

Meilleures pratiques pour le déploiement du serveur Hadoop sur Centos / Rhel 7 - Partie 1

- 2129
- 195
- Rayan Lefebvre
Dans cette série d'articles, nous allons couvrir l'ensemble Cloudera Hadoop Cluster Building construire avec Fournisseur et Industriel meilleures pratiques recommandées.
Partie 1: Meilleures pratiques pour le déploiement du serveur Hadoop sur Centos / Rhel 7 Partie 2: Configuration de Hadoop Pre-Requisites et du durcissement de la sécurité Partie 3: Comment installer et configurer le gestionnaire de Cloudera sur Centos / Rhel 7 Partie 4: Comment installer CDH et configurer des placements de service sur Centos / Rhel 7 Partie 5: Comment configurer la haute disponibilité pour Namenode Partie 6: Comment configurer une haute disponibilité pour le gestionnaire de ressources Partie 7: Comment installer et configurer la ruche avec une haute disponibilité Partie 8: Comment installer et configurer la sentinelle (outil d'autorisation) Partie 9: Comment installer Kerberos (Kerbering the Cluster) pour l'authentification Hadoop Partie 10: Comment régler le cluster (réglage du fil) sur Centos / Rhel 7OS installation et faire OS Les pré-réquisites de niveau sont les premières étapes pour construire un Cluster Hadoop. Hadoop Peut fonctionner sur les différentes saveurs de la plate-forme Linux: Centos, Chapeau rouge, Ubuntu, Debian, Suser etc., En production en temps réel, la plupart des Clusters Hadoop sont construits au-dessus de Rhel / centos, nous utiliserons Centos 7 pour une démonstration dans cette série de tutoriels.
Dans une organisation, l'installation du système d'exploitation peut être effectuée lancer un coup d'envoi. S'il s'agit d'un cluster de 3 à 4 nœuds, une installation manuelle est possible, mais si nous construisons un grand cluster avec plus de 10 nœuds, il est fastidieux d'installer OS un par un. Dans ce scénario, la méthode Kickstart entre dans l'image, nous pouvons procéder à l'installation de masse en utilisant Kickstart.
Réaliser de bonnes performances à partir d'un Environnement Hadoop dépend de l'approvisionnement du matériel et des logiciels corrects. Donc, construire une production Cluster Hadoop implique beaucoup de considération concernant le matériel et les logiciels.
Dans cet article, nous allons passer par divers repères sur l'installation du système d'exploitation et quelques meilleures pratiques pour le déploiement Serveur de cluster Cloudera Hadoop sur Centos / Rhel 7.
Considération importante et meilleures pratiques pour le déploiement du serveur Hadoop
Voici les meilleures pratiques pour la mise en place du déploiement Serveur de cluster Cloudera Hadoop sur Centos / Rhel 7.
- Les serveurs Hadoop ne nécessitent pas que les serveurs standard d'entreprise construisent un cluster, il nécessite du matériel de marchandise.
- Dans le cluster de production, avec 8 à 12 disques de données sont recommandés. Selon la nature de la charge de travail, nous devons décider de cela. Si le cluster est destiné aux applications à forte intensité de calcul, avoir 4 à 6 disques est la meilleure pratique pour éviter les problèmes d'E / S.
- Les lecteurs de données doivent être partitionnés individuellement, par exemple - à partir de / data01 pour / data10.
- La configuration de RAID n'est pas recommandée pour les nœuds de travailleur, car Hadoop lui-même fournissant une tolérance aux pannes sur les données en reproduisant les blocs en 3 par défaut. Donc Jbod est le meilleur pour les nœuds de travailleurs.
- Pour les serveurs maîtres, Raid 1 est la meilleure pratique.
- Le système de fichiers par défaut sur Centos / Rhel 7.X est XFS. Hadoop prend en charge XFS, EXT3 et EXT4. Le système de fichiers recommandé est Ext3 car il est testé pour de bonnes performances.
- Tous les serveurs devraient avoir la même version du système d'exploitation, au moins la même version mineure.
