

Comment effectuer les demandes HTTP avec Python - Partie 1 La bibliothèque standard

- 5029
- 450
- Noa Faure
HTTP est le protocole utilisé par le World Wide Web, c'est pourquoi être capable d'interagir avec informatique est essentiel: gratter une page Web, communiquer avec un service API, ou même télécharger un fichier, sont toutes des tâches basées sur cette interaction. Python rend ces opérations très faciles: certaines fonctions utiles sont déjà fournies dans la bibliothèque standard, et pour des tâches plus complexes, il est possible (et même recommandé) d'utiliser demandes module. Dans ce premier article de la série, nous nous concentrerons sur les modules intégrés. Nous utiliserons Python3 et fonctionnerons principalement à l'intérieur du shell interactif Python: les bibliothèques nécessaires ne seront importées qu'une seule fois pour éviter les répétitions.
Dans ce tutoriel, vous apprendrez:
- Comment effectuer des demandes HTTP avec Python3 et l'urllib.demander une bibliothèque
- Comment travailler avec les réponses du serveur
- Comment télécharger un fichier à l'aide de l'URLOpen ou des fonctions UrlretReve
Demande http avec python - pt. I: La bibliothèque standard
Exigences et conventions logicielles utilisées
| Catégorie | Exigences, conventions ou version logicielle utilisée |
|---|---|
| Système | Indépendant du SO |
| Logiciel | Python3 |
| Autre |
|
| Conventions | # - Exige que les commandes Linux soient exécutées avec des privilèges racine soit directement en tant qu'utilisateur racine, soit par l'utilisation de Sudo commande$ - Exige que les commandes Linux soient exécutées en tant qu'utilisateur non privilégié régulier |
Effectuer des demandes avec la bibliothèque standard
Commençons par un très facile OBTENIR demande. Le verbe GET HTTP est utilisé pour récupérer des données à partir d'une ressource. Lors de l'exécution de ce type de demandes, il est possible de spécifier certains paramètres dans les variables de forme: ces variables, exprimées en paires de valeurs clés, forme un chaîne de requête qui est «annexé» au URL de la ressource. Une demande de GET doit toujours être idempotent (Cela signifie que le résultat de la demande doit être indépendant du nombre de fois où il est effectué) et ne doit jamais être utilisé pour changer un état. Effectuer des demandes de get avec Python est vraiment facile. Pour le bien de ce tutoriel, nous profiterons de l'appel de l'API de la NASA ouverte qui nous permettons de récupérer la soi-disant «photo du jour»:
>>> De Urllib.Demande d'import UrLopen >>> avec URLOpen ("https: // API.NASA.Gov / Planetary / Apod?api_key = demo_key ") comme réponse: ... réponse_content = réponse.lire() La première chose que nous avons faite a été d'importer le urlopen fonction du Urllib.demande bibliothèque: cette fonction renvoie un http.client.HttpResponse objet qui a des méthodes très utiles. Nous avons utilisé la fonction à l'intérieur d'un avec déclaration parce que le HttpResponse L'objet prend en charge le gestion du contexte Protocole: les ressources sont immédiatement fermées après l'exécution de l'instruction «avec», même si un exception est soulevé.
Le lire La méthode que nous avons utilisée dans l'exemple ci-dessus renvoie le corps de l'objet de réponse comme un octets et prend éventuellement un argument qui représente la quantité d'octets à lire (nous verrons plus tard comment cela est important dans certains cas, surtout lors du téléchargement de gros fichiers). Si cet argument est omis, le corps de la réponse est lu dans son intégralité.
