

Comment persister les données à PostgreSQL à Java
- 4758
- 1164
- Lucas Bernard
Java est peut-être le langage de programmation le plus utilisé de nos jours. Sa robustesse et sa nature indépendante de la plate-forme permettent aux applications basées sur Java de fonctionner principalement sur n'importe quoi. Comme c'est le cas avec n'importe quelle application, nous devons stocker nos données d'une manière fiable - ce besoin appelé Bases de données dans la vie.
Dans les connexions de la base de données Java, les connexions sont implémentées par JDBC (API de connectivité de la base de données Java), qui permet de gérer différents types de bases de données de la même manière, ce qui facilite notre vie lorsque nous devons enregistrer ou lire des données d'une base de données.
Dans ce didacticiel, nous créerons un exemple d'application Java qui pourra nous connecter à une instance de base de données PostgreSQL et y écrire des données. Pour vérifier que notre insertion de données est réussie, nous implémenterons également la lecture et l'imprimer le tableau dans lequel nous avons inséré des données.
Dans ce tutoriel, vous apprendrez:
- Comment configurer la base de données de l'application
- Comment importer le pilote PostgreSQL JDBC dans votre projet
- Comment insérer des données dans la base de données
- Comment exécuter une question simple pour lire le contenu d'une table de base de données
- Comment imprimer des données récupérées
Résultats de l'exécution de l'application. Exigences et conventions logicielles utilisées
| Catégorie | Exigences, conventions ou version logicielle utilisée |
|---|---|
| Système | Ubuntu 20.04 |
| Logiciel | Netbeans ide 8.2, postgresql 10.12, JDK 1.8 |
| Autre | Accès privilégié à votre système Linux en tant que racine ou via le Sudo commande. |
| Conventions | # - Exige que les commandes Linux soient exécutées avec des privilèges racine soit directement en tant qu'utilisateur racine, soit par l'utilisation de Sudo commande$ - Exige que les commandes Linux soient exécutées en tant qu'utilisateur non privilégié régulier |
La mise en place
Aux fins de ce tutoriel, nous n'avons besoin que d'une seule station de travail (bureau ou ordinateur portable) pour installer tous les composants nécessaires. Nous ne couvrirons pas l'installation de JDK, de l'IDE NetBeans ou de l'installation de la base de données PostgreSQL sur la machine de laboratoire. Nous supposons que la base de données appelée exampileb est opérationnel, et nous pouvons connecter, lire et écrire à l'aide de l'authentification du mot de passe, avec les informations d'identification suivantes:
| Nom d'utilisateur: | exempleUser |
| Mot de passe: | Exemple Pass |
Ceci est un exemple de configuration, utilisez des mots de passe forts dans un scénario du monde réel! La base de données est définie pour écouter sur LocalHost, qui sera nécessaire lorsque nous construisons le JDBC URL de connexion.
Le but principal de notre application est de montrer comment écrire et lire à partir de la base de données, donc pour les informations précieuses que nous sommes si désireux de persister, nous allons simplement choisir un nombre aléatoire entre 1 et 1000, et stockerons ces informations avec une seule fois ID du calcul et l'heure exacte des données enregistrées dans la base de données.
L'ID et le temps d'enregistrement seront fournis par la base de données, qui permet de travailler sur le problème réel (en fournissant un nombre aléatoire dans ce cas). C'est exprès, et nous couvrirons les possibilités de cette architecture à la fin de ce tutoriel.
