

Installez le cluster hadoop multinode à l'aide de CDH4 dans RHEL / CentOS 6.5

- 4851
- 1237
- Mohamed Brunet
Hadoop est un cadre de programmation open source développé par Apache pour traiter les mégadonnées. Il utilise HDFS (Système de fichiers distribué Hadoop) pour stocker les données sur tous les datanodes du cluster de manière distributive et le modèle MapReduce pour traiter les données.
 Installez le cluster hadoop multinode
Installez le cluster hadoop multinode Namenode (Nn) est un maître démon qui contrôle HDFS et Jobracker (Jt) est maître démon pour le moteur MapReduce.
Exigences
Dans ce tutoriel, j'utilise deux Centos 6.3 VMS 'maître' et 'nœud'à savoir. (le maître et le nœud sont mes noms d'hôte). L'IP «Master» est 172.21.17.175 et le nœud ip est '172.21.17.188'. Les instructions suivantes fonctionnent également sur Rhel/ /Centos 6.X versions.
Sur le maître
[[Protégé par e-mail] ~] # nom d'hôte maître
[[e-mail protégé] ~] # ifconfig | grep 'Inet addr' | Head -1 INET addr:172.21.17.175 Bcast: 172.21.19.255 Masque: 255.255.252.0
Sur le nœud
[[Protégé par e-mail] ~] # nom d'hôte nœud
[[e-mail protégé] ~] # ifconfig | grep 'Inet addr' | Head -1 INET addr:172.21.17.188 Bcast: 172.21.19.255 Masque: 255.255.252.0
Assurez-vous d'abord que tous les hôtes de cluster sont là '/ etc / hôtes'Fichier (sur chaque nœud), si vous n'avez pas configuré DNS.
Sur le maître
[[Protégé par e-mail] ~] # Cat / etc / Hosts 172.21.17.175 Maître 172.21.17.188 nœud
Sur le nœud
[[Protégé par e-mail] ~] # Cat / etc / Hosts 172.21.17.197 Qabox 172.21.17.176 anable
Installation du cluster Hadoop Multinode dans CentOS
Nous utilisons officiel CDH Référentiel à installer CDH4 sur tous les hôtes (maître et nœud) dans un cluster.
Étape 1: Télécharger Installer le référentiel CDH
Accédez à la page de téléchargement officielle du CDH et prenez le CDH4 (i.e. 4.6) version ou vous pouvez utiliser suivant wget commande pour télécharger le référentiel et l'installer.
Sur Rhel / Centos 32 bits
# wget http: // archive.cloudera.com / cdh4 / un clic-stall / redhat / 6 / i386 / cloudera-cdh-4-0.i386.RPM # yum --nogpgcheck localinstall Cloudera-CDH-4-0.i386.RPM
Sur rhel / centos 64 bits
# wget http: // archive.cloudera.com / cdh4 / un clic-stall / redhat / 6 / x86_64 / cloudera-cdh-4-0.x86_64.RPM # yum --nogpgcheck localinstall Cloudera-CDH-4-0.x86_64.RPM
Avant d'installer le cluster Hadoop Multinode, ajoutez la clé Cloudera publique GPG à votre référentiel en exécutant l'une des commandes suivantes en fonction de votre architecture système.
## sur le système 32 bits ## # RPM --Import http: // archive.cloudera.com / cdh4 / redhat / 6 / i386 / cdh / rpm-gpg-key-cloudera
## sur le système 64 bits ## # RPM --Import http: // archive.cloudera.com / cdh4 / redhat / 6 / x86_64 / cdh / rpm-gpg-key-cloudera
Étape 2: Configuration de Jobtracker & NameNode
Ensuite, exécutez la commande suivante pour installer et configurer Jobtracker et NameNode sur Master Server.
[[Email Protected] ~] # Yum Clean All [[Protégé par e-mail] ~] # yum install hadoop-0.20 mapreduce-jobtracker
[[Protégé par e-mail] ~] # yum Clean all [[e-mail protégé] ~] # yum install hadoop-hdfs-namenode
Étape 3: Configuration du nœud de nom secondaire
Encore une fois, exécutez les commandes suivantes sur le serveur maître pour configurer le nœud de nom secondaire.
[[Protégé par e-mail] ~] # yum Clean all [[Protégé par e-mail] ~] # yum install hadoop-hdfs-secondarynam
Étape 4: Configuration de TaskTracker et Datanode
Ensuite, configurez TaskTracker et Datanode sur tous les hôtes de cluster (nœud) à l'exception des hôtes NameNode de JobTracker, NameNode et secondaire (ou en standby) (sur le nœud) dans ce cas).
