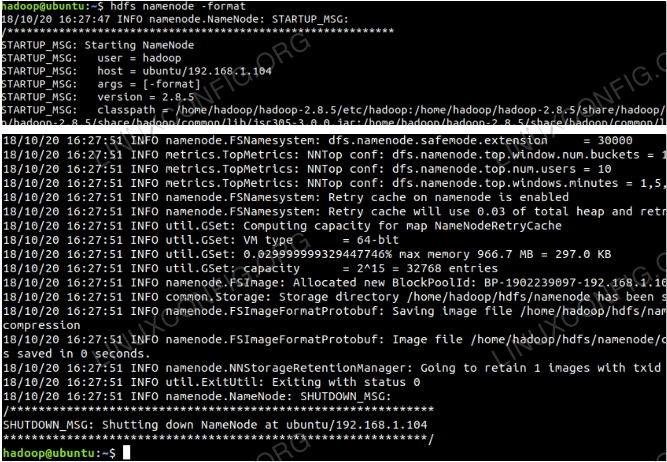 Formater le namenode.
Formater le namenode.
Une fois le namenode formaté, démarrez les HDF en utilisant le start-dfs.shot scénario.
 Démarrage du script de démarrage DFS pour démarrer HDFS.
Démarrage du script de démarrage DFS pour démarrer HDFS.
Pour démarrer les services de fil, vous avez besoin pour exécuter le script de démarrage du fil I.e. démarrage.shot
 Démarrage du script de démarrage du fil pour démarrer le fil.
Démarrage du script de démarrage du fil pour démarrer le fil. Pour vérifier que tous les services / daémons Hadoop sont lancés avec succès, vous pouvez utiliser le JPS commande.
/ opt / jdk1.8.0_192 / bin / JPS 20035 SecondaryNameNode 19782 Datanode 21671 JPS 20343 Nodemanager 19625 NameNode 20187 ResourceManager  Hadoop Daemons Sortie de la commande JPS.
Hadoop Daemons Sortie de la commande JPS.
Maintenant, nous pouvons vérifier la version Hadoop actuelle que vous pouvez utiliser ci-dessous la commande:
$ Hadoop Version
ou
Version HDFS $
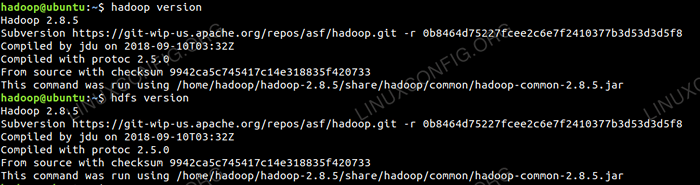 Vérifiez la version Hadoop.
Vérifiez la version Hadoop.
Interface de ligne de commande HDFS
Pour accéder au HDFS et créer des répertoires en haut de DFS, vous pouvez utiliser HDFS CLI.
$ hdfs dfs -mkdir / test $ hdfs dfs -mkdir / hadooponubuntu $ hdfs dfs -ls /
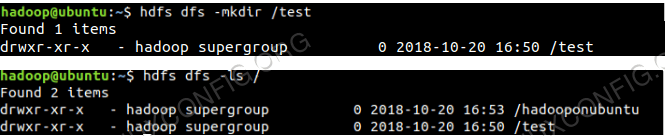 Création du répertoire HDFS utilisant HDFS CLI.
Création du répertoire HDFS utilisant HDFS CLI.
Accéder au Namenode et au fil du navigateur
Vous pouvez accéder à la fois sur l'interface utilisateur Web pour Namenode et le gestionnaire de ressources de Yarn via l'un des navigateurs comme Google Chrome / Mozilla Firefox.