Configuration de la base de données de l'application
Nous avons un service de base de données en cours d'exécution et une base de données appelée exampileb Nous avons le droit de travailler avec les informations d'identification mentionnées ci-dessus. Pour avoir un endroit où nous pouvons stocker nos précieuses données (aléatoires), nous devons créer une table, ainsi qu'une séquence qui fournira des identificateurs uniques de manière pratique. Considérez le script SQL suivant:
Créer une séquence Resultid_Seq Démarrer avec 0 incrément de 1 no maxvalue minvalue 0 cache 1; ALLER SECENCE RETULTID_SEQ Propriétaire à ExempleUser; Créer la table calc_Results (résistance numérique RÉSIMIQUE Par défaut NextVal ('resultID_SEQ' :: RegClass), result_of_calculation numérique pas null, enregistre_date timestamp default ()); ALTER TABLE CALC_RESULTS propriétaire à ExempleUser; Ces instructions devraient parler d'eux-mêmes. Nous créons une séquence, définissons le propriétaire sur exempleUser, Créer une table appelée calc_ (défendre les «résultats de calcul»), définir résidence être rempli automatiquement de la valeur suivante de notre séquence sur chaque insert et définir result_of_calculation et disque_date colonnes qui stockeront nos données. Enfin, le propriétaire de la table est également réglé sur exempleUser.
Pour créer ces objets de base de données, nous passons à postgres utilisateur:
$ sudo su - Postgres
Et exécuter le script (stocké dans un fichier texte appelé table_for_java.SQL) contre la exampileb base de données:
$ psql -d ExampledB < table_for_java.sql CREATE SEQUENCE ALTER SEQUENCE CREATE TABLE ALTER TABLE
Avec cela, notre base de données est prête.
Importation du pilote PostgreSQL JDBC dans le projet
Pour construire la demande, nous utiliserons NetBeans IDE 8.2. Les premières étapes sont le travail manuel. Nous choisissons le menu des fichiers, créons un nouveau projet. Nous laisserons les valeurs par défaut sur la page suivante de l'assistant, avec la catégorie «Java» et le projet sur «Application Java». Nous appuyerons ensuite. Nous donnons un nom à l'application (et définissons éventuellement un emplacement non défaut). Dans notre cas, il sera appelé Persisttopostgres. Cela fera que l'IDE créera un projet Java de base pour nous.
Dans le volet Projects, nous cliquons avec le bouton droit sur les «bibliothèques» et sélectionnons «Ajouter la bibliothèque…». Une nouvelle fenêtre s'affichera, où nous recherchons et sélectionnons le pilote PostgreSQL JDBC, et l'ajoutons en bibliothèque.
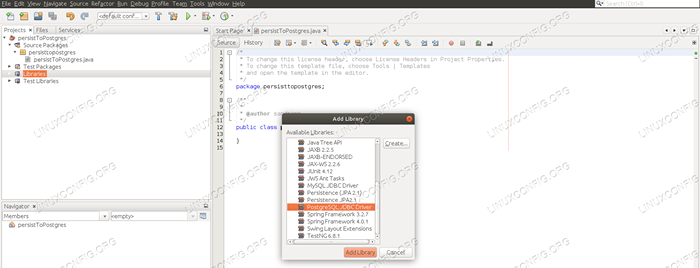 Ajout du pilote PostgreSQL JDBC au projet.