[[Email Protected] ~] # Yum Clean All [[Protégé par e-mail] ~] # yum install hadoop-0.20 mapreduce-tasktracker hadoop-hdfs-datanode
Étape 5: Configuration du client Hadoop
Vous pouvez installer Hadoop Client sur une machine séparée (dans ce cas, je l'ai installé sur Datanode, vous pouvez l'installer sur n'importe quelle machine).
[[Protégé par e-mail] ~] # yum install hadoop-client
Étape 6: Déployez HDFS sur les nœuds
Maintenant, si nous avons fini avec les étapes ci-dessus, allons de l'avant pour déployer HDFS (à faire sur tous les nœuds).
Copiez la configuration par défaut vers / etc / hadoop répertoire (sur chaque nœud en cluster).
[[e-mail protégé] ~] # cp -r / etc / hadoop / confr.Dist / etc / Hadoop / Conf.my_cluster
[[e-mail protégé] ~] # cp -r / etc / hadoop / confr.Dist / etc / Hadoop / Conf.my_cluster
Utiliser alternatives Commande pour définir votre répertoire personnalisé, comme suit (sur chaque nœud en cluster).
[[e-mail protégé] ~] # Alternatives --verbose --install / etc / hadoop / conf hadoop-conf / etc / hadoop / confr.my_cluster 50 lecture / var / lib / alternatives / hadoop-conf [[e-mail protégé] ~] # alternatives --set hadoop-conf / etc / hadoop / confre.my_cluster
[[e-mail protégé] ~] # Alternatives --verbose --install / etc / hadoop / conf hadoop-conf / etc / hadoop / confr.my_cluster 50 lecture / var / lib / alternatives / hadoop-conf [[e-mail protégé] ~] # alternatives --set hadoop-conf / etc / hadoop / confre.my_cluster
Étape 7: Personnalisation des fichiers de configuration
Ouvert 'site de base.xml«Fichier et mise à jour»FS.defaultfs"Sur chaque nœud en cluster.
[[Email Protected] conf] # Cat / etc / Hadoop / conf / Core Site.xml
FS.defaultfs hdfs: // maître /
[[Email Protected] conf] # Cat / etc / Hadoop / conf / Core Site.xml
FS.defaultfs hdfs: // maître /
Prochaine mise à jour "DFS.autorisation.SuperUserGroup" dans site HDFS.xml sur chaque nœud en cluster.
[[Protégé par e-mail] conf] # cat / etc / hadoop / conf / hdfs-site.xml
DFS.nom.diron / var / lib / hadoop-hdfs / cache / hdfs / dfs / nom DFS.autorisation.SuperUserGroup Hadoop
[[Protégé par e-mail] conf] # cat / etc / hadoop / conf / hdfs-site.xml
DFS.nom.diron / var / lib / hadoop-hdfs / cache / hdfs / dfs / nom DFS.autorisation.SuperUserGroup Hadoop
Note: Veuillez vous assurer que la configuration ci-dessus est présente sur tous les nœuds (faire sur un nœud et exécuter SCP pour copier sur le reste des nœuds).
Étape 8: Configuration des répertoires de stockage locaux
Mettre à jour «DFS.nom.dir ou dfs.namenode.nom.dir ”dans 'hdfs-site.xml 'sur le namenode (sur maître et nœud). Veuillez modifier la valeur comme mis en évidence.
[[Protégé par e-mail] conf] # cat / etc / hadoop / conf / hdfs-site.xml
DFS.namenode.nom.diron fichier: /// data / 1 / dfs / nn, / nfsmount / dfs / nn
[[Protégé par e-mail] conf] # cat / etc / hadoop / conf / hdfs-site.xml
DFS.code de données.données.diron fichier: /// data / 1 / dfs / dn, / data / 2 / dfs / dn, / data / 3 / dfs / dn
Étape 9: Créez des répertoires et gérez les autorisations
Exécutez des commandes ci-dessous pour créer une structure de répertoire et gérer les autorisations utilisateur sur la machine NameNode (Master) et Datanode (Node).
[[Email Protected]] # MKDIR -P / DATA / 1 / DFS / NN / NFSMOUNT / DFS / NN [[Email Protected]] # CHMOD 700 / DATA / 1 / DFS / NN / NFSMOUNT / DFS / NN
[[Protégé par e-mail]] # MKDIR -P / DATA / 1 / DFS / DN / DATA / 2 / DFS / DN / DATA / 3 / DFS / DN / DATA / 4 / DFS / DN [[Email Protected]] # Chown -R HDFS: HDFS / DATA / 1 / DFS / NN / NFSMOUNT / DFS / NN / DATA / 1 / DFS / DN / DATA / 2 / DFS / DN / DATA / 3 / DFS / DN / DATA / 4 / DFS / DN
Formater le namenode (sur maître), en émettant la commande suivante.