- Il est de la meilleure pratique d'avoir du matériel homogène (tous les nœuds de travailleur doivent avoir les mêmes caractéristiques matérielles (RAM, espace disque et noyau, etc.).
- Selon la charge de travail en cluster (charge de travail équilibrée, le calcul intensif, les E / S intensive) et la taille, la planification des ressources (RAM, CPU) par serveur obtiendra.
Trouvez l'exemple ci-dessous pour le partitionnement du disque des serveurs de stockage de 24 To.
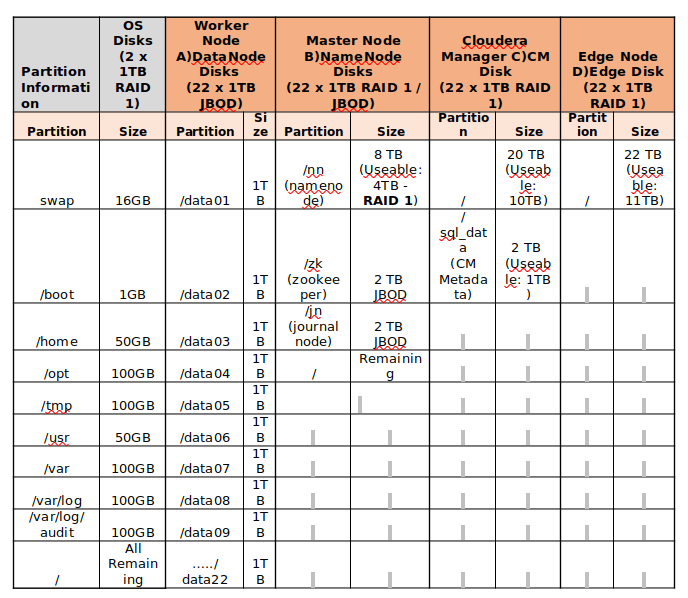 Partitionnement de disque
Partitionnement de disque Installation de Centos 7 pour le déploiement du serveur Hadoop
Des choses que vous devez savoir avant d'installer Centos 7 serveur pour Serveur Hadoop.
- L'installation minimale suffit pour Serveurs Hadoop (nœuds de travailleur), dans certains cas, l'interface graphique ne peut être installée que pour les serveurs maîtres ou les serveurs de gestion où nous pouvons utiliser des navigateurs pour les internes Web d'outils de gestion.
- La configuration des réseaux, du nom d'hôte et d'autres paramètres liés au système d'exploitation peuvent être effectués après l'installation du système d'exploitation.
- En temps réel, les fournisseurs de serveurs disposeront de leur propre console pour interagir et gérer les serveurs, par exemple - les serveurs Dell ont IDRAC qui est un appareil, intégré à des serveurs. En utilisant cette interface IDRAC, nous pouvons installer le système d'exploitation avec une image de système d'exploitation dans notre système local.
Dans cet article, nous avons installé le système d'exploitation (Centos 7) dans VMware Virtual Machine. Ici, nous n'aurons pas plusieurs disques pour effectuer des partitions. Centos est similaire à Rhel (même fonctionnalité), nous verrons donc les étapes à installer Centos.
1. Commencez par télécharger le Centos 7.Image X ISO dans votre système Windows local et sélectionnez-le tout en démarrant la machine virtuelle. Sélectionner 'Installer Centos 7' comme montré.
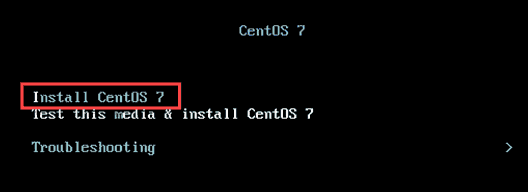 Installer le menu de démarrage Centos 7
Installer le menu de démarrage Centos 7 2. Sélectionnez le Langue, la valeur par défaut sera Anglais, et cliquer continuer.