Ajout du pilote PostgreSQL JDBC au projet. Comprendre le code source
Nous ajoutons maintenant le code source suivant à la classe principale de notre application, Persisttopostgres:
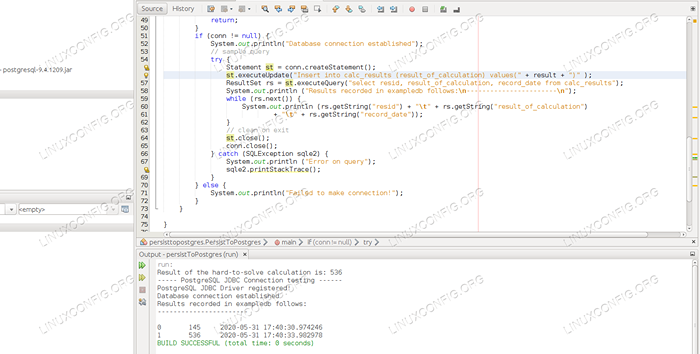
package persisttoposttres; Importer Java.SQL.Connexion; Importer Java.SQL.Drivermanager; Importer Java.SQL.ResultSet; Importer Java.SQL.Sqlexception; Importer Java.SQL.Déclaration; Importer Java.user.concurrent.ThreadLocalrandom; classe publique persisttoPostgre public static void main (String [] args) int result = threadLocalrandom.actuel().NextInt (1, 1000 + 1); Système.dehors.println ("Le résultat du calcul difficile à résoudre est:" + résultat); Système.dehors.println ("----- PostgreSQL JDBC Connection Testing ------"); essayez classe.Forname ("org.postgresql.Pilote "); catch (classNotFoundException cnfe) système.dehors.println ("Pas de pilote PostgreSQL JDBC dans le chemin de la bibliothèque!"); cnfe.printStackTrace (); retour; Système.dehors.println ("PostgreSQL JDBC Driver enregistré!"); Connexion conn = null; essayez conn = driverManager.getConnection ("jdbc: postgresql: // localhost: 5432 / exampledb", "exampleUser", "examplePass"); catch (sqlexception sqle) système.dehors.println ("La connexion a échoué! Vérifier la console de sortie "); sqle.printStackTrace (); retour; if (conn != null) système.dehors.println ("Connexion de base de données établie"); // Building Query Try Statement St = Conn.CreateStatement (); St.ExecuteUpDate ("INSERT IN CALC_RESULTS (result_of_calculation) (" + result + ")"); ResultSet RS = ST.ExecUteQuery ("SELECT RESSION, result_of_calculation, enregistre_date from calc_results"); Système.dehors.println ("Résultats enregistrés dans ExampledB suit: \ n ----------------------- \ n"); tandis que (Rs.suivant ()) système.dehors.println (RS.getString ("réside") + "\ t" + rs.getString ("result_of_calcul") + "\ t" + rs.getString ("disques_date")); // Nettoyer à la sortie st.fermer(); Connecticut.fermer(); catch (sqlexception sqle2) système.dehors.println ("erreur sur la requête"); sqle2.printStackTrace (); else système.dehors.println ("Échec de la connexion!"); - À la ligne 12, nous calculons un nombre aléatoire et le stockons dans le
résultatvariable. Ce nombre représente le résultat d'un calcul lourd qui
Nous devons stocker dans la base de données. - À la ligne 15, nous essayons d'enregistrer le pilote PostgreSQL JDBC. Cela entraînera une erreur si l'application ne trouve pas le pilote à l'exécution.
- À la ligne 26, nous construisons la chaîne de connexion JDBC à l'aide du nom d'hôte sur lequel la base de données fonctionne (localHost), le port à l'écoute de la base de données sur (5432, le port par défaut pour PostgreSQL), le nom de la base de données (ExampledB) et les informations d'identification mentionnées au niveau de la début.
- À la ligne 37, nous exécutons le
insérer dansInstruction SQL qui insère la valeur durésultatvariable dans leresult_of_calculationcolonne ducalc_tableau. Nous spécifions uniquement la valeur de ces colonnes uniques, donc les défauts s'appliquent:résidenceest récupéré à partir de la séquence nous
régler, etdisque_datepar défautmaintenant(), qui est l'heure de la base de données au moment de la transaction. - À la ligne 38, nous construisons une requête qui renverra toutes les données contenues dans le tableau, y compris notre insert à l'étape précédente.
- Depuis la ligne 39, nous présentons les données récupérées en les imprimant de manière semblable à une table, à la libération de ressources et à la sortie.