[[e-mail protégé] conf] # sudo -u hdfs hdfs namenode -format
Étape 10: Configuration du namenode secondaire
Ajouter la propriété suivante au site HDFS.xml fichier et remplacer la valeur comme indiqué sur le maître.
DFS.namenode.Address HTTP 172.21.17.175: 50070 L'adresse et le port sur lesquels l'interface utilisateur Namenode écoutera.
Note: Dans notre valeur de cas, la valeur IP devrait être une adresse IP de Master VM.
Déployons maintenant MRV1 (Map-Reduce version 1). Ouvrir 'site mapred.xml'Fichier suivant les valeurs comme indiqué.
[[Protégé par e-mail] conf] # cp hdfs-site.Site XML Mapred.xml [[e-mail protégé] conf] # vi mapred site.XML [[Email Protected] conf] # Cat Mapred Site.xml
cartographier.emploi.Maître du tracker: 8021
Ensuite, copier 'site mapred.xml'Fichier à la machine de nœud en utilisant la commande SCP suivante.
[[Protégé par e-mail] conf] # SCP / etc / hadoop / conf / mapred site.Node XML: / etc / hadoop / conf / mapred site.XML 100% 200 0.2KB / s 00:00
Configurez maintenant les répertoires de stockage locaux à utiliser par les démons MRV1. Ouvert à nouveau 'site mapred.xml«Fixez et apportez des modifications comme indiqué ci-dessous pour chaque TaskTracker.
Mapred.local.dir â / data / 1 / mapred / local, / data / 2 / mapred / local, / data / 3 / mapred / local
Après avoir précisé ces répertoires dans le 'site mapred.xml'Fichier, vous devez créer les répertoires et leur attribuer les autorisations de fichier correctes sur chaque nœud de votre cluster.
Mkdir -p / data / 1 / mapred / local / data / 2 / mapred / local / data / 3 / mapred / local / data / 4 / mapred / local chown -r mapred: hadoop / data / 1 / mapred / local / local / données / 2 / mapred / local / data / 3 / mapred / local / data / 4 / mapred / local
Étape 10: Démarrez HDFS
Maintenant, exécutez la commande suivante pour démarrer HDFS sur chaque nœud du cluster.
[[e-mail protégé] conf] # pour x dans 'cd / etc / init.d ; ls hadoop-hdfs- * '; faire le service sudo $ x start; fait
[[e-mail protégé] conf] # pour x dans 'cd / etc / init.d ; ls hadoop-hdfs- * '; faire le service sudo $ x start; fait
Étape 11: Créez des répertoires HDFS / TMP et MapReduce / VAR
Il est nécessaire de créer / tmp avec des autorisations appropriées exactement comme mentionné ci-dessous.
[[e-mail protégé] conf] # sudo -u hdfs hadoop fs -mkdir / tmp [[e-mail protégé] conf] # sudo -u hdfs hadoop fs -chmod -r 1777 / tmp
[[e-mail protégé] conf] # sudo -u hdfs hadoop fs -mkdir -p / var / lib / hadoop-hdfs / cache / mapred / mapred / staging [[e-mail protégée] conf] # sudo -u hdfs hadoop fs -chmod 1777 / var / lib / hadoop-hdfs / cache / mapred / mapred / staging [[e-mail protégé] conf] # sudo -u hdfs hadoop fs -chown -r mapred / var / lib / hadoop-hdfs / cache / mapred
Vérifiez maintenant la structure du fichier HDFS.
[[e-mail protégé] Ode conf] # sudo -u hdfs hadoop fs -ls -r / drwxrwxrwt - hdfs hadoop 0 2014-05-29 09:58 / tmp drwxr-xr-x - hdfs hadoop 0 2014-05-29 09 : 59 / var drwxr-xr-x - hdfs hadoop 0 2014-05-29 09:59 / var / lib drwxr-xr-x - hdfs hadoop 0 2014-05-29 09:59 / var / lib / hadoop-hdfs drwxr-xr-x - hdfs hadoop 0 2014-05-29 09:59 / var / lib / hadoop-hdfs / cache drwxr-xr-x - Mapred hadoop 0 2014-05-29 09:59 / var / lib / hadoop -HDFS / CACHE / MAPRED DRWXR-XR-X - Mapred Hadoop 0 2014-05-29 09:59 / var / lib / hadoop-hdfs / cache / mapred / mapred drwxrwxrwt - Mapred Hadoop 0 2014-05-29 09:59 / var / lib / hadoop-hdfs / cache / mapred / mapred / staging
Après avoir démarré HDFS et créé '/ tmp', mais avant de démarrer le Jobtracker, veuillez créer le répertoire HDFS spécifié par le' Mapred.système.Dir 'Paramètre (par défaut $ Hadoop.TMP.dir / mapred / système et changer le propriétaire en mapred.
