

Python Expressions régulières avec des exemples
- 3758
- 574
- Rayan Lefebvre
Une expression régulière (souvent abrégée à «Regex») est une technique, et un modèle textuel, qui définit comment on veut rechercher ou modifier une chaîne donnée. Les expressions régulières sont couramment utilisées dans les scripts Bash Shell et dans le code Python, ainsi que dans divers autres langages de programmation.
Dans ce tutoriel, vous apprendrez:
- Comment commencer avec des expressions régulières sur Python
- Comment importer le module regex python
- Comment faire correspondre les chaînes et les caractères en utilisant la notation regex
- Comment utiliser les notations regex les plus courantes
Python Expressions régulières avec des exemples Exigences et conventions logicielles utilisées
| Catégorie | Exigences, conventions ou version logicielle utilisée |
|---|---|
| Système | Tout système d'exploitation GNU / Linux |
| Logiciel | Python 2, Python 3 |
| Autre | Accès privilégié à votre système Linux en tant que racine ou via le Sudo commande. |
| Conventions | # - Exige que les commandes Linux soient exécutées avec des privilèges racine soit directement en tant qu'utilisateur racine, soit par l'utilisation de Sudo commande$ - Exige que les commandes Linux soient exécutées en tant qu'utilisateur non privilégié régulier |
Python Exemples d'expressions régulières
Dans Python, on veut importer le concernant module pour permettre l'utilisation d'expressions régulières.
Exemple 1 Commençons par un exemple simple:
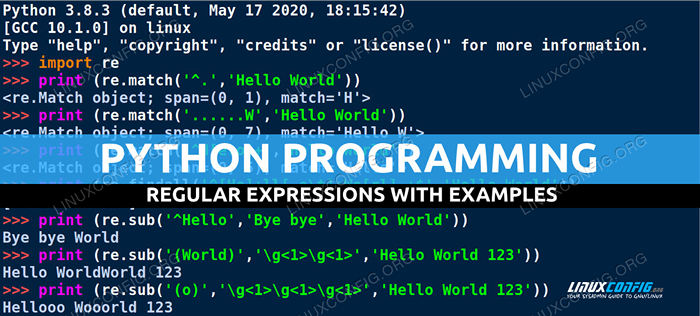
$ Python3 Python 3.8.2 (par défaut, 27 avril 2020, 15:53:34) [gcc 9.3.0] sur Linux Type "Help", "Copyright", "Crédits" ou "Licence" pour plus d'informations. >>> imprimer ('Hello World') Bonjour le monde >>> Import re >>> imprimer (re.match ('^.','Bonjour le monde')) Ici, nous avons d'abord imprimé Bonjour le monde Ligne 5 pour démontrer une configuration d'impression simple. Nous avons ensuite importé le module Regex concernant Ligne 7 et en nous utilisant l'utilisation du .correspondre Fonction de diffusion d'expression régulière de cette bibliothèque.
La syntaxe du .correspondre La fonction est (modèle, chaîne) où le motif était défini comme l'expression régulière ^.'Et nous avons utilisé la même chose Bonjour le monde chaîne comme notre chaîne d'entrée.
Comme vous pouvez le voir, un match a été trouvé dans la lettre H. La raison pour laquelle cette correspondance a été trouvée est le modèle de l'expression régulière, à savoir; ^ représente Démarrage de la chaîne et . représente faire correspondre un seul personnage (sauf Newline).
Ainsi, H a été trouvé, car cette lettre est directement après «le début de la chaîne», et est décrit comme «n'importe quel personnage, H dans ce cas".
Ces connotations spéciales sont identiques aux expressions régulières dans les scripts de bash et à d'autres applications réprimées, qui utilisent toutes une norme de regex uniforme plus ou moins, bien qu'il existe des différences entre les langues et même des implémentations spécifiques si vous plongez un peu dans les expressions régulières plus loin.
Exemple 2
>>> imprimer (re.Match ('… w', 'Hello World')) Nous utilisons ici . Pour correspondre à un seul personnage (sauf Newline) et nous le faisons 6 fois avant de faire correspondre le personnage littéral W.
Comme tu peux le voir Bonjour w (7 caractères) a été égalé. Fait intéressant, ce spectacle comme Span (0,7) qui ne doit pas être lu comme 0-7 (qui représente 8 caractères) mais comme "Démarrer à 0" "+7 caractères", comme cela peut également être jeté par les autres exemples de ce article.
Exemple 3 Prenons un autre exemple légèrement plus complexe:
>>> imprimer (re.match ('^ h [elo] +', 'Hello World')) La syntaxe dans ce cas est:
- ^: Comme décrit ci-dessus, peut également être lu comme «ce doit être le début de la chaîne»
- H: doit correspondre
HDans cet emplacement exact (qui est directement après / au début de la chaîne) - [Elo]+: Faites correspondre soit
e,louo(le «l'un ou l'autre» défini par[' et ']) et+signifie «un ou plusieurs d'entre eux»
Ainsi, Bonjour était assorti comme H était en effet au début de la chaîne, et e et o et l étaient assortis une ou plusieurs fois (dans n'importe quel ordre).