À ce stade, nous avons le corps de la réponse en tant que objet octets, référencé par le Response_content variable. Nous voulons peut-être le transformer en autre chose. Pour le transformer en une chaîne, par exemple, nous utilisons le décoder Méthode, fournissant le type de codage comme argument, généralement:
>>> Response_content.Decode ('UTF-8') Dans l'exemple ci-dessus, nous avons utilisé le UTF-8 codage. L'appel de l'API que nous avons utilisé dans l'exemple, cependant, renvoie une réponse dans Json Format, par conséquent, nous voulons le traiter à l'aide du json module:
>>> Importer Json JSON_Response = JSON.charges (réponse_content) Le json.charges la méthode désérialise un chaîne, un octets ou un bytearray instance contenant un document JSON dans un objet Python. Le résultat de l'appel de la fonction, dans ce cas, est un dictionnaire:
>>> Deprint Import pprint >>> pprint (json_response) 'date': '2019-04-14', 'Explication': `` Asseyez-vous et regardez deux trous noirs fusionner. Inspiré par la «première détection directe des ondes gravitationnelles en 2015, cette« vidéo de simulation se joue au ralenti, mais prendrait environ un tiers d'une seconde si vous exécutez en temps réel. Situé sur une scène cosmique, les trous noirs sont posés devant les étoiles, le gaz et la poussière ''. Leurs gravité extrêmes lentent la lumière derrière eux '' dans les anneaux d'Einstein alors qu'ils se rapprochent et fusionnent finalement '' en un. Les ondes gravitationnelles par ailleurs invisibles '' générées comme les objets massifs fusionnent rapidement, ce que l'image visible se répercute et se glisse à l'intérieur et à l'extérieur des anneaux d'Einstein même après que les trous noirs aient fusionné. Surnommée '' GW150914, les ondes gravitationnelles détectées par LIGO sont '' cohérente avec la fusion de 36 et 31 trous de masse solaire '' à une distance de 1.3 milliards d'années-lumière. La finale, '' un trou noir unique a 63 fois la masse du soleil, avec les 3 masses solaires restantes converties en énergie dans les ondes gravitationnelles. Depuis lors.',' media_type ':' video ',' service_version ':' v1 ',' title ':' simulation: deux trous noirs fusionnent ',' url ':' https: // www.Youtube.com / embed / i_88s8dwbcu?rel = 0 ' Comme alternative, nous pourrions également utiliser le json_load Fonction (remarquez le «S» de suivi manquant). La fonction accepte un en forme de fichier Objet comme argument: cela signifie que nous pouvons l'utiliser directement sur le HttpResponse objet:
>>> avec Urlopen ("https: // api.NASA.Gov / Planetary / Apod?api_key = demo_key ") comme réponse: ... JSON_RESPONNE = JSON.Charge (réponse) Lire les en-têtes de réponse
Une autre méthode très utile utilisable sur le HttpResponse L'objet est getheaders. Cette méthode renvoie le têtes de la réponse comme un tableau de tuples. Chaque tuple contient un paramètre d'en-tête et sa valeur correspondante:
>>> pprint (réponse.getheaders ()) [('serveur', 'openresty'), ('date', 'Sun, 14 avril 2019 10:08:48 GMT'), ('Content-Type', 'Application / JSON'), ( «Content-Length», «1370»), («Connexion», «Close»), («Vary», «Accept-Encoding»), («X-Ratelimit-Limit», «40»), («x -RATELIMIT-REMINGING ',' 37 '), (' via ',' 1.1 vegur, http / 1.1 api-ubrella (apachetrafficServer [cmssf]) '), (' age ',' 1 '), (' x-cache ',' miss '), (' access-control-allow-origin ',' * ') , («Strict-Transport-Security», «Max-Age = 31536000; Preload»)] Vous pouvez remarquer, parmi les autres, le Type de contenu Le paramètre, qui, comme nous l'avons dit ci-dessus, est Application / JSON. Si nous voulons récupérer uniquement un paramètre spécifique, nous pouvons utiliser le getheader Méthode à la place, passer le nom du paramètre comme argument:
>>> Réponse.Getheader ('Content-Type') 'Application / JSON' Obtenir l'état de la réponse
Obtenir le code d'état et Raison de la phrase Retourné par le serveur après une demande HTTP est également très facile: tout ce que nous avons à faire est d'accéder au statut et raison propriétés du HttpResponse objet:
>>> Réponse.Statut 200 >>> Réponse.raison 'ok' Y compris les variables dans la demande de GET
L'URL de la demande que nous avons envoyée ci-dessus ne contenait qu'une seule variable: clé API, Et sa valeur était "Demo_key". Si nous voulons passer plusieurs variables, au lieu de les attacher manuellement à l'URL, nous pouvons les fournir ainsi que leurs valeurs associées comme paires de valeurs clés d'un dictionnaire Python (ou comme séquence de tuples à deux éléments); Ce dictionnaire sera transmis au Urllib.analyse.urlencode Méthode, qui construira et renverra le chaîne de requête. L'appel de l'API que nous avons utilisé ci-dessus, nous permettez de spécifier une variable «Date» facultative, pour récupérer l'image associée à une journée spécifique. Voici comment nous pourrions continuer:
>>> De Urllib.analyse d'importation urlencode >>> query_params = ..."api_key": "Demo_key", ..."Date": "2019-04-11" >>> query_string = urlencode (query_params) >>> query_string 'api_key = demo_key & date = 2019-04-11' Nous avons d'abord défini chaque variable et sa valeur correspondante comme des paires de valeurs clés d'un dictionnaire, que nous avons adopté ledit dictionnaire comme argument à la urlencode fonction, qui a renvoyé une chaîne de requête formatée. Maintenant, lors de l'envoi de la demande, tout ce que nous avons à faire est de le joindre à l'URL:
>>> url = "?".join (["https: // api.NASA.Gov / Planetary / apod ", query_string])
Si nous envoyons la demande en utilisant l'URL ci-dessus, nous obtenons une réponse différente et une image différente:
'Date': '2019-04-11', 'Explication': `` À quoi ressemble un trou noir? Pour le découvrir, la radio "télescopes de autour de la Terre a coordonné les observations de" trous noirs avec les plus grands horizons d'événements connus sur le "ciel. Seul, les trous noirs sont juste noirs, mais ces attracteurs monstres "sont connus pour être entourés de gaz brillant. La "première image a été publiée hier et a résolu la zone" autour du trou noir au centre du Galaxy M87 sur une échelle "ci-dessous celle attendue pour son horizon d'événement. Sur la photo, la "région centrale sombre n'est pas l'horizon de l'événement, mais plutôt l'ombre du" "trou noir - la région centrale de l'émission de gaz" "assombrie par la gravité du trou noir central. La taille et la forme «» de l'ombre sont déterminées par un gaz brillant près de «l'horizon de l'événement, par de fortes déviations de lentilles gravitationnelles» et par le rotation du trou noir. En résolvant "l'ombre, l'ombre, le télescope d'événement (EHT), les preuves ont renforcé" que la gravité d'Einstein fonctionne même dans des régions extrêmes, et "'a donné une preuve claire que M87 a un trou noir de rotation central d'environ 6 milliards de masses solaires. L'EHT n'est pas fait - "Les observations futures seront orientées vers une résolution encore plus élevée", un meilleur suivi de la variabilité et l'exploration du "voisinage immédiat du trou noir au centre de notre" Galaxie de la Voie lactée.',' hdurl ':' https: // apod.NASA.Gov / apod / Image / 1904 / M87BH_EHT_2629.jpg ',' media_type ':' image ',' service_version ':' v1 ',' title ':' première image à l'échelle de l'horizon d'un trou noir ',' url ':' https: // apod.NASA.Gov / apod / image / 1904 / m87bh_eht_960.jpg '
Dans le cas où vous ne l'avez pas remarqué, l'URL de l'image retournée pointe vers la première photo récemment dévoilée d'un trou noir:
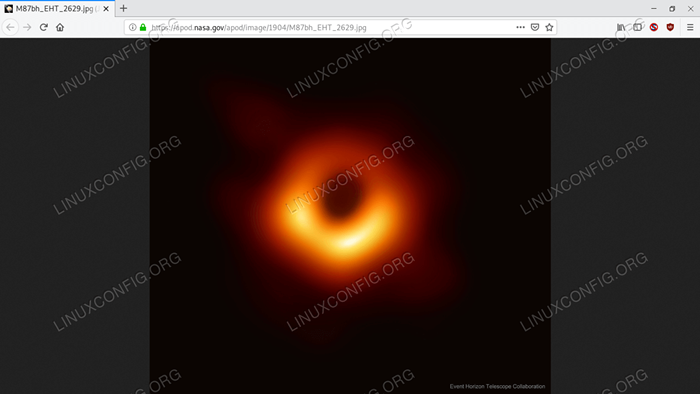
L'image renvoyée par l'appel de l'API - la première image d'un trou noir
Envoi d'une demande de poste
L'envoi d'une demande de poste, avec des variables `` contenu '' dans le corps de la demande, en utilisant la bibliothèque standard, nécessite des étapes supplémentaires. Tout d'abord, comme nous l'avons fait auparavant, nous construisons les données post-forme sous la forme d'un dictionnaire:
>>> data = ... "variable1": "value1", ... "variable2": "value2" ... Après avoir construit notre dictionnaire, nous voulons utiliser le urlencode fonction comme nous l'avons fait auparavant, et en outre en outre la chaîne résultante ascii:
>>> post_data = urlencode (data).Encoder ('ASCII') Enfin, nous pouvons envoyer notre demande, passant les données comme deuxième argument du urlopen fonction. Dans ce cas, nous utiliserons https: // httpbin.Org / Post comme URL de destination (httpbin.L'organisation est un service de demande et de réponse):
>>> avec Urlopen ("https: // httpbin.org / post ", post_data) comme réponse: ... JSON_RESPONNE = JSON.Load (réponse) >>> pprint (json_response) 'args': , 'data': ", 'files': , 'form': 'variable1': 'value1', 'variable2': ' Value2 ',' Headers ': ' Accepter-Encoding ':' Identity ',' Content-Length ':' 33 ',' Content-Type ':' Application / X-www-Form-Urlencoded ',' Host ' : 'httpbin.org ',' user-agent ':' python-urllib / 3.7 ',' JSON ': Aucun,' Origin ':' xx.xx.xx.xx, xx.xx.xx.xx ',' url ':' https: // httpbin.org / post ' La demande a été réussie et le serveur a renvoyé une réponse JSON qui comprend des informations sur la demande que nous avons faite. Comme vous pouvez le voir, les variables que nous avons transmises dans le corps de la demande sont signalées comme la valeur du 'former' clé dans le corps de réponse. Lire la valeur du têtes clé, nous pouvons également voir que le type de contenu de la demande était application / x-www-forme-urlencod Et l'agent utilisateur 'Python-Urllib / 3.7'.