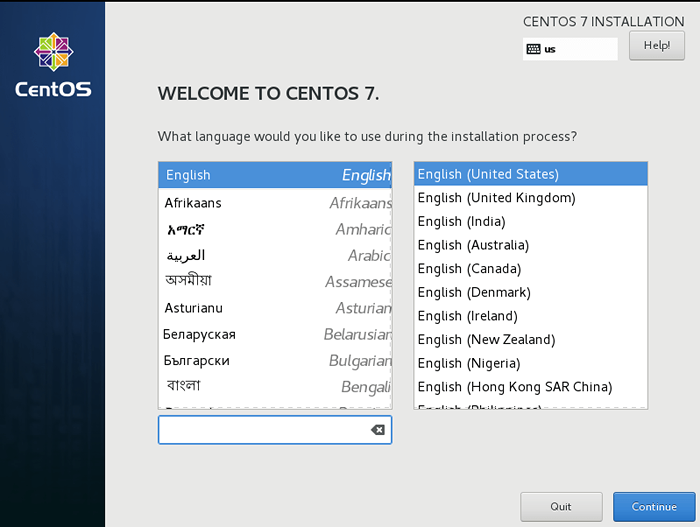 Sélectionnez la langue Centos 7
Sélectionnez la langue Centos 7 3. Sélection de logiciels - Sélectionnez le 'Installation minimale'et cliquez'Fait'.
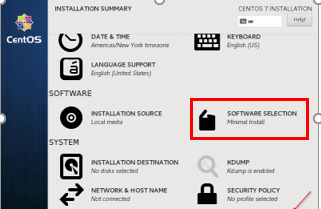 Sélection du logiciel CentOS
Sélection du logiciel CentOS 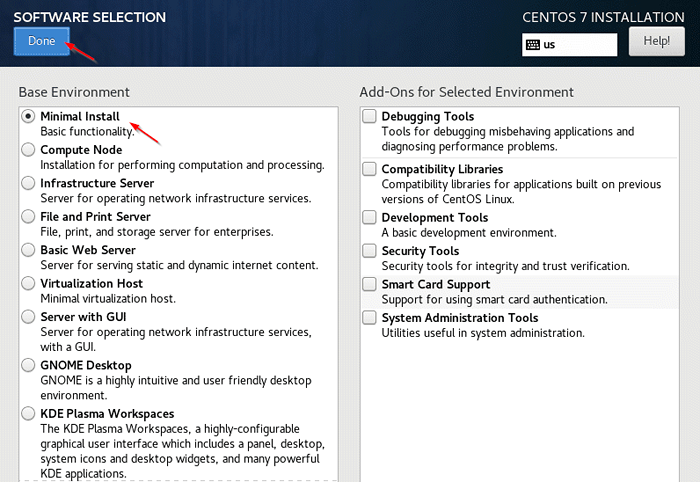 Centos 7 Installation minimale
Centos 7 Installation minimale 4. Met le mot de passe racine car cela nous incitera à régler.
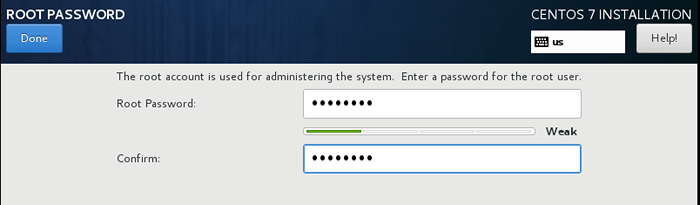 Définir le mot de passe
Définir le mot de passe 5. Destination d'installation - C'est l'étape importante pour être prudent. Nous devons sélectionner le disque où le système d'exploitation doit être installé, le disque dédié doit être sélectionné pour le système d'exploitation. Clique le 'Destination d'installation'Et sélectionnez le disque, sur plusieurs disques en temps réel sera là, nous devons sélectionner, préférable' 'SDA'.