[[e-mail protégé] conf] # sudo -u hdfs hadoop fs -mkdir / tmp / mapred / système [[e-mail protégé] conf] # sudo -u hdfs hadoop fs -chown mapred: hadoop / tmp / mapred / système
Étape 12: Démarrez MapReduce
Pour démarrer MapReduce: veuillez démarrer les services TT et JT.
Sur chaque système TaskTracker
[[Protégé par e-mail] conf] # Service Hadoop-0.20-MAPREDUCE-TASKTRACKER Commencer le démarrage de TaskTracker: [OK] Démarrer TaskTracker, journalisation vers / var / log / hadoop-0.20 mapreduce / hadoop-hadoop-tasktracker-node.dehors
Sur le système Jobtracker
[[Protégé par e-mail] conf] # Service Hadoop-0.20-MAPREDUCE-JOBTRACKER Commencez à démarrer Jobtracker: [OK] Démarrage de JobTracker, Logging to / var / log / hadoop-0.20 mapreduce / Hadoop-Hadoop-Jobtracker-Master.dehors
Ensuite, créez un répertoire domestique pour chaque utilisateur Hadoop. Il est recommandé de le faire sur Namenode; Par exemple.
[[e-mail protégé] conf] # sudo -u hdfs hadoop fs -mkdirâ / user / [[e-mail protégé] conf] # sudo -u hdfs hadoop fs -chown / user /
Note: où est le nom d'utilisateur Linux de chaque utilisateur.
Alternativement, vous pourrez peut-être le répertoire de la maison comme suit.
[[e-mail protégé] conf] # sudo -u hdfs hadoop fs -mkdir / utilisateur / $ utilisateur [[e-mail protégé] conf] # sudo -u hdfs hadoop fs -chown $ user / user / $ utilisateur
Étape 13: Ouvrir JT, nn ui du navigateur
Ouvrez votre navigateur et tapez l'URL comme http: // ip_address_of_namenode: 50070 Pour accéder à Namenode.
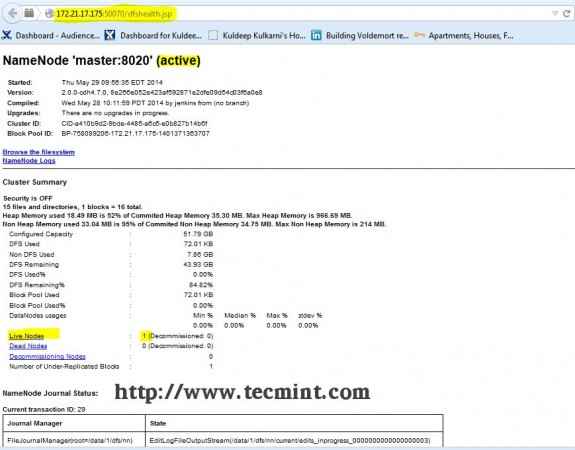 Interface hadoop namenode
Interface hadoop namenode Ouvrez un autre onglet dans votre navigateur et tapez l'URL comme http: // ip_address_of_jobtracker: 50030 Pour accéder à Jobtracker.
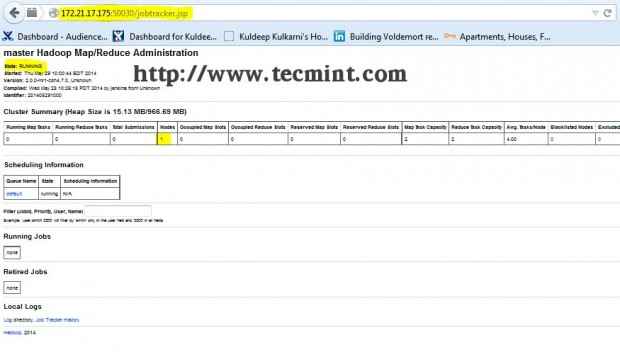 Hadoop Map / Réduction de l'administration
Hadoop Map / Réduction de l'administration Cette procédure a été testée avec succès sur Rhel / centos 5.X / 6.X. Veuillez commenter ci-dessous si vous rencontrez des problèmes avec l'installation, je vous aiderai avec les solutions.
- « Créez votre propre site Web de partage de vidéos à l'aide de 'CumulusClips Script' dans Linux
- Créer des hôtes virtuels, générer des certificats SSL et des clés et activer la passerelle CGI dans Gentoo Linux »