Exemple 3 pour un super complexe?
>>> imprimer (re.findall ('^ [he] + ll [o \ t] + wo [rl].+$ ',' Hello World ')) [' Hello World '];Ici, nous avons utilisé une autre fonction du module RE, à savoir Trouver tout qui donne immédiatement la chaîne trouvée et utilise la même syntaxe (modèle, chaîne).
Pourquoi Bonjour le monde match en totalité? Décomposons étape par étape:
- ^: Début de la chaîne
- [Il]+: Allumettes
Hete1 fois ou plus, et doncIlest assorti - ll: correspondance littérale de
llà cet endroit exact, et donc en effetllest assorti comme il est venu directement aprèsIl - [o \ t]+: Faites correspondre soit
"(espace), ouo, ou\ t(un onglet), et que 1 ou plus, et donco(O Space) correspondant. Si nous avions utilisé un onglet au lieu d'un espace, ce regex fonctionnerait toujours! - Wo: Match littéral de
Wo - [RL]: Faites correspondre soit
roul. Regarde attentivement; seulrest assorti ici! Il n'y a pas+derrière la]]donc un seul caractère, soitroulsera apparié dans cette position. Alors pourquoi étaitRLDtoujours assorti? La réponse est dans le prochain qualificatif; - .+: Faites correspondre tout caractère (signifié par
.) une ou plusieurs fois, doncletdsont tous les deux assortis, et notre chaîne est complète - $: Semblable à
^, Ce personnage signifie «fin de chaîne».
En d'autres termes, avions-nous placé cela au début, ou ailleurs au milieu, le Regex aurait inquiet.
Par exemple:
>>> imprimer (re.findall ('^ hello $', 'bonjour world')) [] >>> imprimer (re.findall ('^ bonjour $', 'bonjour')) [] >>> imprimer (re.findall ('^ Hello $', 'bonjour')) ['bonjour'] >>> imprimer (re.Findall ('^ Hello', 'Hello World')) ['Hello']Ici, aucune sortie n'est renvoyée pour les deux premières impressions, car nous essayons de faire correspondre une chaîne qui peut être lue comme "start_of_string"-Bonjour-"End_of_string" comme signifié par ^ Bonjour $, contre Bonjour le monde qui ne correspond pas.
Dans le troisième exemple, le ^ Bonjour $ allumettes Bonjour car il n'y a pas de personnages supplémentaires dans le Bonjour chaîne qui ferait que ce regex échouerait. Enfin, le dernier exemple montre une correspondance partielle sans l'exigence que le «end_of_string» ($) se produise.
Voir? Vous devenez déjà un expert des expressions régulières! Les expressions régulières peuvent être amusantes et sont très puissantes!
Exemple 4
Il existe diverses autres fonctions dans le concernant Module python, comme concernant.sous, concernant.diviser, concernant.subn, concernant.recherche, chacun avec ses domaines de cas d'utilisation applicables. Regardons RE.sous Suivant:
>>> imprimer (re.sub ('^ bonjour', 'bye bye', 'Hello world')) bye bye worldLa substitution de cordes est l'une des applications les plus puissantes des expressions régulières, en python et autres langues codantes. Dans cet exemple, nous avons cherché ^ Bonjour et l'a remplacé par Bye Bye dans la chaîne Bonjour le monde. Pouvez-vous voir comment cela serait très pratique pour traiter toutes sortes de variables et de chaînes de texte et même des fichiers de texte plats entiers?
Exemple 5
Regardons quelques exemples plus complexes, en utilisant une syntaxe regex plus avancée:
>>> imprimer (re.sub ('[0-9] +', '_', 'Hello World 123')) Bonjour le monde _- [0-9]+: Tout caractère numérique de
0pour9, une ou plusieurs fois.
Pouvez-vous voir comment le 123 a été remplacé par un seul _ ?
Exemple 6
>>> imprimer (re.sous('(?i) [O-R] + ',' _ ',' Hello World 123 ')) Hell_ W_LD 123- (?i) [O-R]+: Faire correspondre un ou plusieurs
OpourRou - grâce à la facultationjedrapeau -opourr - (?je): préréglage
jedrapeau pour ce modèle
>>> imprimer (re.sub ('[1] 2', '_', 'Hello World 111')) Bonjour le monde _1- [1] 2: Faites correspondre le personnage
1Exactement deux fois
Exemple 7
>>> imprimer (re.sub ('(world)', '\ g \ g', 'Hello World 123')) Bonjour Worldworld 123- (Monde): Faites correspondre le texte littéral «monde» et faites-en un groupe qui peut ensuite être utilisé dans la substitution
- \ g \ g: Le
\gSpécifie le premier groupe qui a été apparié, je.e. le texteMondepris duHello World 123chaîne, et ceci est répété deux fois, ce qui résulte duMonde du mondesortir. / li>
Exemple 8
Pour rendre cela plus clair, considérez les deux exemples suivants:
>>> imprimer (re.sub ('(o)', '\ g \ g \ g', 'Hello World 123')) helloo wooorld 123Dans ce premier exemple, nous correspondons simplement o et le placer dans un groupe, puis répéter ce groupe trois fois dans la sortie.