Envoi des données JSON dans la demande
Et si nous voulons envoyer une représentation JSON des données avec notre demande? Nous définissons d'abord la structure des données que nous la convertissons en JSON:
>>> personne = ... "Firstname": "Luke", ... "LastName": "Skywalker", ... "Titre": "Jedi Knight" ... Nous voulons également utiliser un dictionnaire pour définir des en-têtes personnalisés. Dans ce cas, par exemple, nous voulons spécifier que notre contenu de demande est Application / JSON:
>>> CUSTOM_HEADERS = ... "Contenu-type": "application / json" ... Enfin, au lieu d'envoyer directement la demande, nous créons un Demande Objet et nous passons, dans l'ordre: URL de destination, les données de demande et les en-têtes de demande comme arguments de son constructeur:
>>> De Urllib.demande de demande d'importation >>> req = request ( ... "https: // httpbin.org / post ", ... json.décharges (personne).Encoder ('ASCII'), ... Custom_headers ...) Une chose importante à remarquer est que nous avons utilisé le json.décharge fonction passant le dictionnaire contenant les données que nous voulons être incluses dans la demande comme argument: cette fonction est utilisée pour sérialiser un objet dans une chaîne formatée JSON, que nous avons encodée en utilisant le encoder méthode.
À ce stade, nous pouvons envoyer notre Demande, le passer comme le premier argument du urlopen fonction:
>>> avec Urlopen (req) comme réponse: ... JSON_RESPONNE = JSON.Charge (réponse) Vérifions le contenu de la réponse:
'args': , 'data': '"FirstName": "Luke", "LastName": "Skywalker", "Title": "Jedi" Knight "', 'Files': , ' Form ': ,' Headers ': ' Accepter-Encoding ':' Identity ',' Content-Length ':' 70 ',' Content-Type ':' Application / Json ',' Host ':' httpbin.org ',' user-agent ':' python-urllib / 3.7 ',' JSON ': ' FirstName ':' Luke ',' LastName ':' Skywalker ',' Title ':' Jedi Knight ',' Origin ':' xx.xx.xx.xx, xx.xx.xx.xx ',' url ':' https: // httpbin.org / post ' Cette fois, nous pouvons voir que le dictionnaire associé à la clé «Form» dans le corps de réponse est vide, et celui associé à la clé «JSON» représente les données que nous avons envoyées en tant que JSON. Comme vous pouvez l'observer, même le paramètre d'en-tête personnalisé que nous avons envoyé a été reçu correctement.
Envoi d'une demande avec un verbe HTTP autre que Get ou Publier
Lorsque vous interagissez avec les API, nous devrons peut-être utiliser Verbes http Autre que simplement obtenir ou publier. Pour accomplir cette tâche, nous devons utiliser le dernier paramètre du Demande Constructeur de classe et spécifiez le verbe que nous voulons utiliser. Le verbe par défaut est obtenu si le données Le paramètre est Aucun, Sinon, la publication est utilisée. Supposons que nous voulons envoyer un METTRE demande:
>>> req = request ( ... "https: // httpbin.org / put ", ... json.décharges (personne).Encoder ('ASCII'), ... Custom_headers, ... méthode = 'put' ...) Télécharger un fichier
Une autre opération très courante que nous voulons peut-être effectuer est de télécharger une sorte de fichier à partir du Web. En utilisant la bibliothèque standard, il existe deux façons de le faire: en utilisant le urlopen fonction, lire la réponse en morceaux (surtout si le fichier à télécharger est grand) et les écrire dans un fichier local «manuellement» ou utiliser le urlretrie La fonction, qui, comme indiqué dans la documentation officielle, est considérée. Voyons un exemple des deux stratégies.