 Sélectionnez la destination d'installation
Sélectionnez la destination d'installation 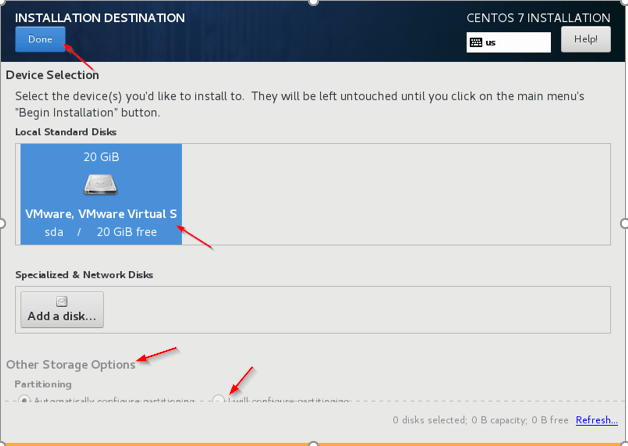 Sélectionnez un disque pour l'installation de CentOS
Sélectionnez un disque pour l'installation de CentOS 6. Autres options de stockage - Choisissez la deuxième option (je configurerai le partitionnement) pour configurer le partitionnement lié au système d'exploitation comme / var, / var / log, /maison, / tmp, /opter, /échanger.
 Partitionnement manuel de CentOS
Partitionnement manuel de CentOS 7. Une fois terminé, commencez l'installation.
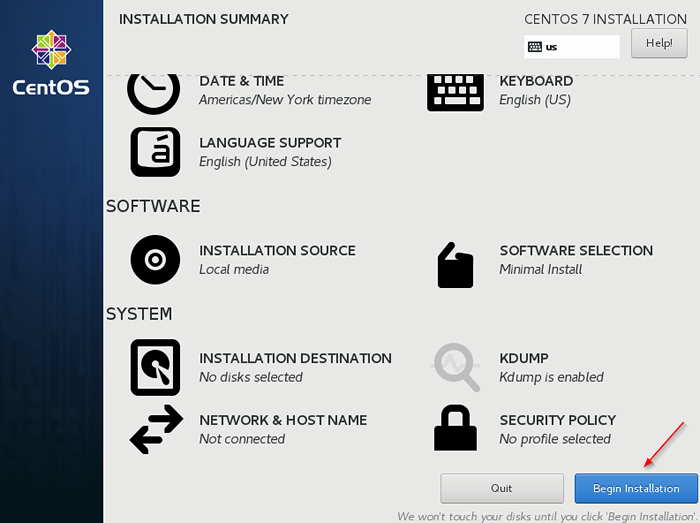 Début de l'installation de CentOS
Début de l'installation de CentOS  Installation de Centos 7
Installation de Centos 7 8. Une fois l'installation terminée, redémarrez le serveur.
 Installation de Centos 7 complète
Installation de Centos 7 complète 9. Connectez-vous dans le serveur et définissez le nom d'hôte.
# statut hostNamectl # hostNamectl set-hostname tecmint # statut hostNamectl
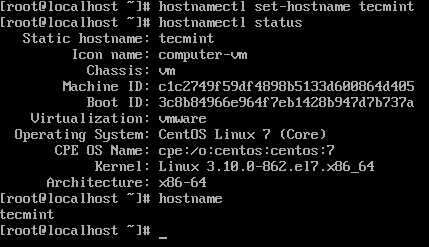 Définir le nom d'hôte sur CentOS
Définir le nom d'hôte sur CentOS Résumé
Dans cet article, nous avons parcouru les étapes d'installation du système d'exploitation et les meilleures pratiques pour le partitionnement du système de fichiers. Ce sont toutes des lignes directrices générales, selon la nature de la charge de travail, nous devrons peut-être nous concentrer sur plus de nuances pour atteindre les meilleures performances du cluster. La planification des grappes est l'art pour le Hadoop administrateur. Nous allons plonger profondément dans le niveau de système d'exploitation pré-requis et le durcissement de la sécurité dans le prochain article.
- « Comment diviser l'écran VIM horizontalement et verticalement dans Linux
- 10 meilleures passerelles API open source et outils de gestion »