Exécution de l'application
Nous pouvons maintenant nettoyer, construire et exécuter le Persisttopostgres application, à partir de l'IDE lui-même, ou de la ligne de commande. Pour courir à partir de l'IDE, nous pouvons utiliser le bouton «Run Project» en haut. Pour l'exécuter à partir de la ligne de commande, nous devons naviguer vers le distr répertoire du projet et invoque le JVM avec le POT Package comme argument:
$ java -jar persisttopostgres.Le résultat du pot du calcul difficile à résoudre est: 173 ----- Test de connexion PostgreSQL JDBC ------ Connexion de données Résultats établis enregistrés dans ExampledB Suivre: ------------- ---------- 0 145 2020-05-31 17:40:30.974246
Les exécutions de ligne de commande fourniront la même sortie que la console IDE, mais ce qui est plus important ici, c'est que chaque exécution (que ce soit à partir de l'IDE ou de la ligne de commande) insérera une autre ligne dans notre table de base de données avec le numéro aléatoire donné calculé à chaque courir.
C'est pourquoi nous verrons également un nombre croissant d'enregistrements dans la sortie de l'application: chaque exécution augmente le tableau avec une ligne. Après quelques courses, nous verrons une longue liste de lignes de résultats dans le tableau.
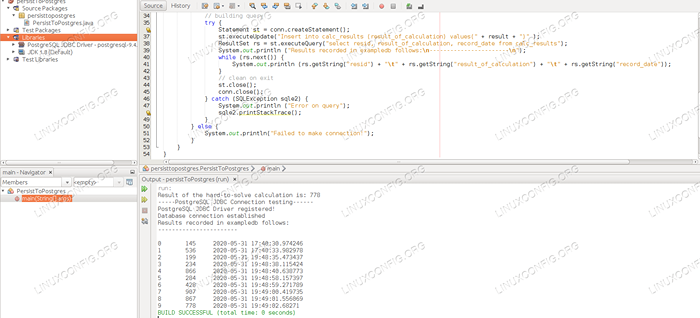 La sortie de la base de données montre les résultats de chaque exécution de l'application.
La sortie de la base de données montre les résultats de chaque exécution de l'application. Conclusion
Bien que cette application simple n'ait guère d'utilisation du monde réel, il est parfait pour démontrer certains aspects réels. Dans ce tutoriel, nous avons dit que nous faisons un calcul important avec l'application et avons inséré un nombre aléatoire à chaque fois, car le but de ce tutoriel est de montrer comment persister les données. Cet objectif que nous avons atteint: à chaque exécution, l'application sort et les résultats des calculs internes seraient perdus, mais la base de données préserve les données.
Nous avons exécuté l'application à partir d'un seul poste de travail, mais si nous devons vraiment résoudre un calcul compliqué, nous n'aurions qu'à modifier l'URL de connexion de la base de données pour pointer vers une machine distante exécutant la base de données, et nous pourrions commencer le calcul sur plusieurs ordinateurs En même temps, créer des centaines ou des milliers de cas de cette application, peut-être résoudre de petites pièces d'un plus grand puzzle et stocker les résultats de manière persistante, ce qui nous permet de faire évoluer notre puissance de calcul avec quelques lignes de code, et un peu de planification.
Pourquoi une planification est nécessaire? Pour rester avec cet exemple: si nous ne quittons pas d'identification de lignes ou de horodatage à la base de données, notre application aurait été beaucoup plus grande, beaucoup plus lente et beaucoup plus pleine de bugs - certains d'entre eux ne font que faire surface lorsque nous exécutons deux instances de l'instance de la application au même moment.
Tutoriels Linux connexes:
- Ubuntu 20.04 Installation de PostgreSQL
- Ubuntu 22.04 Installation de PostgreSQL
- Comment empêcher la vérification de la connectivité NetworkManager
- Choses à installer sur Ubuntu 20.04
- Comment travailler avec l'API WooCommerce REST avec Python
- Comment vérifier la durée de vie de la batterie sur Ubuntu
- EEPROM CH341A Programmer - Lisez et écrivez des données à Chip sur…
- Choses à installer sur Ubuntu 22.04
- Installation d'Oracle Java sur Ubuntu 20.04 Focal Fossa Linux
- Comment installer Java sur Manjaro Linux