Téléchargement d'un fichier à l'aide d'UrLopen
Disons que nous voulons télécharger le tarball contenant la dernière version du code source du noyau Linux. En utilisant la première méthode que nous avons mentionnée ci-dessus, nous écrivons:
>>> DERNITE_KERNEL_TARBALL = "https: // cdn.noyau.org / pub / linux / noyau / v5.x / linux-5.0.7.le goudron.XZ ">>> avec UrLopen (Dermter_Kernel_Tarball) comme réponse: ... avec Open ('Dernier-Kernel.le goudron.xz ',' wb ') comme tarball: ... Bien que vrai: ... Chunk = réponse.lire (16384) ... Si Chunk: ... tarball.écrire (morceau) ... autre: ... casser Dans l'exemple ci-dessus, nous avons d'abord utilisé les deux urlopen fonction et le ouvrir Un à l'intérieur avec des déclarations et donc à l'aide du protocole de gestion de contexte pour s'assurer que les ressources sont nettoyées immédiatement après le bloc de code où elles sont utilisées est exécutée. À l'intérieur d'un alors que boucle, à chaque itération, le tronçon Références variables Les octets lus à partir de la réponse, (16384 dans ce cas - 16 kibytes). Si tronçon n'est pas vide, nous écrivons le contenu de l'objet de fichier («Tarball»); S'il est vide, cela signifie que nous avons consommé tout le contenu de l'organisme de réponse, donc nous cassons la boucle.
Une solution plus concise implique l'utilisation du fermer bibliothèque et le copyfileobj Fonction, qui copie les données d'un objet de type fichier (dans ce cas «réponse») à un autre objet de type fichier (dans ce cas, «Tarball»). La taille du tampon peut être spécifiée en utilisant le troisième argument de la fonction, qui, par défaut, est défini sur 16384 octets):
>>> Importer la fermeture ... avec Urlopen (dernier_kernel_tarball) comme réponse: ... avec Open ('Dernier-Kernel.le goudron.xz ',' wb ') comme tarball: ... fermer.copyfileobj (réponse, tarball) Téléchargement d'un fichier à l'aide de la fonction UrlretReve
La méthode alternative et encore plus concise pour télécharger un fichier à l'aide de la bibliothèque standard est par l'utilisation du Urllib.demande.urlretrie fonction. La fonction prend quatre arguments, mais seuls les deux premiers nous intéressent maintenant: le premier est obligatoire et est l'URL de la ressource à télécharger; Le second est le nom utilisé pour stocker la ressource localement. S'il n'est pas donné, la ressource sera stockée en tant que fichier temporaire dans / tmp. Le code devient:
>>> De Urllib.Demande d'importation urlretReve >>> urlretRevey ("https: // cdn.noyau.org / pub / linux / noyau / v5.x / linux-5.0.7.le goudron.XZ ") ('Dernier-nier.le goudron.xz ', ) Très simple, n'est-ce pas? La fonction renvoie un tuple qui contient le nom utilisé pour stocker le fichier (ceci est utile lorsque la ressource est stockée sous forme de fichier temporaire, et le nom est généré aléatoire), et le Httpmessage objet qui contient les en-têtes de la réponse HTTP.
Conclusions
Dans cette première partie de la série d'articles dédiés aux demandes de Python et HTTP, nous avons vu comment envoyer différents types de demandes en utilisant uniquement des fonctions de bibliothèque standard et comment travailler avec les réponses. Si vous avez un doute ou si vous souhaitez explorer les choses plus en profondeur, veuillez consulter l'uRllib officiel.Demande de documentation. La prochaine partie de la série se concentrera sur la bibliothèque de demande Python HTTP.
Tutoriels Linux connexes:
- Une introduction à l'automatisation Linux, des outils et des techniques
- Masterring Bash Script Loops
- Boucles imbriquées dans les scripts bash
- Mint 20: Mieux que Ubuntu et Microsoft Windows?
- Choses à installer sur Ubuntu 20.04
- Comment travailler avec l'API WooCommerce REST avec Python
- Comment lancer des processus externes avec Python et le…
- Gestion de la saisie des utilisateurs dans les scripts bash
- Comment charger, décharger et lister les modules de noyau Linux
- Système linux hung? Comment s'échapper vers la ligne de commande et…
- « Introduction aux jointures de base de données avec MariaDB et MySQL Join Exemples
- Comment effectuer les demandes HTTP avec Python - Partie 2 - La bibliothèque des demandes »