Namenode Web UI - http: //: 50070
Interface utilisateur Web Nameode. 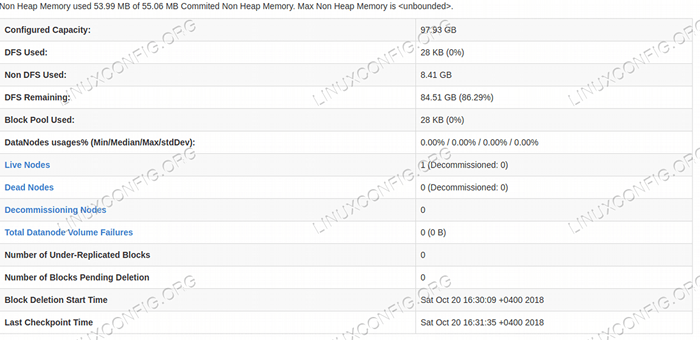 Détails HDFS de l'interface utilisateur Web Nameode.
Détails HDFS de l'interface utilisateur Web Nameode. 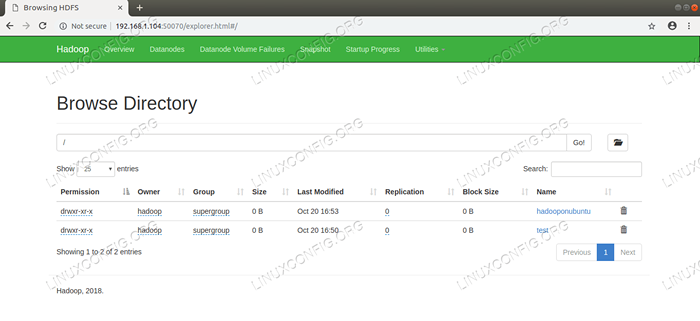 Répertoire HDFS naviguant via l'interface utilisateur Web Nameode.
Répertoire HDFS naviguant via l'interface utilisateur Web Nameode. L'interface Web de gestion des ressources de Yarn (RM) affichera tous les travaux en cours d'exécution sur le cluster Hadoop actuel.
Interface utilisateur du gestionnaire de ressources - http: //: 8088
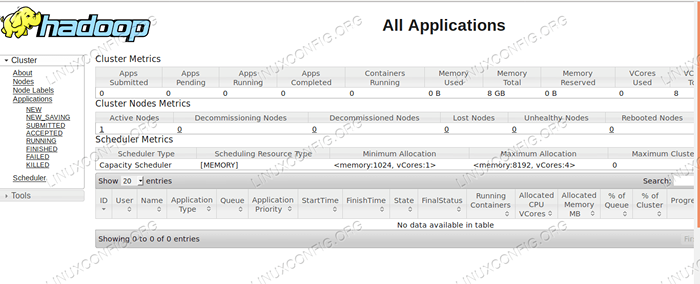 Interface utilisateur Web du gestionnaire de ressources.
Interface utilisateur Web du gestionnaire de ressources. Conclusion
Le monde change la façon dont il fonctionne actuellement et les grosses données jouent un rôle majeur dans cette phase. Hadoop est un cadre qui facilite notre LIF tout en travaillant sur de grands ensembles de données. Il y a des améliorations sur tous les fronts. L'avenir est excitant.
Tutoriels Linux connexes:
- Ubuntu 20.04 Hadoop
- Choses à installer sur Ubuntu 20.04
- Comment créer un cluster Kubernetes
- Comment installer Kubernetes sur Ubuntu 20.04 Focal Fossa Linux
- Choses à faire après l'installation d'Ubuntu 20.04 Focal Fossa Linux
- Comment installer Kubernetes sur Ubuntu 22.04 Jammy Jellyfish…
- Choses à installer sur Ubuntu 22.04
- Comment travailler avec l'API WooCommerce REST avec Python
- Comment gérer les grappes de Kubernetes avec Kubectl
- Une introduction à l'automatisation Linux, des outils et des techniques
- « Comment installer Android Studio sur Manjaro 18 Linux
- Comment installer Google Chrome sur Manjaro 18 Linux »