Notez que si nous ne référions pas au groupe 1 (le premier groupe correspondant, le deuxième exemple du deuxième exemple), il n'y aurait simplement pas de sortie et le résultat serait:
>>> imprimer (re.sub ('(o)', ", 'Hello World 123')) Hell Wrld 123Pour le deuxième exemple, considérez:
>>> imprimer (re.sub ('(o).* (r) ',' \ g \ g ',' Hello World 123 ')) Hellorld 123Ici, nous avons deux groupes, le premier étant o (partout où un tel groupe correspond, et il y a clairement multiple comme on le voit dans le premier exemple), et le second étant r. De plus, nous utilisons .* qui se traduit par «n'importe quel caractère, n'importe quel nombre de fois» - une expression régulière souvent utilisée.
Donc dans cet exemple O WOR est assorti par (o).* (r) '(' o D'abord, puis n'importe quel personnage jusqu'au dernier r est atteint. La notion «The Last» est très importante et facile à faire des erreurs / gotcha, en particulier pour les nouveaux utilisateurs d'expressions régulières. À titre d'exemple latéral, considérons:
>>> imprimer (re.sub ('e.* o ',' _ ',' Hello World 123 ')) h_rld 123Pouvez-vous voir comment le dernier o était assorti?
Retour à notre exemple:
>>> imprimer (re.sub ('(o).* (r) ',' \ g \ g ',' Hello World 123 ')) Hellorld 123On peut voir ça O WOR a été remplacé par un match du groupe 1 suivi d'un match du groupe 2, ce qui a donné:: O WOR être remplacé par ou Et donc la sortie est Hellorld 123.
Conclusion
Examinons certaines des notations d'expressions régulières les plus courantes disponibles dans Python, assorties à certaines implémentations légères de la même chose:
| Notation regex | Description |
|---|---|
. | Tout personnage, sauf Newline |
[A-C] | Un caractère de la gamme sélectionnée, dans ce cas A, B, C |
[A-Z] | Un caractère de la gamme sélectionnée, dans ce cas A-Z |
[0-9af-z] | Un caractère de la gamme sélectionnée, dans ce cas 0-9, A et F-Z |
[^ A-za-z] | Un caractère en dehors de la gamme sélectionnée, dans ce cas, par exemple «1» |
* | N'importe quel nombre de matchs (0 ou plus) |
+ | 1 ou plusieurs matchs |
? | 0 ou 1 match |
3 | Exactement 3 matchs |
() | Groupe de capture. La première fois que cela est utilisé, le numéro de groupe est 1, etc. |
\g | Utiliser (insérer) du groupe de matchs de capture, qualifié par le nombre (1-x) du groupe |
\g | Le groupe spécial 0 insère toute la chaîne correspondante |
^ | Démarrage de la chaîne |
$ | Fin de chaîne |
\d | Un chiffre |
\D | Un non-chiffre |
\ s | Un espace blanc |
\ S | Un non-blanc |
(?je) | Ignorer le préfixe du drapeau de cas, comme démontré ci-dessus |
A | D | Un personnage sur les deux (une alternative à l'utilisation de []), 'A' ou 'D' |
\ | Échappe des caractères spéciaux |
\ b | Caractère arrière |
\ n | Personnage de Newline |
\ r | Caractère de retour |
\ t | Caractère d'onglet |
Intéressant? Une fois que vous commencez à utiliser des expressions régulières, dans n'importe quelle langue, vous constaterez bientôt que vous commencez à les utiliser partout - dans d'autres langages de codage, dans votre éditeur de texte préféré de Regex, sur la ligne de commande (voir 'SED' pour les utilisateurs de Linux), etc.
Vous constaterez probablement également que vous commencerez à les utiliser plus d'ad-hoc, je.e. pas seulement dans le codage. Il y a quelque chose de intrinsèquement puissant pour pouvoir contrôler toutes sortes de sorties de ligne de commande, par exemple le répertoire et les listes de fichiers, les scripts et la gestion de texte de fichier plat.
Profitez de vos progrès d'apprentissage et publiez certains de vos exemples d'expression régulière les plus puissants ci-dessous!
Tutoriels Linux connexes:
- Advanced Bash Regex avec des exemples
- Bash regexps pour les débutants avec des exemples
- Masterring Bash Script Loops
- Une introduction à l'automatisation Linux, des outils et des techniques
- Choses à installer sur Ubuntu 20.04
- Boucles imbriquées dans les scripts bash
- Manipulation des mégadonnées pour le plaisir et le profit Partie 3
- Gestion de la saisie des utilisateurs dans les scripts bash
- Créer des règles de redirection et de réécriture en .htaccess sur Apache…
- Mint 20: Mieux que Ubuntu et Microsoft Windows?
- « Comment installer des codecs et des extras tiers sur Manjaro Linux
- Comment installer un package à partir d'AUR sur Manjaro Linux »